
Concurrency Deep Dive: Code Strategies for High Traffic Applications
If you are a developer who is building a client/server application, then you are probably interested in building a server architecture that can handle high traffic from a large number of concurrent users. In a previous article I compared how concurrency and scaling are handled across AWS Lambda, AWS App Runner, and AWS Fargate.
In this article I am going to dive a bit deeper into concurrency, and use some examples to explain concurrency strategies that you can utilize for serving high traffic. These strategies allow you to take maximum advantage of your concurrency when running an application on AWS App Runner, AWS Fargate, or any other compute that supports a single application process handling multiple concurrent requests at a time.
Concurrency Basics: Event Loops and Concurrent Code
At the root of optimizing for high traffic is the concept that a single server side application process can be serving many clients simultaneously. To explain how this is possible, let’s consider what the server side application process is doing. Most server side applications are receiving HTTP requests, doing some processing in response to the HTTP request, and then returning a response to the client.
The lifecycle of a single HTTP request may look something like this:

- The server process receives a JSON payload from an HTTP POST request and validates the incoming data
- Then server process does a SQL query to insert a row into the database, to store this data it received in the payload
- The server process must now wait for a response from the database to see if the insert was successful
- Next the server process calls to another downstream service, perhaps to tell another service that a new object has been stored in the database
- The server process needs to wait on the results of that call to see if it was successful
- Finally the server process responds to the HTTP request with a 200 OK status code.
End to end the entire process takes about 120ms in this case. However if you look carefully at how that 120ms is being spent you can quickly realize that the vast majority of that time is not spent on CPU instructions. Instead it is just spent waiting on network I/O.

Out of that 120ms only 10ms of that time is actually spent on running your code. The rest of the time is just spent waiting. That seems a bit wasteful.
What if instead the application did this:
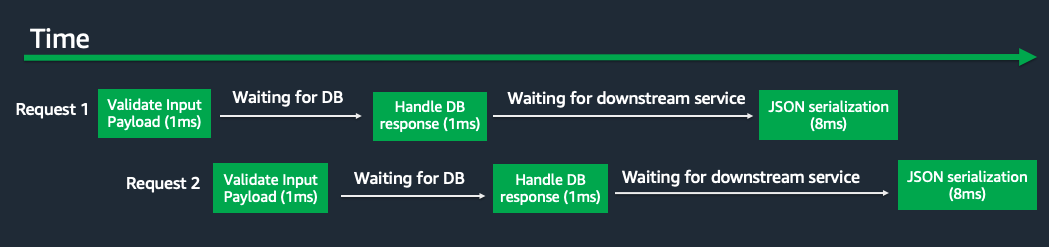
Each time the application reaches a point where it is waiting on a network I/O operation, it instead grabs another incoming HTTP request and starts working on it. The code instructions get run in a staggered manner, allowing the application process to work on multiple incoming requests at a time.
Most modern application programming languages have a built-in event loop that is capable of implementing this exact flow. The event loop is just an endless loop that checks for events to respond to. These events could be something like “an HTTP request was sent to the server” or “a response came back from the database” or “the file finished saving to disk”. If an event arrives while other code is running it queues up.
But whenever a block of code finishes running the event loop can pick up another event off the queue and start executing a block of code in response to that event. This allows the event loop to keep the process busy, constantly accepting events from multiple clients at a time and running code to handle the event.

You can think of the event loop as an in process work scheduler. It has lots of small chunks of code to run. Each small chunk of code may take only a millisecond or less. But there are 1000ms each second which can be used for running code. The event loop scheduler can grab events and fill up each of those 1000ms with code to run.
Practical Code Examples: JavaScript & Node.js
Here is a practical example of what concurrent, event loop code can look like in JavaScript / Node.js:
exports.handler = function (event, context, callback) {
console.log('In the present');
setTimeout(100, function() {
console.log('Time travel to 100ms later');
callback();
});
}
This code has two function blocks. The top level handler is one block. But there is another function block which is configured to be run 100ms later. The event loop runs the top level block quickly, but now it is just waiting 100ms before the next block can be run. Instead of doing nothing, the event loop can be doing other things in that 100ms gap.
Here is another practical example, with a more modern async function:
exports.handler = async function (event, context, callback) {
// Validate the event
let dbResponse = await db.insert(); // Wait for IO from DB
// Handle DB response
let downstreamResponse = await downstreamService.put();
// Serialize a JSON response
}
This function actually has three code blocks in it. Each time the await keyword is encountered
it tells the event loop “I want to pause running the code in this function until a response comes back from
this function call”. This is called “yielding” back to the event loop, because it allows the event
loop to start doing other work during the wait, such as picking up another incoming request.
