
Diving into Amazon ECS task history with Container Insights
Container orchestrators like Amazon Elastic Container Service (ECS) are constantly watching over your application, 24 hours a day and 7 days a week, more attentively than any human operator ever could. The orchestrator is able to make decisions autonomously to keep your services online. For example, ECS can automatically run health checks against your application and restart the application task if it is failing healthchecks. If your application crashes unexpectedly, or the instance hosting an application goes down, then ECS can restart your application automatically on different hardware.
Even when you trust ECS with the full lifecycle of your application, how can you check up on historical actions that ECS has taken? For example, imagine that you receive a PagerDuty notification about a fatal, application crashing runtime exception that occurred sometime in the middle of the night. This event has gradually escalated to you through several other on-call engineers, so at this point the application crash was a couple hours ago. ECS has already replaced this task a long time ago, but you still want to dive into the details and try to figure out what happened, so that you can prevent it from happening again.
There are three tools you can use to understand the actions that Amazon ECS took, and do post mortem analysis of application failures.
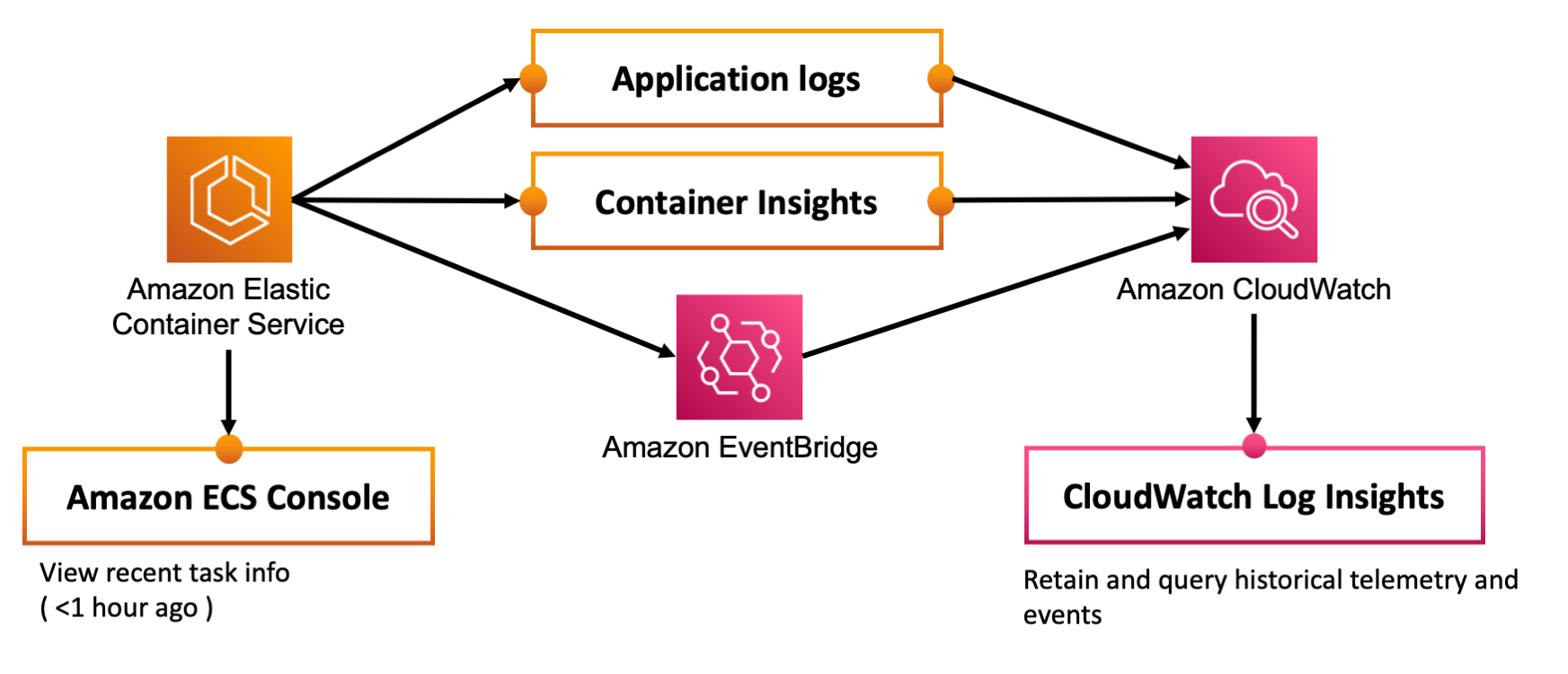
- Built-in task history in the Amazon ECS console: Easy to use and free, but limited data retention.
