
Designing a modern serverless application with AWS Lambda and AWS Fargate
Recently I built and open sourced a sample application called changelogs.md. The application watches for open source packages on NPM, RubyGems, and PyPI. When a package is added or updated it crawls any changelog found in the package source code. It constructs a human readable HTML version of the changelog and a machine readable JSON version. You can search for specific projects that have been crawled or watch a realtime stream of open source projects as they are crawled.

I created the first version of this application a few years back as a learning project to figure out how to use AWS Lambda effectively in my software architecture designs. Recently I decided to revisit that application and add new realtime features.
Let’s start with some of the lower level components of the application to see how they work. The first step is discovery, or how the application finds out when there is a new changelog to crawl.

There are two types of discovery: polling and push based. For RubyGems and PyPI the application must poll the public API for these registries periodically. It does this using a Lambda function setup to execute on a cron schedule.
NPM is a much higher throughput registry, so polling wouldn’t be as effective. Some packages might be missed during busy times of the day unless we polled very frequently, and this would mean the application would be spamming NPM with a lot of requests. Fortunately NPM provides a CouchDB interface that can push updates to our application whenever a package is published. I implemented a Docker container that subscribes to this CouchDB interface to get these realtime updates.
All discovered changelogs to crawl get published to a single SNS topic.
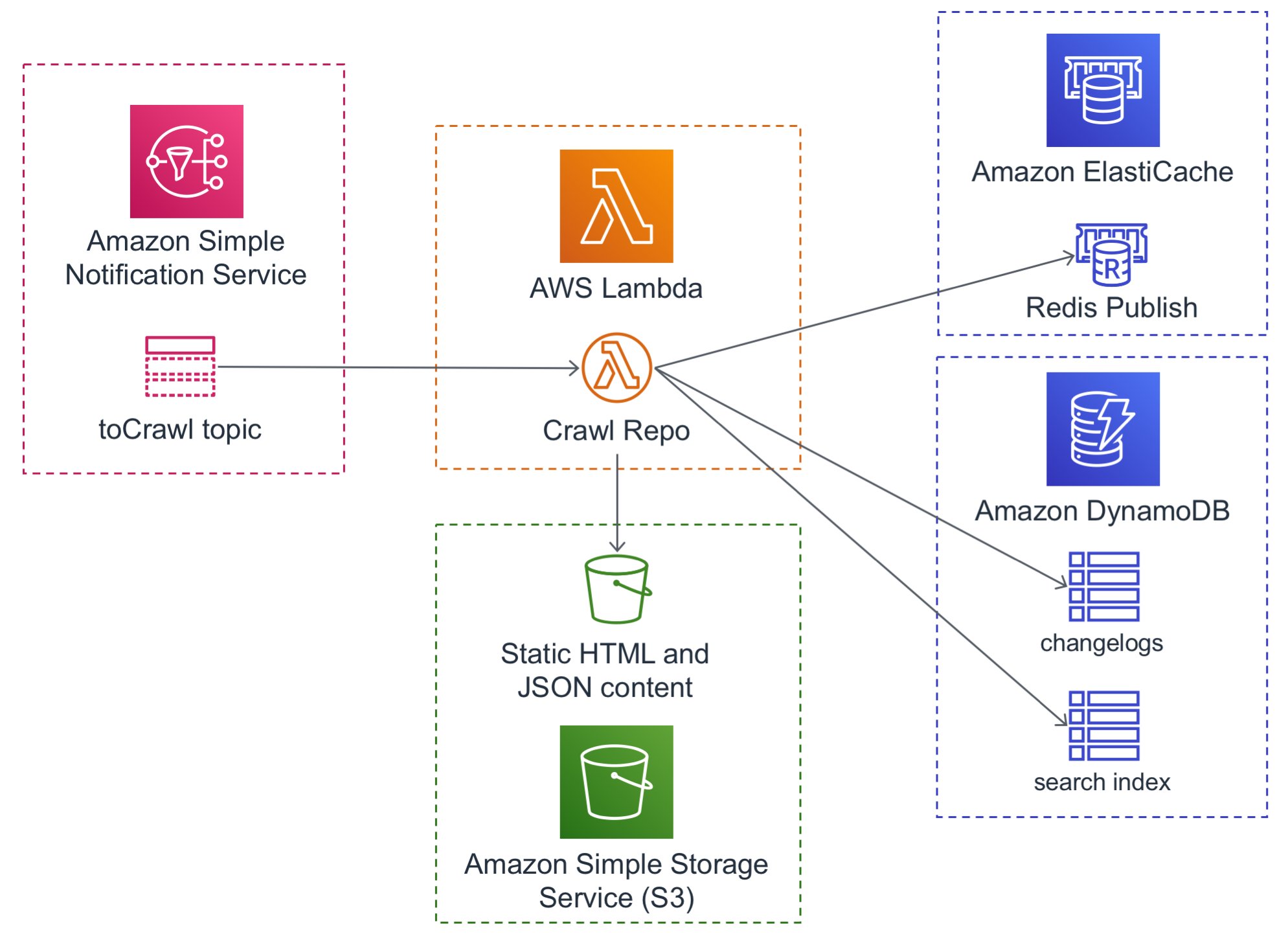
The SNS topic feeds into a Lambda function that does the actual crawl and parse of a changelog. The function generates and stores HTML and JSON files in S3 and metadata in DynamoDB. It also uses Redis Pub/Sub to notify in realtime about newly crawled changelogs.