When the event that was being awaited happens (a database query completes, or a call to the downstream service completes) then the event loop resumes running the next section of code from the function.
Concurrency Magic: Fetch Deduping
Once you have written code that can work on multiple asynchronous things at a time you can begin to benefit from some pretty amazing optimizations that take advantage of this concurrency.
One technique that I particularly like is fetch deduping. To explain how this works consider the following request lifecycle. This is pretty representative of what many REST API’s are doing:
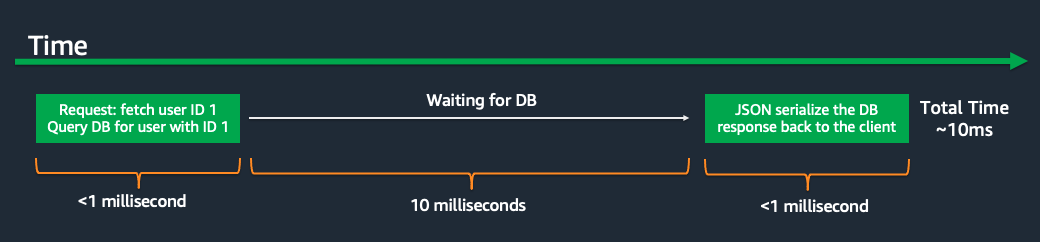
- A client sends a GET request for the details of the user account with ID 1.
- The server side process dispatches a SQL query to get those details out of the database.
- Roughly 10ms later the response comes back from the database.
- The application server serializes this response into JSON to send back in the HTTP response.
This type of flow is extremely common for client/server applications. But now lets imagine a scenario where another request arrives for the same object, while the first request is still waiting on the SQL query:
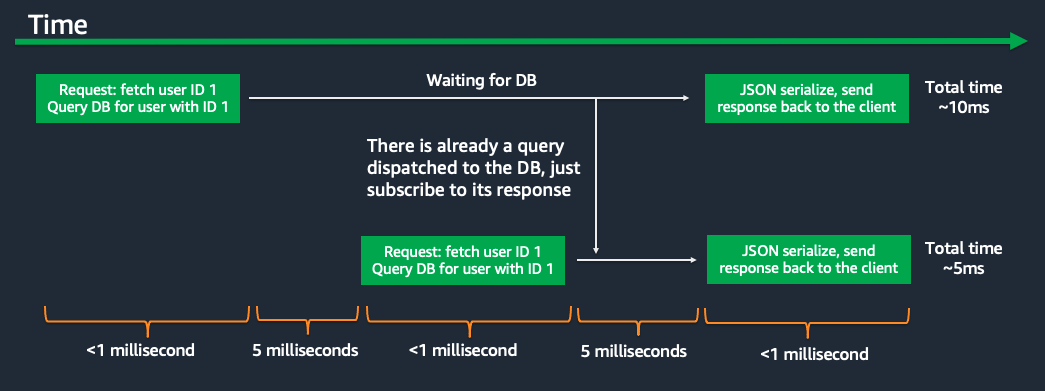
- A client sends a GET request for the details of the user account with ID 1.
- The server side process dispatches a SQL query to get those details out of the database.
- About 5ms later the response to the SQL query has not yet come back, but a second client request for the same user object arrives.
- Instead of dispatching a second identical SQL query, the server sees that it already has an in-flight SQL query and just subscribes this second request to the response from the first SQL query.
- Both HTTP requests are answered using the same data from the same SQL query.
From the perspective of the clients who made these requests the first request had 10ms of server side latency while the second request only had 5ms of server side latency because it was able to be answered using a SQL query that had already been in flight for 5ms.
This strategy works especially well for applications that have “hot” data, such as a viral aspect that causes many clients to fetch the same data at the same time. Not only can you reduce the load on your database, but you can also reduce the perceived latency dramatically. In many cases a single query can serve multiple identical requests. The one downside is that some requests will be served using past data. You would not want to use this strategy for something like fetching the current value of a bank account, or any application that requires strong consistency.
You can also take advantage of a CDN in front of your API to help dedupe fetches at the HTTP request level. However there will still be cases where multiple identical requests slip through. For example your CDN probably has many edge locations and each edge location must fetch the data from your origin application server. Or perhaps there are many different concurrent requests that are all fetching the same underlying data. For example, someone with many followers on Twitter sends a tweet and one million different people fetch their personal Twitter timelines which contain that same tweet. In both cases fetch deduping serves as an extra layer of optimization that makes your service faster and reduces load on the underlying data layer.
Concurrency Magic: Write Batching
Another place that you can take advantage of server side concurrency is on the write side. Consider the following typical server side request lifecycle:

- A client makes a POST or PUT request with a JSON payload to save.
- The server application parses the JSON payload and sends a SQL update query to save the data into the database.