- Amazon ECS CloudWatch Container Insights: Easy to enable, but you pay a bit extra for high resolution telemetry retention, and for queries.
- Amazon ECS EventBridge Events - Requires a bit of configuration, but you can capture the full history of ECS state changes, and query it later on.
Built-in Amazon ECS task history
ECS itself retains detail about tasks for a limited time. If an application task crashed or was stopped within the last hour you can view details about that stopped task in the ECS console.
-
Navigate to the task list for your service:
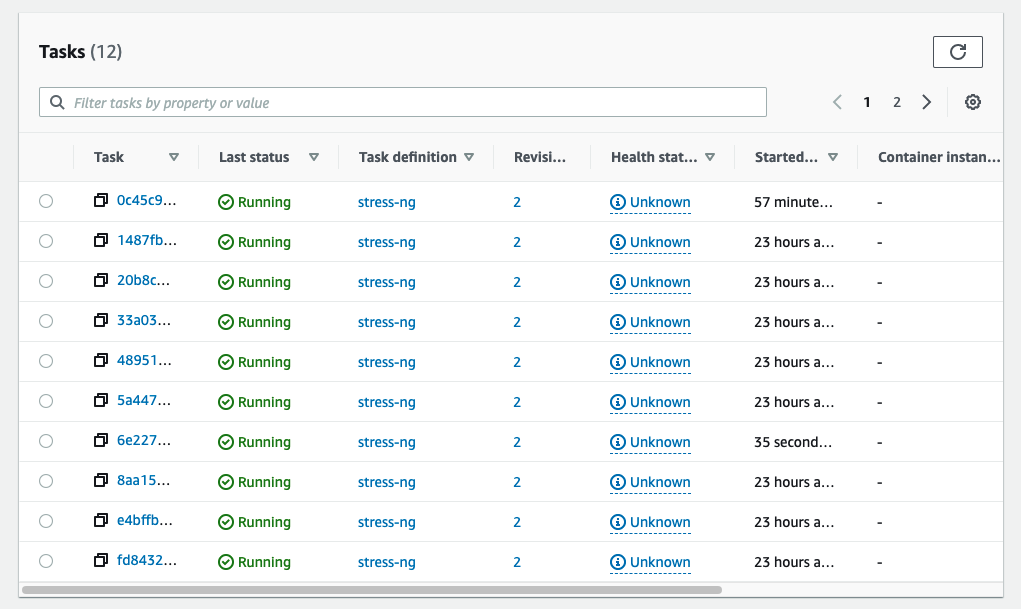
-
Open the filter dropdown and select “Desired Status”
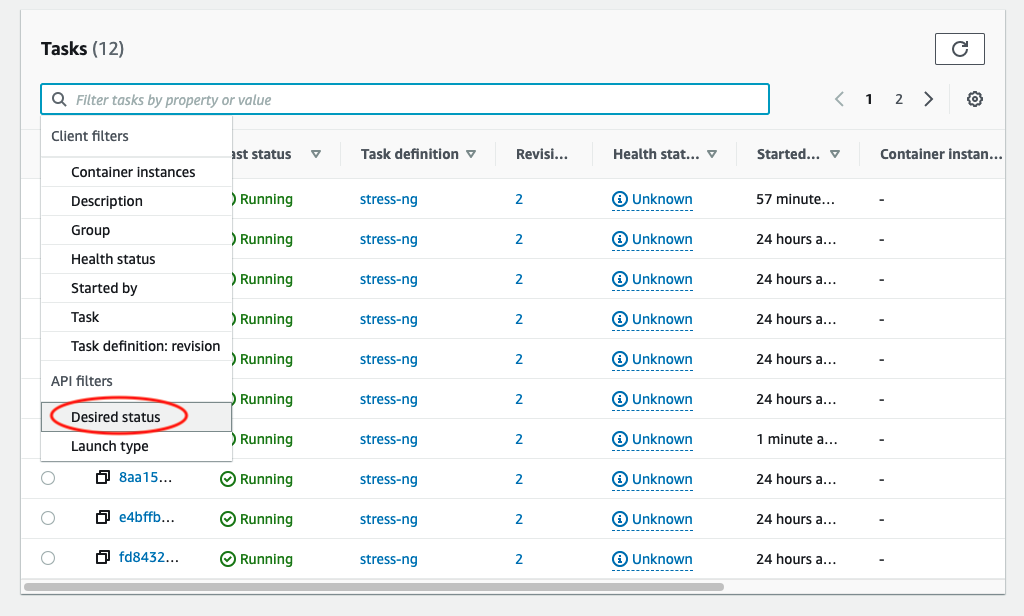
-
Select “Desired Status: Stopped”
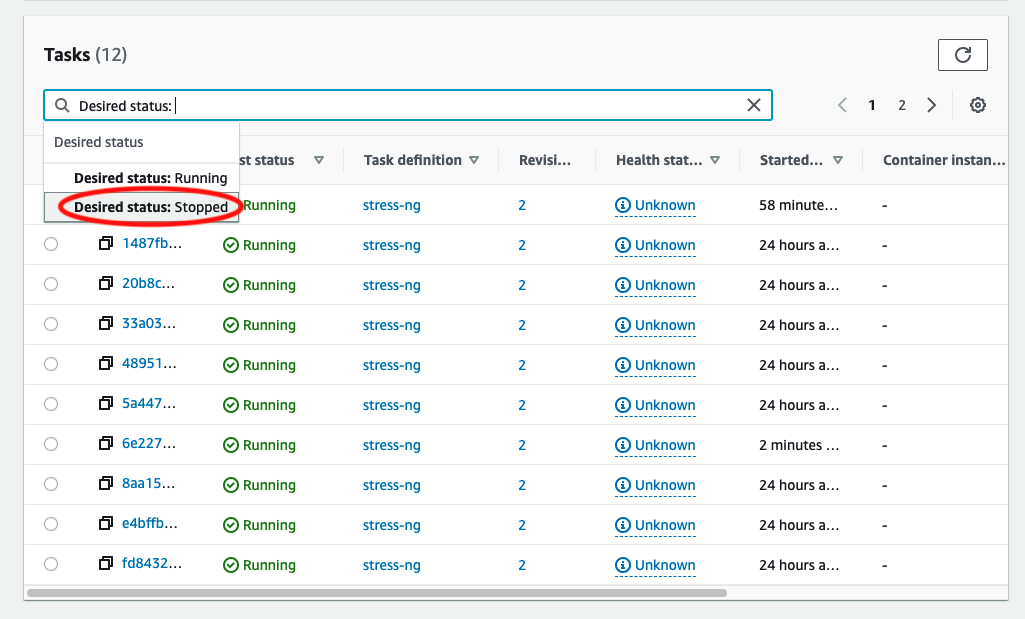
-
View the list of recently stopped tasks
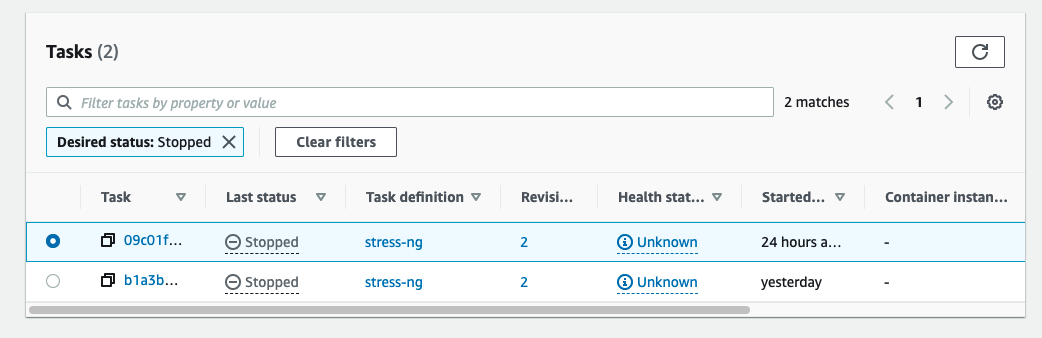
-
Now you can click on the stopped task to view details
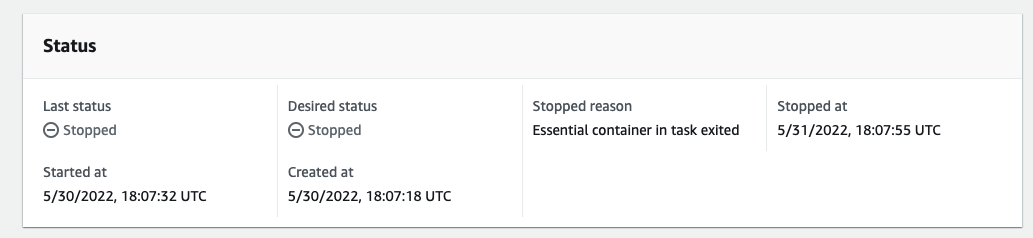
In this case when I locate the stopped task I can see that the task stopped because “Essential container in task exited”. This usually means that the container crashed, so I should probably click the application logs tab for this task to see why the application container had crashed.
Task and container level telemetry for historical tasks
Amazon ECS CloudWatch Container Insights is an optional feature that you can enable to store and retain task telemetry data for as long as you want. The task telemetry data includes resource usage statistics, at one minute resolution, covering CPU, memory, networking, and storage. This feature does come with an additional cost based on the amount of data stored in CloudWatch, and an additional cost for querying that data. A task with one container generates about 1 MB of telemetry data per day. If there is more than one container per task, or you have frequent task turnover you may generate even more telemetry data.
In order to activate Container Insights for a cluster, you can use the command line:
aws ecs update-cluster-settings \
--cluster cluster_name_or_arn \
--settings name=containerInsights,value=enabled \
--region us-east-1
Or you can enable Container Insights when creating an ECS cluster with CloudFormation:
MyCluster:
Type: AWS::ECS::Cluster
Properties:
ClusterName: production
Configuration:
containerInsights: enabled
From this point on you will start to see new metrics and new logs stored in CloudWatch. You can find the raw task details over time stored in CloudWatch Logs, under the namespace /aws/ecs/containerinsights/<cluster-name>. By default this log group only stores data for one day. However, you can edit the retention period to store this data for even longer.
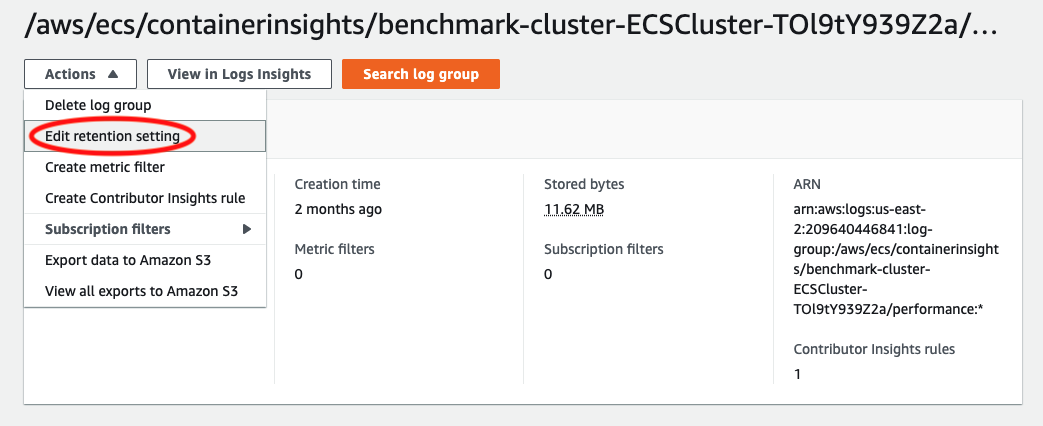
Keep in mind that the cost of the log group will scale up depending on how long you retain the task data, how many tasks you are running, and how many containers you are running per task. Amazon ECS emits telemetry data every minute, for each task and each container in each task, so this volume of data can add up quickly for large workloads.
Let’s take a look at a sample of the underlying data to see what it looks like:
Container:
{
"Version": "0",
"Type": "Container",
"ContainerName": "stress-ng",
"TaskId": "fd84326dd7a44ad48c74d2487f773e1e",
"TaskDefinitionFamily": "stress-ng",
"TaskDefinitionRevision": "2",
"ServiceName": "stress-ng",
"ClusterName": "benchmark-cluster-ECSCluster-TOl9tY939Z2a",
"Image": "209640446841.dkr.ecr.us-east-2.amazonaws.com/stress-ng:latest",
"ContainerKnownStatus": "RUNNING",
"Timestamp": 1654023960000,
"CpuUtilized": 24.915774739583338,
"CpuReserved": 256,
"MemoryUtilized": 270,
"MemoryReserved": 512,
"StorageReadBytes": 0,
"StorageWriteBytes": 0,
"NetworkRxBytes": 0,
"NetworkRxDropped": 0,
"NetworkRxErrors": 0,
"NetworkRxPackets": 4532,
"NetworkTxBytes": 0,
"NetworkTxDropped": 0,
"NetworkTxErrors": 0,
"NetworkTxPackets": 1899
}
Task:
{
"Version": "0",
"Type": "Task",
"TaskId": "fd84326dd7a44ad48c74d2487f773e1e",
"TaskDefinitionFamily": "stress-ng",
"TaskDefinitionRevision": "2",
"ServiceName": "stress-ng",
"ClusterName": "benchmark-cluster-ECSCluster-TOl9tY939Z2a",
"AccountID": "209640446841",
"Region": "us-east-2",
"AvailabilityZone": "us-east-2a",
"KnownStatus": "RUNNING",
"LaunchType": "FARGATE",
"PullStartedAt": 1653939338545,
"PullStoppedAt": 1653939339153,
"CreatedAt": 1653939325821,
"StartedAt": 1653939341144,
"Timestamp": 1654024020000,
"CpuUtilized": 67.77333821614583,
"CpuReserved": 256,
"MemoryUtilized": 270,
"MemoryReserved": 512,
"StorageReadBytes": 0,
"StorageWriteBytes": 0,
"NetworkRxBytes": 0,
"NetworkRxDropped": 0,
"NetworkRxErrors": 0,
"NetworkRxPackets": 4533,
"NetworkTxBytes": 0,
"NetworkTxDropped": 0,
"NetworkTxErrors": 0,
"NetworkTxPackets": 1900,
"EphemeralStorageReserved": 21.47
}
As you can see there is quite a bit of telemetry data here but we need a way to explore that data. Fortunately, this is where CloudWatch Log Insights can help us.
You can access CloudWatch Log Insights by clicking on the “View in Logs Insights” button at the top of the log group:
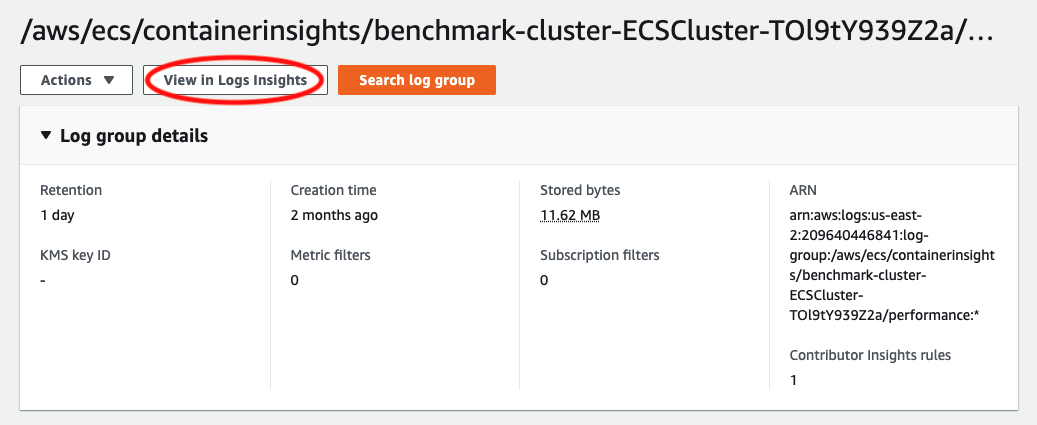
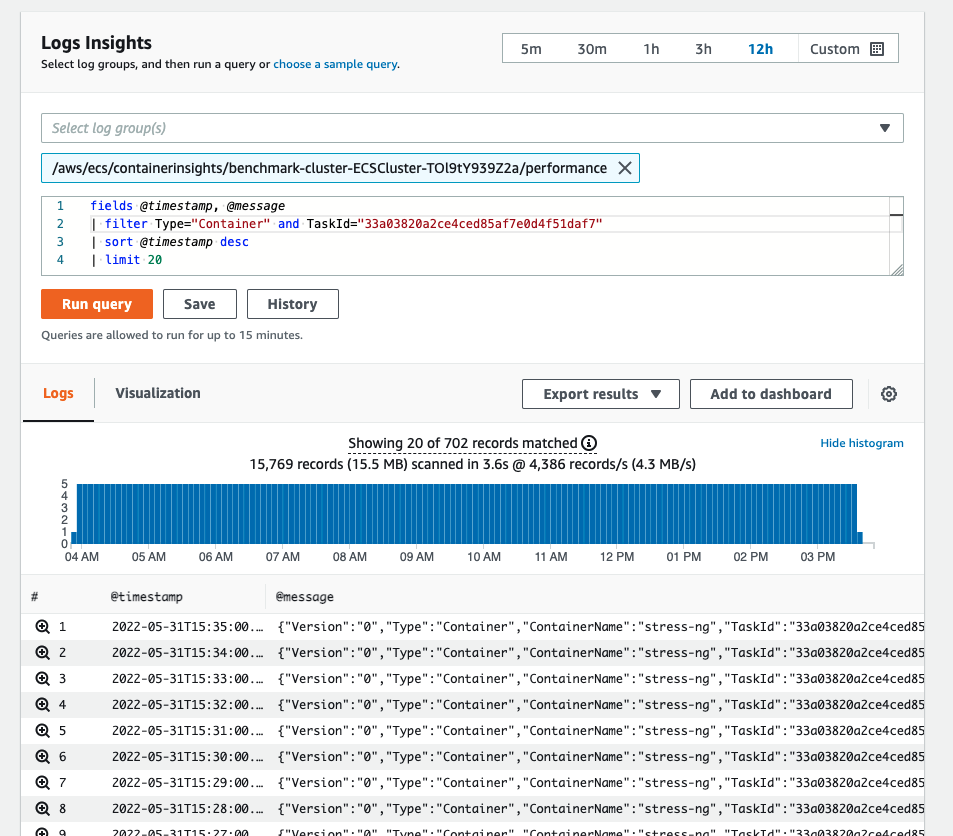
This opens up a query interface that allows you to input your own queries for filtering and searching through the data. For example here is how you can grab the telemetry data for a single container in a single task, over time:
fields @timestamp, @message
| filter Type="Container" and TaskId="33a03820a2ce4ced85af7e0d4f51daf7"
| sort @timestamp desc
| limit 20
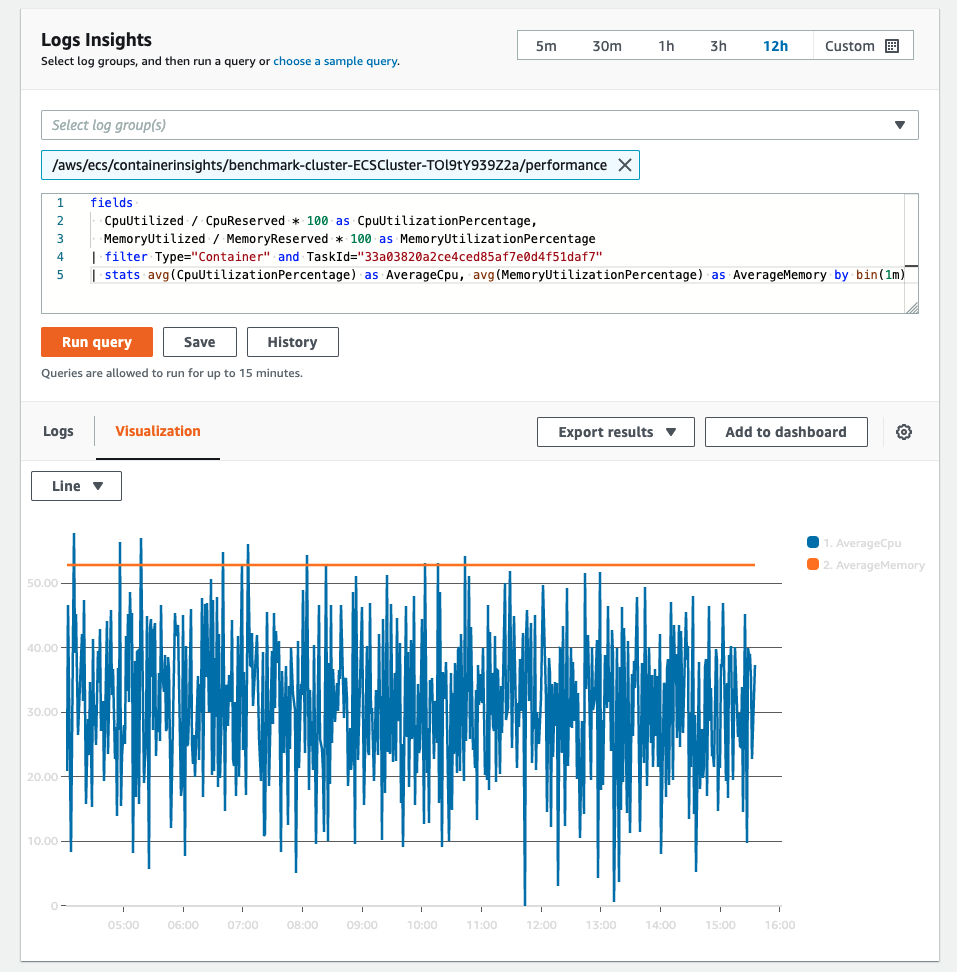
You can also write more complex queries to pull out specific stats from the telemetry data and visualize them. For example:
fields
CpuUtilized / CpuReserved * 100 as CpuUtilizationPercentage,
MemoryUtilized / MemoryReserved * 100 as MemoryUtilizationPercentage
| filter Type="Container" and TaskId="33a03820a2ce4ced85af7e0d4f51daf7"
| stats avg(CpuUtilizationPercentage) as AverageCpu, avg(MemoryUtilizationPercentage) as AverageMemory by bin(1m)
If you are interested in learning more about the power of the CloudWatch Log Insights query language I highly recommend the query syntax docs. There you can learn more about the powerful pattern matching and statistics features that are built-in to CloudWatch Log Insights.
Capture Amazon ECS event history
In addition to the raw telemetry, Amazon ECS produces events which can be captured in a CloudWatch log group using Amazon EventBridge. These events happen when a service is updated, a task changes state, or a container instance changes state. Here is how you can capture these events using Amazon EventBridge.
-
Open up Amazon EventBridge and start creating a new rule:
-
Create a rule pattern which matches the Amazon ECS events you are interested in. In this case I am creating a rule to monitor task state change events for one specific cluster:

-
Create a target for the events. CloudWatch log group will be the easiest way to store these events, so that you can query the events in the same way as the telemetry data from Container Insights.
If you prefer to use infrastructure as code to setup resources on your AWS account then consider adapting the following CloudFormation snippet. I personally like to have the same CloudFormation template deploy both my service and its own event persistence.
# A CloudWatch log group for persisting the Amazon ECS events
ServiceEventLog:
Type: AWS::Logs::LogGroup
Properties:
LogGroupName: !Sub /benchmark/${EnvironmentName}-${ServiceName}-events
# Create the EventBridge rule that captures deployment events into the CloudWatch log group
CaptureServiceDeploymentEvents:
Type: AWS::Events::Rule
Properties:
Description: !Sub 'Capture service deployment events from the ECS service ${ServiceName}'
# Which events to capture
EventPattern:
source:
- aws.ecs
detail-type:
- "ECS Deployment State Change"
- "ECS Service Action"
resources:
- !Ref Service
# Where to send the events
Targets:
- Arn: !Sub arn:aws:logs:${AWS::Region}:${AWS::AccountId}:log-group:${ServiceEventLog}
Id: 'CloudWatchLogGroup'
# Create a log group resource policy that allows EventBridge to put logs into
# the log group
LogGroupForEventsPolicy:
Type: AWS::Logs::ResourcePolicy
Properties:
PolicyName: EventBridgeToCWLogsPolicy
PolicyDocument: !Sub
- >
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "EventBridgetoCWLogsPolicy",
"Effect": "Allow",
"Principal": {
"Service": [
"delivery.logs.amazonaws.com",
"events.amazonaws.com"
]
},
"Action": [
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": [
"${LogArn}"
]
}
]
}
- { LogArn: !GetAtt ServiceEventLog.Arn, RuleArn: !GetAtt CaptureServiceDeploymentEvents.Arn}
However you choose to setup the rule for capturing Amazon ECS events, after a minute or two you will start to see events stored into CloudWatch, so now you can use CloudWatch Log Insights once again to explore this data:
fields @timestamp, @message
| sort @timestamp desc
| limit 20
Here is a sample of what a single task state change event looks like:
{
"version": "0",
"id": "b38a1269-debf-7ada-9576-f69ce2752526",
"detail-type": "ECS Task State Change",
"source": "aws.ecs",
"account": "209640446841",
"time": "2022-05-31T20:12:43Z",
"region": "us-east-2",
"resources": ["arn:aws:ecs:us-east-2:209640446841:task/benchmark-cluster-ECSCluster-TOl9tY939Z2a/0c45c999f51741509482c5829cebb82e"],
"detail": {
"attachments": [{
"id": "4b01ba81-00ee-471d-99dc-9d215bff56e5",
"type": "eni",
"status": "DELETED",
"details": [{
"name": "subnetId",
"value": "subnet-04f3a518011557633"
}, {
"name": "networkInterfaceId",
"value": "eni-0685196fd7cf97f27"
}, {
"name": "macAddress",
"value": "06:a8:e2:77:53:2c"
}, {
"name": "privateDnsName",
"value": "ip-10-0-121-242.us-east-2.compute.internal"
}, {
"name": "privateIPv4Address",
"value": "10.0.121.242"
}]
}],
"attributes": [{
"name": "ecs.cpu-architecture",
"value": "x86_64"
}],
"availabilityZone": "us-east-2b",
"capacityProviderName": "FARGATE",
"clusterArn": "arn:aws:ecs:us-east-2:209640446841:cluster/benchmark-cluster-ECSCluster-TOl9tY939Z2a",
"connectivity": "CONNECTED",
"connectivityAt": "2022-05-31T18:08:12.052Z",
"containers": [{
"containerArn": "arn:aws:ecs:us-east-2:209640446841:container/benchmark-cluster-ECSCluster-TOl9tY939Z2a/0c45c999f51741509482c5829cebb82e/1471ad51-9c53-4d56-82d9-04b26f82369e",
"exitCode": 0,
"lastStatus": "STOPPED",
"name": "stress-ng",
"image": "209640446841.dkr.ecr.us-east-2.amazonaws.com/stress-ng:latest",
"imageDigest": "sha256:75c15a49ea93c3ac12c73a283cb72eb7e602d9b09fe584440bdf7d888e055288",
