
Granular Application Architecture Patterns
One of the recent trends in server side application development is to decompose a large application into smaller pieces which are more granular. This article explores application architecture patterns, starting from the venerable monolithic application, to smaller microservices, and finally the most granular pattern of all: functions as a service. You can try deploying each of these architectures yourself by using the accompanying workshop code on Github.
The Monolith
This classic architecture pattern is most beneficial when used for small projects, and new greenfield projects where the core concepts and pieces of the system are not yet fully fleshed out. The basic principle of the monolith is to write all your code as one process or as a group of tightly coupled components that will always be deployed together on a machine. Deploying a monolith typically looks something like this:
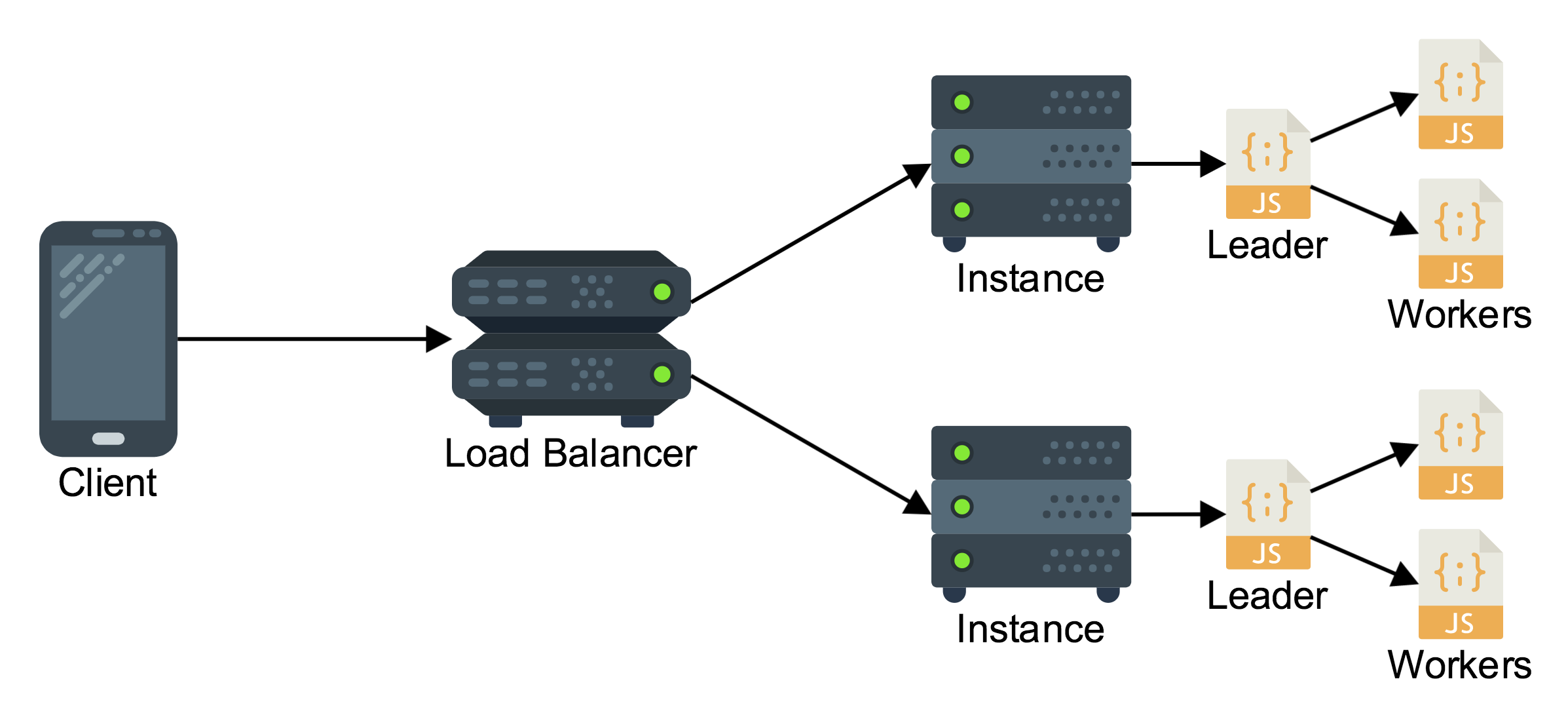
Behind the load balancer is a group of machines which are all running an identical server stack. Each machine is capable of handling any request so the load balancer is free to route any request to any machine in the cluster. In this example architecture the server side process is written in Node.js so there is a leader process which spawns one worker per server core. The workers all share a single port.