One of my favorite features is the realtime updates that get pushed to the browser:
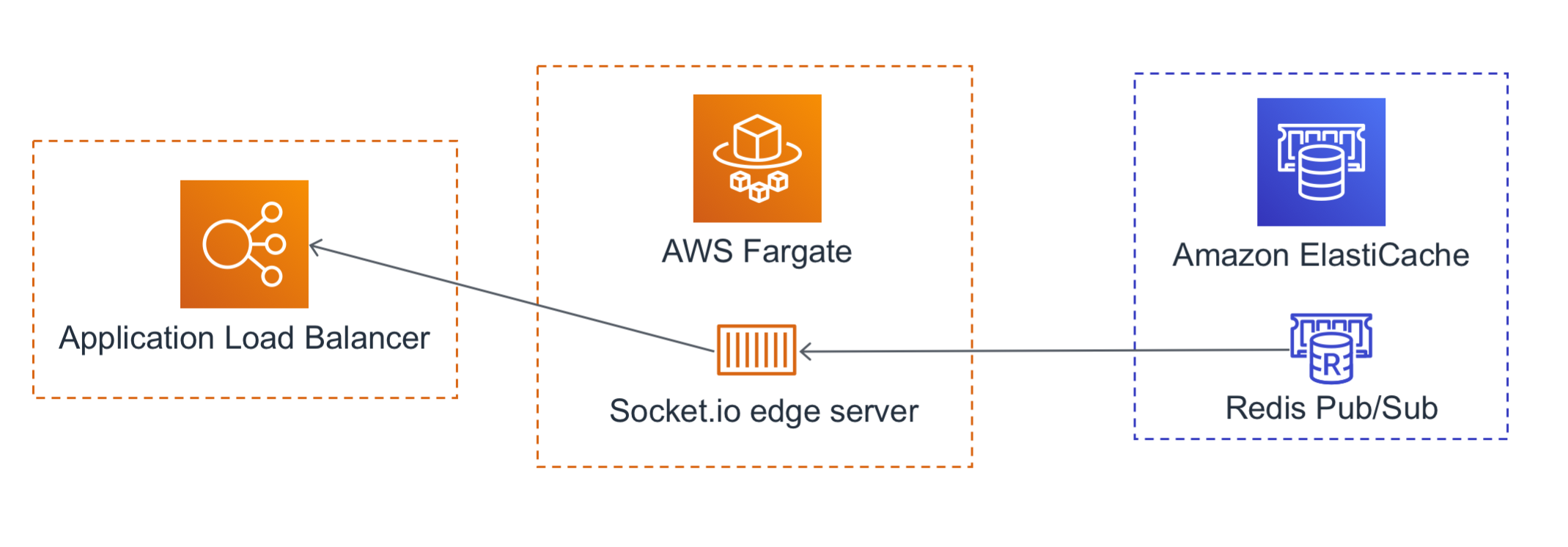
Redis Pub/Sub messages get published back to your browser via a Docker container running Socket.io on AWS Fargate. This is a horizontally scalable layer. I can launch as many containers as needed to monitor Redis Pub/Sub and push messages out to the browsers of any visitors on the website.