"runtimeId": "0c45c999f51741509482c5829cebb82e-2413177855",
"taskArn": "arn:aws:ecs:us-east-2:209640446841:task/benchmark-cluster-ECSCluster-TOl9tY939Z2a/0c45c999f51741509482c5829cebb82e",
"networkInterfaces": [{
"attachmentId": "4b01ba81-00ee-471d-99dc-9d215bff56e5",
"privateIpv4Address": "10.0.121.242"
}],
"cpu": "256",
"memory": "512"
}],
"cpu": "256",
"createdAt": "2022-05-31T18:08:08.011Z",
"desiredStatus": "STOPPED",
"enableExecuteCommand": false,
"ephemeralStorage": {
"sizeInGiB": 20
},
"executionStoppedAt": "2022-05-31T20:12:20.683Z",
"group": "service:stress-ng",
"launchType": "FARGATE",
"lastStatus": "STOPPED",
"memory": "512",
"overrides": {
"containerOverrides": [{
"name": "stress-ng"
}]
},
"platformVersion": "1.4.0",
"pullStartedAt": "2022-05-31T18:08:22.205Z",
"pullStoppedAt": "2022-05-31T18:08:23.109Z",
"startedAt": "2022-05-31T18:08:23.817Z",
"startedBy": "ecs-svc/3941167241989127803",
"stoppingAt": "2022-05-31T20:12:06.844Z",
"stoppedAt": "2022-05-31T20:12:43.412Z",
"stoppedReason": "Scaling activity initiated by (deployment ecs-svc/3941167241989127803)",
"stopCode": "ServiceSchedulerInitiated",
"taskArn": "arn:aws:ecs:us-east-2:209640446841:task/benchmark-cluster-ECSCluster-TOl9tY939Z2a/0c45c999f51741509482c5829cebb82e",
"taskDefinitionArn": "arn:aws:ecs:us-east-2:209640446841:task-definition/stress-ng:2",
"updatedAt": "2022-05-31T20:12:43.412Z",
"version": 6
}
}
As you can see there is a LOT more data here. This EventBridge integration is designed to capture a point in time snapshot of the task’s metadata each time there is a task state change. This allows you to query by a specific task ID and look back at the history of all the state changes it went through.
For example here is a query that shows a history of the task state changes for AWS Fargate:
fields @timestamp, detail.attachments.0.status as ENI, detail.lastStatus as status, detail.desiredStatus as desiredStatus, detail.stopCode as stopCode, detail.stoppedReason as stoppedReason
| filter detail.taskArn = "<your task ARN>"
| sort @timestamp desc
| limit 20
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
| @timestamp | ENI | status | desiredStatus | stopCode | stoppedReason |
|-------------------------|------------|----------------|---------------|---------------------------|------------------------------------------------------------------------|
| 2022-06-01 19:03:41.000 | DELETED | STOPPED | STOPPED | ServiceSchedulerInitiated | Scaling activity initiated by (deployment ecs-svc/8045142110272152487) |
| 2022-06-01 19:03:08.000 | ATTACHED | DEPROVISIONING | STOPPED | ServiceSchedulerInitiated | Scaling activity initiated by (deployment ecs-svc/8045142110272152487) |
| 2022-06-01 19:02:45.000 | ATTACHED | RUNNING | STOPPED | ServiceSchedulerInitiated | Scaling activity initiated by (deployment ecs-svc/8045142110272152487) |
| 2022-06-01 18:56:56.000 | ATTACHED | RUNNING | RUNNING | | |
| 2022-06-01 18:56:51.000 | ATTACHED | PENDING | RUNNING | | |
| 2022-06-01 18:56:29.000 | PRECREATED | PROVISIONING | RUNNING | | |
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
With this abbreviated table you can see the history of state changes that an AWS Fargate task goes through as it normally starts up and then shuts down.
In the case of a task that unexpectedly stopped at some point in the past this history of events can be very useful for understanding just what happened to this task and why.
If you are interested in service level events, or container instance level events you can find samples of what those events look like in the Amazon ECS events documentation.
Conclusion
There are three tools that you can use to explore your Amazon ECS task history:
- Built-in task history in the Amazon ECS console - Only retains task details for an about an hour after tasks stop
- Amazon ECS CloudWatch Container Insights - Retain task and container level telemetry in Amazon CloudWatch for as long as you want
- Amazon ECS EventBridge Events - Retain full task state change history in Amazon CloudWatch for as long as you want
Alongside these options consider using Amazon CloudWatch Log Insights as a query engine for searching and visualizing this task telemetry and history.