Benefits
- Deploying this stack is fairly simple. One common strategy for provisioning and updating a monolithic stack on Amazon Web Services is to bake an Amazon Machine Image (AMI) which can be used as a template for launching any number of instances. It is easy to create an EC2 Autoscaling Group using an AMI, or ask an Autoscaling Group to roll out a new version of an AMI across the group.
- Because all the features of the application are contained within the same process, they are all just a function call away. This makes your application fast, and makes it easy to link features together with each other without needing to worry about network communication, eventual consistency, or other challenges of a distributed system.
Drawbacks
- Updating any single feature of your application requires redeploying the entire stack across the entire cluster. This won’t be a problem early on, but for large applications that run across a large number of machines it becomes quite a penalty to need to update several hundred or even several thousand machines with new code each time you update a single feature.
- As the number of features in your application grow, the fact that all features are contained in one process can lead to spaghetti dependencies between features that make updating existing features, and adding new features a challenge. It takes very experienced developers to be able to organize a large monolithic codebase without it falling apart under its own weight.
- Because the features are all running in one process it means that any security vulnerabilities in one feature can potentially compromise the entire system, and any runtime exceptions that are caused by one feature can crash the entire system and effect availability of all features.
- Because the features are tightly coupled performance issues in one feature can impact all features. Heavy CPU usage by one feature can end up causing latency across the entire system, on all endpoints.
Service Oriented Architecture (Microservices)
The goal of a service oriented, or microservice, architecture is to subdivide an application based on business functionality. Each subdivision is focused on a specific class of feature. For example an application may have user account functionality as well as authentication functionality. A service oriented architecture would organize this functionality into two services which talk to each other when necessary but are otherwise independent. A typical microservice deployment often looks like this:

In this example the microservices are being run as processes inside Docker containers. This has the benefit of allowing multiple services to run on the same machine inside containers that isolate them from each other to avoid conflicts. In this architecture only one process is being run in each container, and in order to fully utilize the processors of a multi-core server multiple containers are run in parallel. Each container is linked to a randomly assigned port on the instance. An application load balancer is used to direct HTTP traffic matching a specific rule to the correct container on the correct port. Amazon Elastic Container service is used to orchestrate it all, from launching the containers, monitoring them, and updating the load balancer to send the right traffic to the right place.
Benefits
- Services can be deployed independently from each other. This means that when a change is introduced to one service it can be rolled out across a minimal subset of the overall cluster of machines: just those machines that are powering that feature. This makes it easier to iterate faster, tightening the loop between feature development and a feature being live in production.
- Isolation of features into separate services allows new features to be added without introducing the risk of destabilizing existing features. One container could have a runtime exception and crash without taking down another container powering a mission critical feature. This helps your application be more resilient.
- The isolation of services from each other minimizes security risk. In specific Amazon EC2 Container Service allows you to run each service container with a different AWS role. This gives each service its own temporary credentials that authorize it to access specific resources. You don’t have to worry about a remote code execution vulnerability in ImageMagick being leveraged to access your customer’s passwords, because your image processing service would be limited to only accessing your S3 bucket for images, while the passwords database would only be accessible to the authentication service.
- The services can scale independently and have independent resource constraints. This means your authentication service that is hashing passwords with a high round bcrypt hashing algorithm can scale up and down independently from a lightweight API that is just serializing and deseralizing JSON. Each service’s resource demands can also be limited independently, so if resource needs for one service suddenly spike, latency will increase for that feature, but other features will remain unaffected.
Drawbacks
- The complexity of deployment is increased because there are more pieces to deploy. A microservice architecture will always require the use of automation and orchestration frameworks in order for deployments to stay sane.
- The isolation of services introduces complexities of distributed computing, as well as added latency whenever one service needs to communicate with another service.
- Tracing and identifying where an application issue arises from can be challenging if you are used to monolithic application tracing strategies. * Debugging a microservice application requires being able to identify which service is causing an issue, and then digging into that service, compared with just dropping trace points into a single monolith. For this reason it is critical to have good logging and monitoring solutions for your application.
Functions as Services
This is the most granular form of application architecture. This application design takes each individual application endpoint and turns it into a separate compute resource that runs on demand:
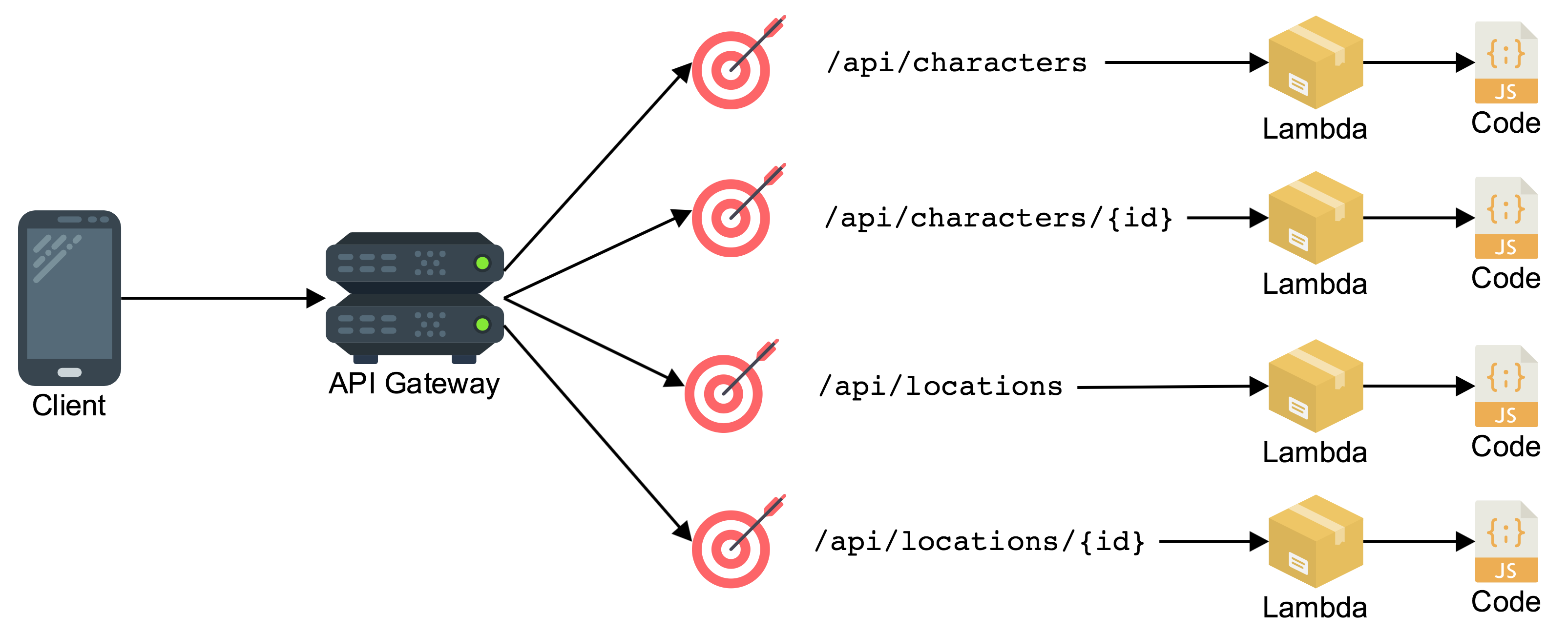
This design uses AWS API Gateway and AWS Lambda to power an API. The gateway accepts each incoming request and separates the requests into individual API routes. The logic for each route is run by a dedicated lambda function that serves that single endpoint. Each lambda function can scale independently and transparently.
Benefits
- This architecture is cost effective for low traffic applications because you can pay as you go only for the resources that you use. Instead of needing to run an EC2 instance at all times in order to be available to respond to API requests you only pay when an API request arrives, and you only pay for the resources you actually use to process that request.
- The high level of granularity means that each lambda function can be kept simple and easy to understand. This makes maintenance and learning the code base easy.
- Just as in a service oriented architecture each lambda function has crash isolation and security isolation. Each one can have its own limited AWS Identity and Access Management role to grant it access to a limited subset of AWS resources, and if one of them has a runtime exception it will only affect that individual request, rather than impacting the entire platform, or an entire service.
Drawbacks
- This architecture is more expensive for high traffic applications due to the added overhead of the function level isolation. It is cheaper to run your own instance if you have consistently high traffic that would keep an EC2 instance busy. You only save money using lambda if your application spends a lot of time doing nothing.
- The extreme granularity and ephemeral nature of the compute platform adds a lot of extra latency to your API. It isn’t uncommon to see lambda “cold starts” of up to two seconds, and if you have a database connection there will be added latency and database load from frequently establishing a connection to the database, compared with a persistent server process that can reuse a long-lived connection pool that is maintained in-between requests.
Conclusion
Each level of application architecture granularity has its own benefits and drawbacks that must be balanced according to the complexity and specific performance needs of your application. For example a brand new application with low traffic and a small budget might choose lambda to build out a prototype. As the traffic level grows they may find a monolithic application to be cheaper to run as long as the code complexity isn’t too great. But a large application that has lots of complexity, lots of traffic, and high reliability and security needs may require the isolation of microservices instead of a monolith.
If you would like to deploy any of these three architectures check out the workshop code and deploy your first monolith, microservice, or function as a service architecture on AWS.