- The database responds to acknowledge that the SQL query has completed.
- The server application responds back to the client with a 200 OK status code to show that the request was successful.
Now consider this alternate flow which takes advantage of the server side concurrency:
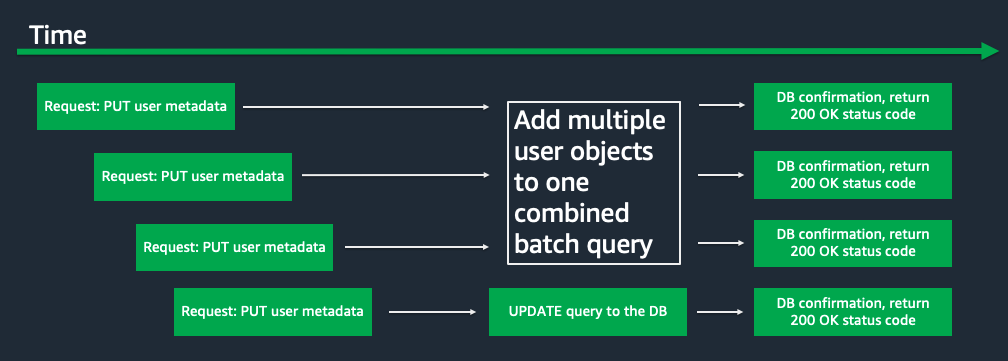
- A client makes a POST or PUT request with a JSON payload to save.
- Instead of immediately dispatching a SQL query the server starts a waiting period. In this case maybe it waits 10ms.
- During that 10ms period more POST and PUT requests arrive at the server.
- The server dispatches one bulk query to the database, either when the 10ms time period is up, or when a “batch” fills up with enough objects.
- When the bulk query completes successfully all the requests get 200 OK responses sent back.
This strategy causes write operations to appear to take a little bit longer, however it causes much less load on the server application and on the database. There are a few reasons for this including:
- In most configurations a TCP packet can store up to 64K. It is more efficient to send multiple updates and upserts in a single larger TCP packet than to send several smaller TCP packets.
- It is more efficient to serialize and deserialize batches of data (on both the server and the database side).
- When the database needs to persist the data onto a storage medium (spinning disk hard drive or solid state drive) it is more efficient to do one larger flush to durable storage.
This strategy actually gets better and better the more concurrency you have to your server application. There are two main knobs to tune:
- Batch size - How many objects can accumulate max before it triggers a batch query to be dispatched immediately.
- Batch delay - How long to wait for more items to arrive before a batch gets dispatched anyway, even if it isn’t full yet. Lower batch delay causes batches to be dispatched faster. Higher batch delay allows more items to be accumulated into a batch.
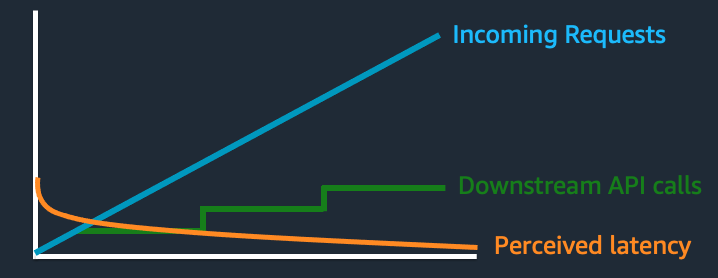
As the volume of incoming requests increases it actually causes batches to fill up faster and get dispatched faster as they reach the maximum batch size. As a result perceived latency decreases as the concurrency increases! As the concurrency rises the number of calls to the downstream database or service increases in a stair step pattern. If the batch size is 10 then the calls to the downstream service will increase at 1/10th of the rate of the overall incoming request volume.
Many databases and downstream services support batch calls. On AWS the following major services have batch endpoints you can utilize:
- Amazon DynamoDB -
BatchWriteItemandBatchGetItem - Amazon Simple Queue Service -
SendMessageBatch - Amazon Simple Notification Service -
PublishBatch
Conclusion
Writing code that can take advantage of concurrency can be a bit tricky, but when done right you end up with an application that can handle more traffic, more efficiently. It is much easier to write code in a compute environment like AWS Lambda where each request can be isolated from other requests. However, a single concurrency system prevents you from writing code that can utilize multiple concurrent requests efficiently. If you choose a serverless compute such as AWS App Runner or AWS Fargate then it allows for application side concurrency and you can build efficient patterns that can utilize concurrency.
If you have questions or comments please message @nathankpeck on LinkedIn.
Additionally if you haven’t read the first article in this series then please read: “Concurrency Compared: AWS Lambda, AWS App Runner, and AWS Fargate” for an in-depth analysis of how each serverless compute option on AWS handles concurrency.