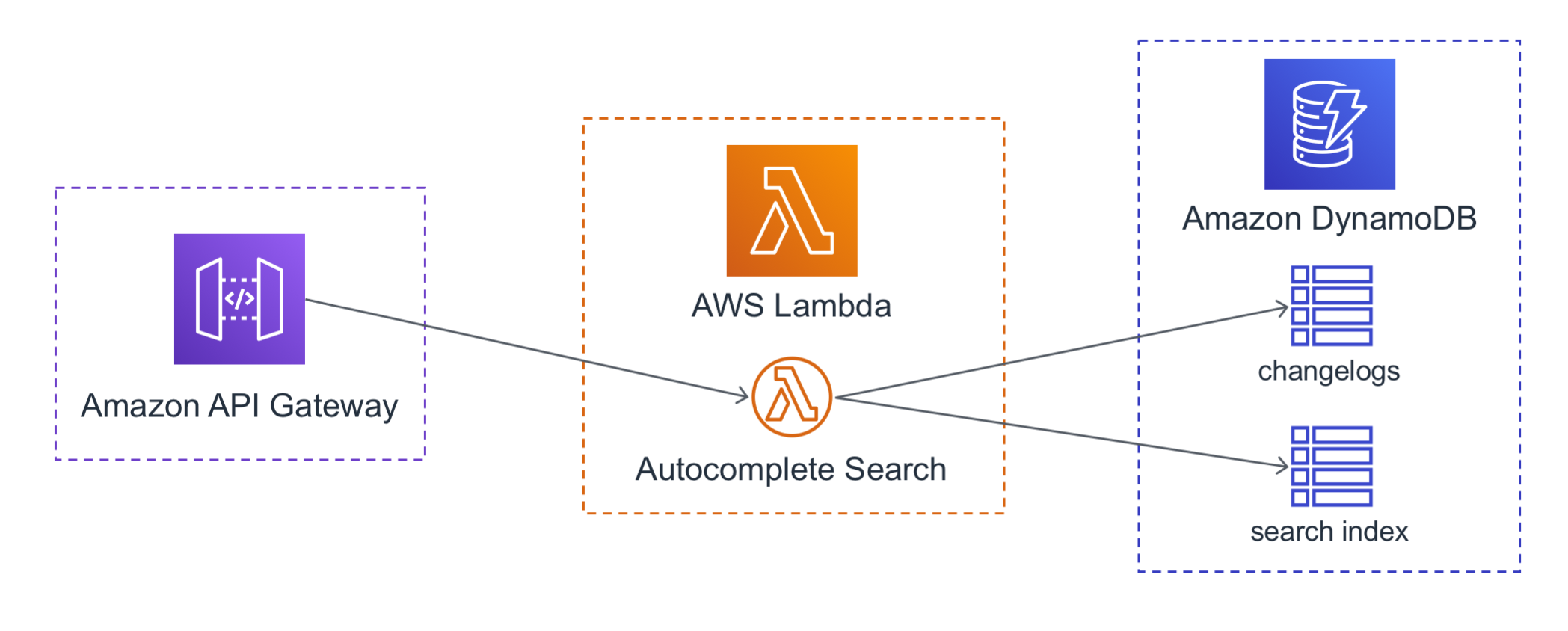
Search is accomplished using a Lambda function behind an API gateway. The function queries the DynamoDB tables that have the metadata about all the changelogs and returns the results:
The final step is to glue all these individual low level components together into a website that you can visit in your browser. Here is the end to end picture:
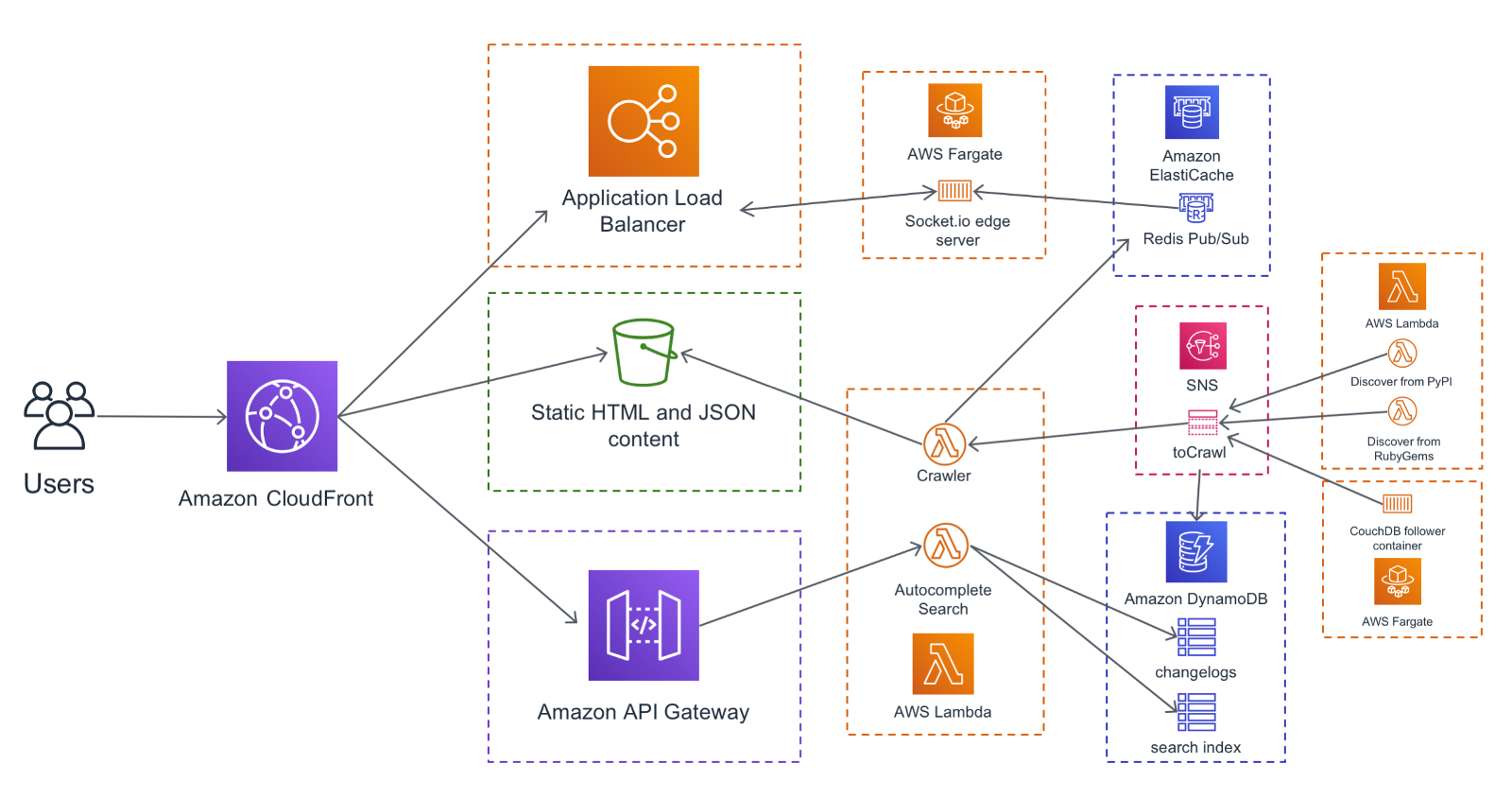
As you can see there are a few different types of resources that make up the site:
- Static content that has been generated by Lambda ahead of time, served from S3
- Dynamic search results generated by a Lambda, requested via an API gateway
- Dynamic updates pushed from the backend to the browser via a load balancer connected to a Docker container.
All these resources get connected to different paths on my domain name via an Amazon CloudFront distribution.
Choosing to build serverless
I received some questions about how I chose which services to use. This is a fair question because AWS has a lot of different services. Often there are multiple services in a single category. Each of them is capable of solving the same problem, just in slightly different ways.
When I choose what services to use one of my biggest questions is “how serverless is this?” At the 2018 AWS re:Invent attendees were introduced to the “spectrum” of serverless on AWS.
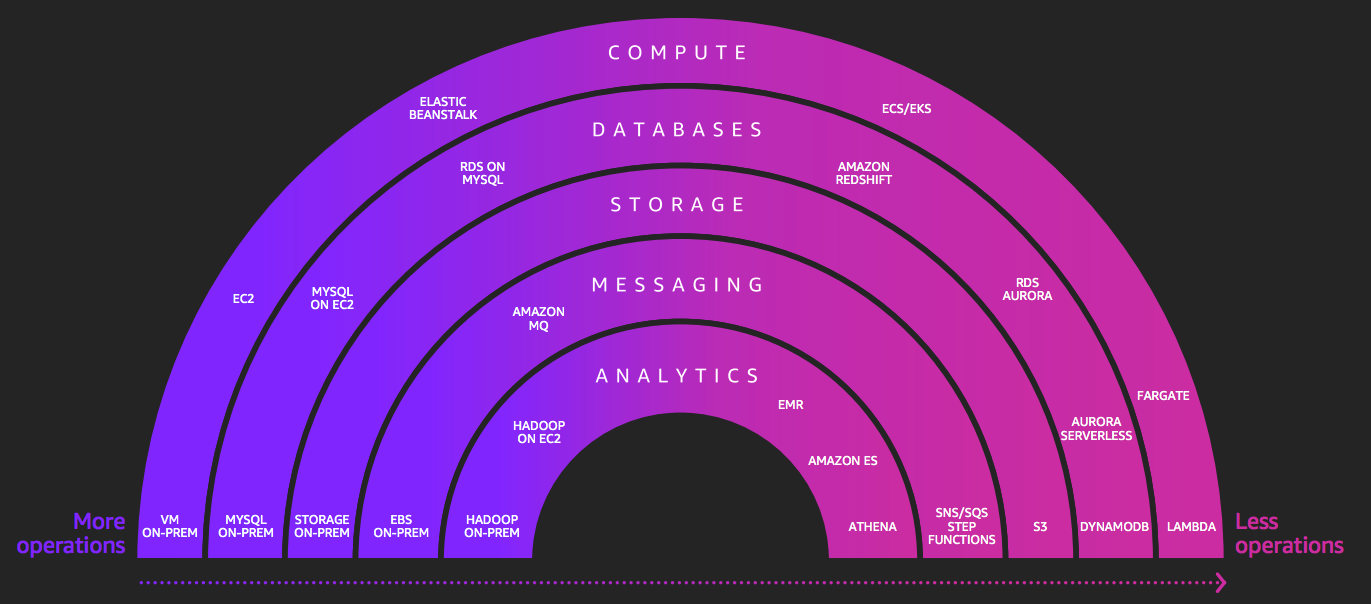
The services on the left hand side are less serverless and require more operations, and the services on the right hand side are more serverless and require less operations. In building changelogs.md I opted to use services that are all very far on the right hand side: Lambda, Fargate, DynamoDB, S3, and SNS. The serverless model fits my needs quite well for a few reasons:
I don’t want to do operations. I don’t want to have to patch any EC2 instances. I don’t want to have to manually scale anything. I don’t want to have to worry about a database running out of space, or logs accumulating and filling a disk. I definitely don’t want to have to renew any SSL certificates. All of the services I’ve chosen autoscale, and require no manual intervention once they are setup.
I don’t want to be pay any more than I have to. If people use the website that’s great and I’ll pay for it. If the site doesn’t get used then I don’t want to pay anything. I think I’ve definitely met this goal. Here is my bill per day over the past month:
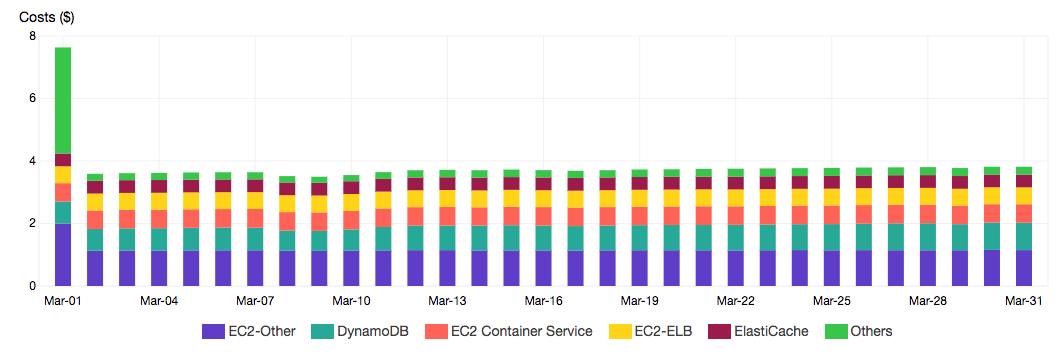
On average the price to run the service is about $3.80 a day. For about the price of my daily cup of coffee I can have an application crawling more than 80k open source repos a day. Here are some more fun stats: every month the application uses 40 million DynamoDB read units and 10 million write units, serves several 100k website visits using S3 and CloudFront, does about one million Lambda invokes and delivers over 500k notifications via SNS. It has two Docker containers and a small Redis instance running 24/7 all month. And remember all of this costs less than $4 a day!
Choosing AWS Lambda and AWS Fargate
Another question that people asked me is why some code runs in Lambda, but other code in Fargate. Often this type of question is being asked by someone who is wondering how to make a choice between the two platforms for their own application.
The most important thing to realize is that there is no reason to make an all-in choice on only one type of compute. Many organizations use both Lambda functions and Docker containers running in Fargate. Any sufficiently complex application probably has some components that are best run in Lambda, and some components that are better run in Docker containers in Fargate.
Serverless architecture works best when you get away from the idea of monolithic compute. Instead consider breaking your compute up into the different types of jobs that need to be done. The shape of each job is what decides the type of underlying compute resource you need.
In the case of changelogs.md there are two main types of jobs being done:
- Short compute jobs that run to completion. This includes “crawl this Github repository for a changelog and parse it” and “check to see if RubyGems has any new packages published”. Most of these jobs take only a few seconds to run.
- Long compute jobs that have no designated end. This includes “open a long lived connection to the NPM CouchDB interface and listen for the updates they send to us as soon as someone publishes an NPM package”, and “maintain an open web socket to the user’s browser, so we can push information about newly discovered changelogs to the browser”. These jobs continue running forever and they have no designated end.
In changelogs.md short lived compute jobs are all being run in AWS Lambda. Each time the code needs to crawl a changelog that is one function invoke. The long lived jobs are running in AWS Fargate. When you open the website your browser connects to a persistent container running in Fargate. That container is always up and running, handling multiple connections at once and pushing updates to the browsers on the other end of those connections.
Another aspect to consider when choosing the compute service to use for a particular job is the isolation model. For example consider the crawl jobs. I could have implemented this part of the stack as a Docker container that watches a queue and pulls jobs off of it. I could even take advantage of Node.js concurrency in this worker process to efficiently process multiple changelogs simultaneously with a single Fargate task.
But it’s easy to imagine that someone may try to attack this component by creating a massive changelog that is gigabytes in size, or take advantage of an edge case in the parser to consume large amounts of resources and DDOS the parsing code. So the Lambda model of execution is perfect for these jobs because it keeps the invokes isolated from each other. If someone triggers a crawl on a malicious changelog that single Lambda execution might timeout but the rest of the system won’t experience any impact, because the individual Lambda invokes are separated from each other and the rest of the stack.
Choosing a cloud native abstraction
I hear the term “cloud native” used a lot. Often the term is used in reference to architectures that are incredibly abstracted away from native cloud resources. Of course abstractions are a good thing. If we had no option but to write native binary machine language it would be hard to get any software written. Modern languages like JavaScript, Go, or Python serve as powerful abstractions that let you write software without needing to write assembly language anymore.
Similarly, the modern cloud native application requires the right level of abstraction to help you create cloud infrastructure without needing to manually setup all the underlying primitive resources. This abstraction must be powerful enough to let you build your application fast, but not so separated from the underlying cloud resources that it limits your ability to implement serverless architectures.
For changelogs.md I chose to use the AWS Cloud Development Kit as my abstraction. CDK automates away a lot of the complexity of networking, permissions, and the manual setup of individual cloud resources. This lets me create my cloud infrastructure faster. It also lets me use the same programming language I use for the core code of my applications, so I don’t have to learn a new language or write a big YAML document.
I find that CDK is at the right level of abstraction for my applications: it doesn’t stop me from using the core cloud native services that I want to use, and it doesn’t require me to write a ton of boilerplate to use those services. For example here is what it looks like to setup a Lambda function which can access a DynamoDB table, and execute it on a schedule:
You can see the full CDK code for the website in the open source Github repo.
Conclusion
Cloud services that have a serverless operational model are making it much easier to build a modern application that doesn’t require a lot of maintenance and is also cheap. Decomposing your application into smaller pieces that fit different serverless compute models lets you take advantage of the best compute option for each piece of your application. Finally, it is easier to build a modern serverless application when you choose the right abstraction layer that gives you easy access to the native cloud services you need. Don’t let a thick, complicated abstraction get in your way and stop you from implementing things efficiently.
Please check out the open source code for changelogs.md if you’d like to learn more about AWS Lambda, AWS Fargate, and the AWS Cloud Development Kit: