
Microservice Principles: Smart Endpoints and Dumb Pipes
As engineering organizations transition from building monolithic architecture to building microservices architecture one challenge they often face is understanding how to enable communications between microservices.
In a monolith the various components are all in the same process, just a function call away. But in a microservice environment components are separated by hard boundaries. In fact, a true microservice environment will often have the various components distributed across a cluster of instances. Microservices are not even necessarily collocated on the same machine.
The best way to solve this problem of communicating between microservices is by following the principle of “smart endpoints and dumb pipes” as explained in Martin Fowler’s 2014 paper defining microservices. This article elaborates on Martin Fowler’s concept, and explains modern techniques for building microservice communications that follow the “dumb pipe” paradigm.
Types of Microservice Communication
There are two primary forms of communication between microservices that need to be solved for:
- Request-Response: One service invokes another service by making an explicit request, usually to store or retrieve data. The service then expects a response: either a resource or an acknowledgement.
- Observer: Event based, implicit invocation where one service publishes an event and one or more observers that were watching for that event respond to it by running logic asynchronously, outside the awareness of the producer of the event.
To illustrate these two types of communication consider the following microservice architecture for a basic social media application:
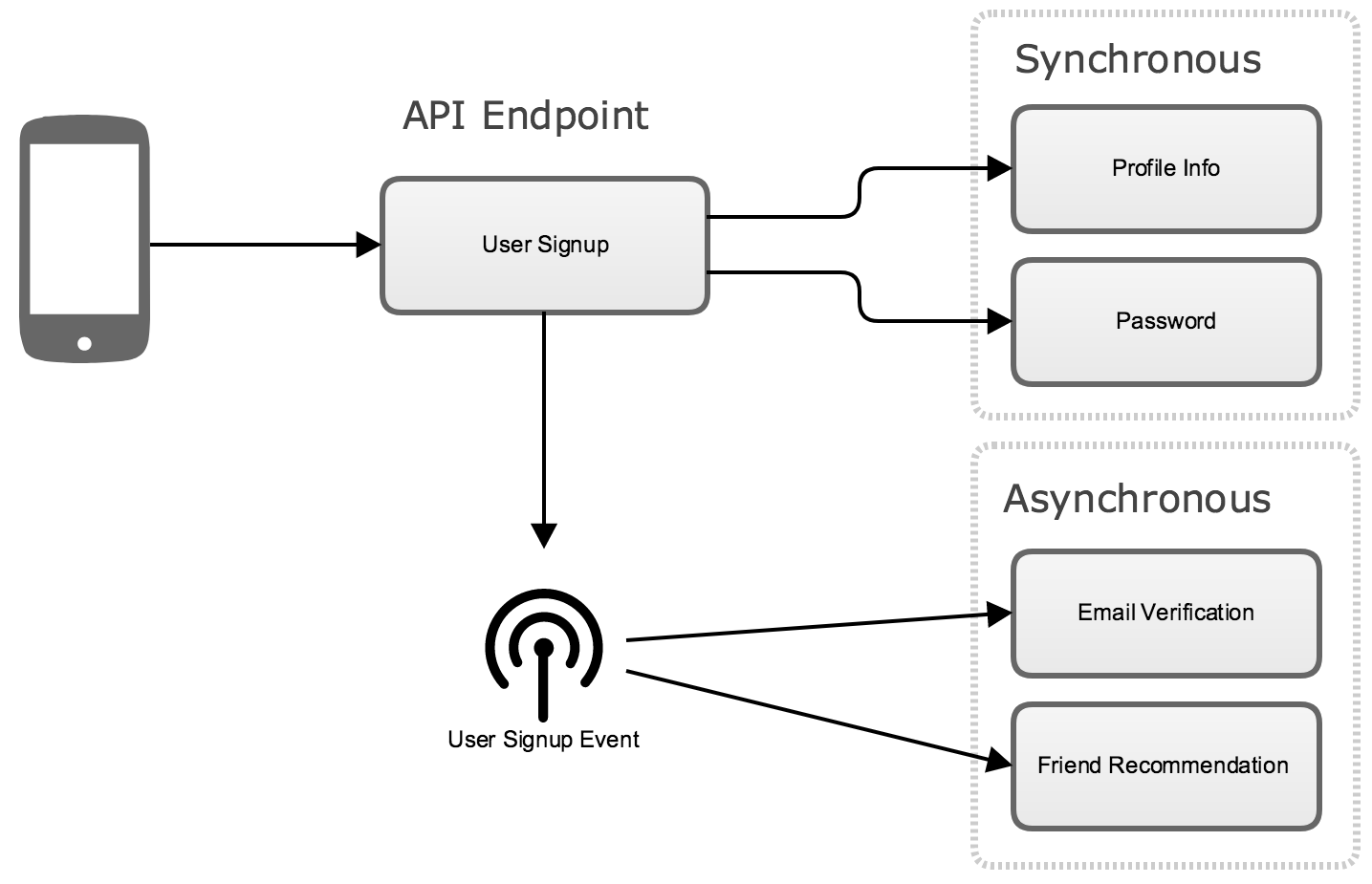
When a user signs up to create an account their client makes a POST request to an API endpoint to send the backend API their basic profile information such as name, password, email address, etc. Because this is a microservices architecture, this initial request fans out calls to several backend microservices that handle the underlying features.
There is a core user metadata service that stores the basic profile information, and a password service that hashes the password plaintext and stores it for later comparison when the user logs in. There are also a couple microservices that run in the background in response to user signup. One emails the user asking them to click a link to verify their email address, while another starts searching for friends to recommend to the user.
The two initial requests to persist the profile info and password are explicit request-response communications. The user signup endpoint can’t return a 200 OK response to the client until both of these pieces of data have been persisted in the backend. On the other hand, the client shouldn’t have to wait for the verification email to be sent out or the friend recommendations to be generated. For these two features it is better to have an observer pattern where the backend services are watching for the user signup event and are triggered asynchronously.
Understanding where and when to use a request-response model versus an observer model is key to designing effective microservice communication.
Anti-pattern: Centralized Service Bus
Building a complex centralized communication bus that runs logic to route and manipulate messages is an architectural pitfall that tends to cause problems later on. Instead, microservices favor a decentralized approach: services use dumb pipes to get messages from one endpoint to another endpoint.
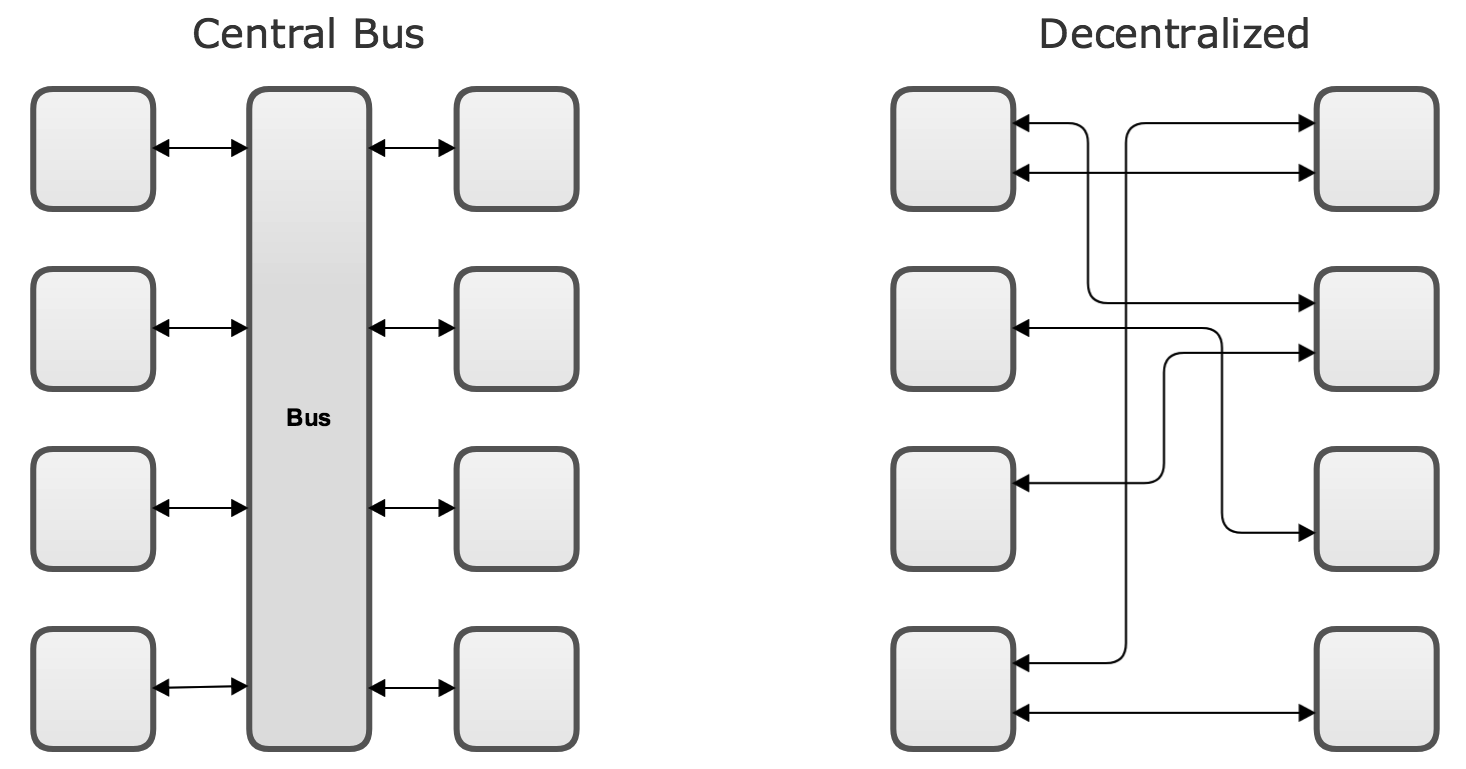
At first glance the diagram of the central bus may seem less scary than the network of many direct connections that result when microservice communication is decentralized. However, it’s important to consider that the same tangle of connections still exists in the central bus. In fact, all those communication routes are now embedded in one monolithic component. This central monolith has a tendency to become excessively complex and can become a bottleneck both from a performance standpoint as well as an engineering standpoint.
Decentralized microservice communications enable engineering teams to do parallel work on different edges of the architecture without breaking other components. If each microservice treats other services as external resources with no differentiation between internal services and third party resources, it means each microservice encapsulates its own logic for formatting its outgoing responses or supplementing its incoming requests. This allows teams to independently add features or modify existing features without needing to modify a central bus. Scaling the microservice communications is also decentralized so that each service can have its own load balancer and scaling logic.
Request-Response Model
Request-response communication between microservices is used anywhere in which one service sends a request and expects either a resource or acknowledgment response to be returned.
The most basic way to implement this pattern is using HTTP, ideally following REST principles. A standard HTTP based communication pipeline between two microservices typically looks like this:
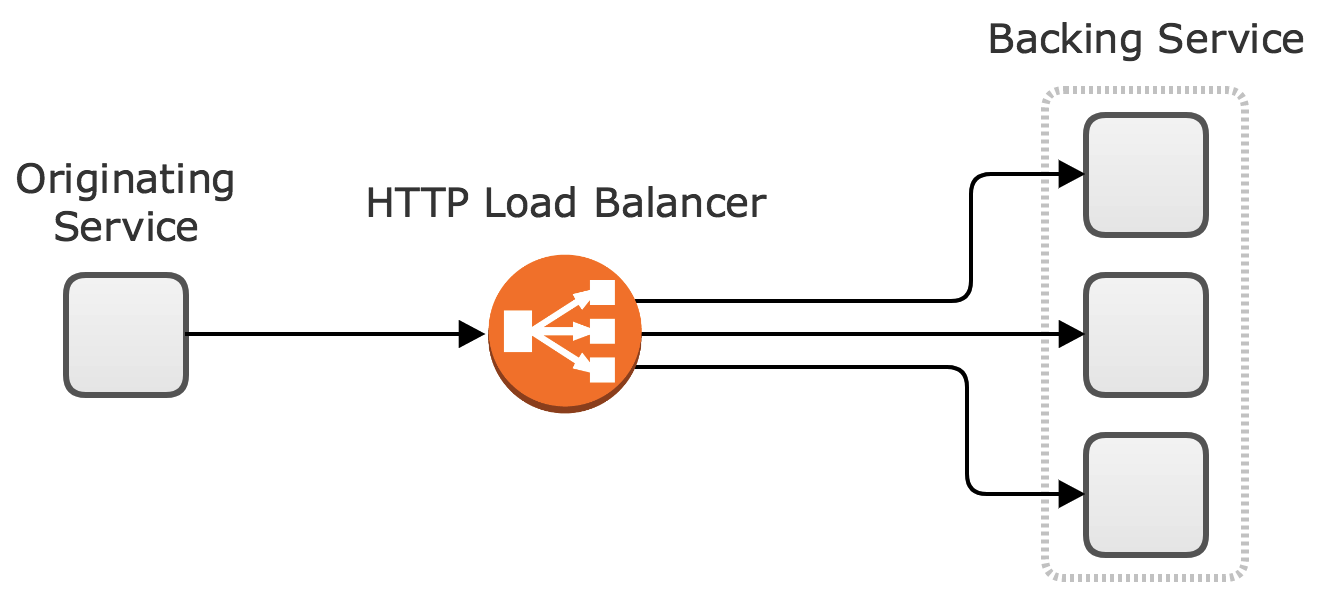
In this approach, a simple load balancer can sit in the middle so that the originating service can make an HTTP request to a load balancer and the load balancer can forward the request to one of the instances of the backing microservice.
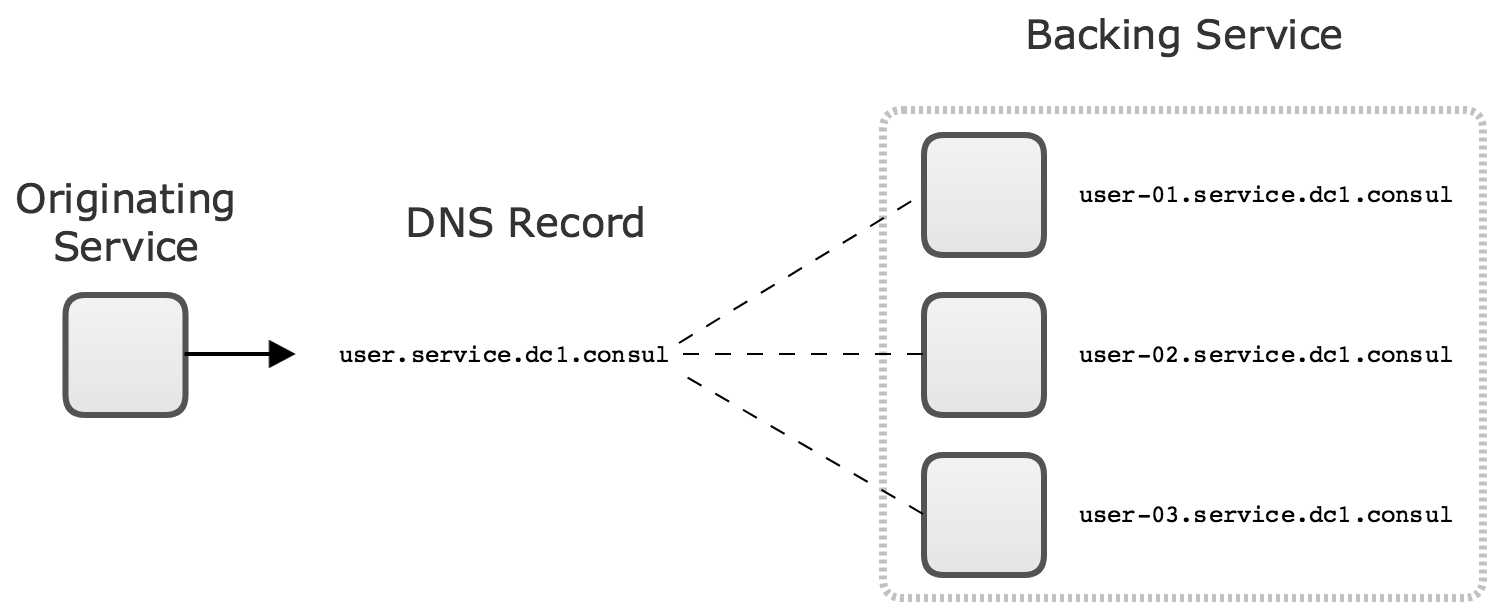
However, in some cases there is extremely high traffic between services, or engineering teams want to reduce latency between microservices as much as possible. In this case they may adopt thick client load balancing. This approach typically uses a system such as Consul, Eureka, or ZooKeeper to keep track of the set of microservice instances and their IP addresses. Then the originating microservice is able to make a request directly to an instance of the backing service that it needs to talk to.
Another framework of note is GRPC, which has emerged as a strong convention for polyglot applications. GRPC can operate using an external load balancer, similar to the HTTP approach above, or it can also use a thick client load balancer. The distinguishing characteristic of GRPC, however, is that it translates communication payloads into a common format called protocol buffers.

Protocol buffers allow backend services to serialize communication payloads into an efficient binary format for travel over the wire, but then deserialize it into the appropriate object model for their specific runtime.
Observer Model
Observer communication is critical to scaling out microservices. Not every communication requires a response or an acknowledgement. In fact, in many workflows there are at least a few pieces of logic that should be fully asynchronous and nonblocking.
The standard way for distributing this type of workload is to pass messages using a broker service, ideally one that implements a queue. RabbitMQ, ZeroMQ, Kafka, or even Redis Pub/Sub can all be used as dumb pipes that allow a microservice to publish an event, while allowing other microservices to subscribe to one or more classes of events that they need to respond to.
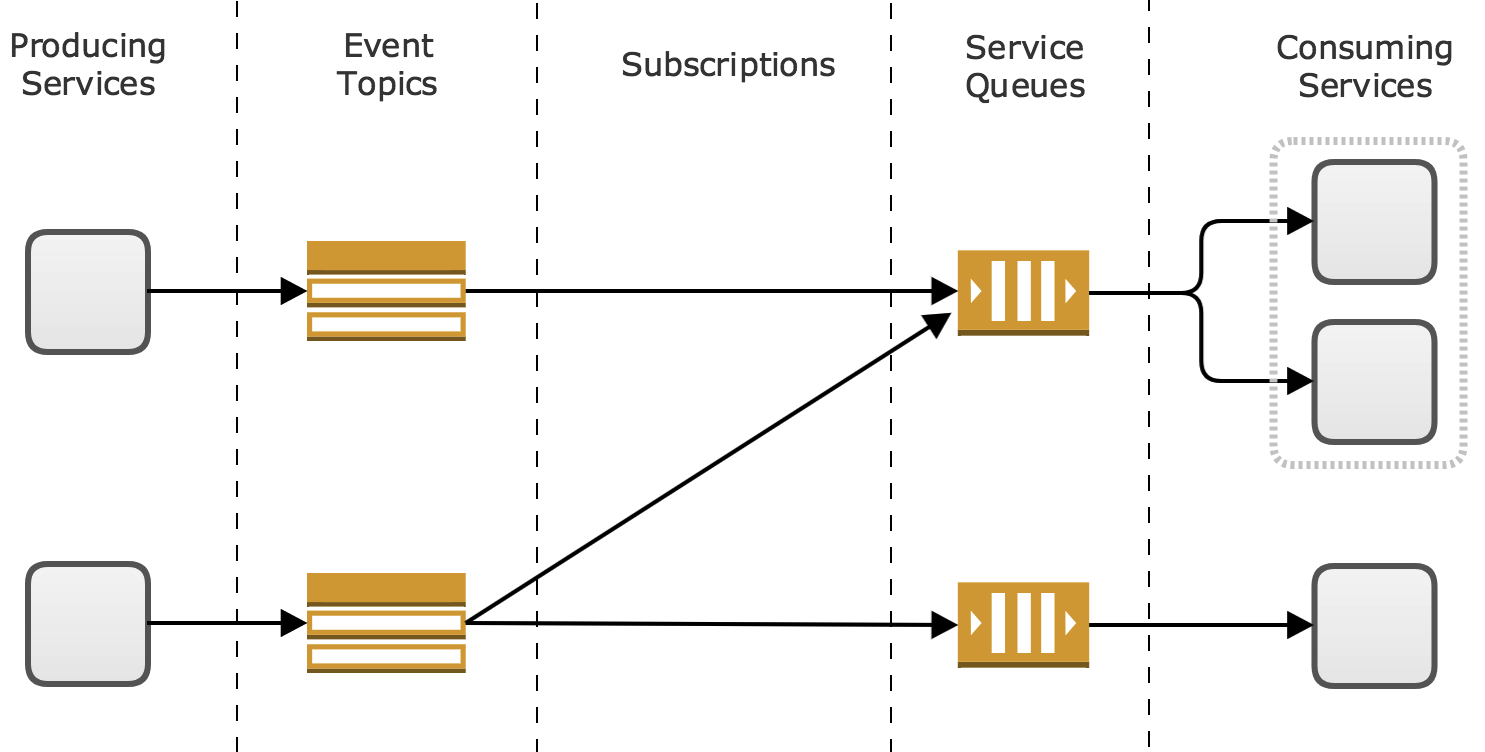
Organizations running workloads on Amazon Web Services often favor using Amazon Simple Notification Service (SNS), and Amazon Simple Queue Service (SQS) as a fully managed solution for broadcast communication. These services allow a producing service to make one request to an SNS topic to broadcast an event, while multiple SQS queues can be subscribed to that topic, with each queue connected to a single microservice that consumes and responds to that event.
The huge advantage of this approach is that a producing service does not need to have any knowledge of how many subscribers there are to the event, or what they are doing in response to the event. In the event of a consumer failure most queuing systems have a retry / redelivery feature to ensure that the message is eventually processed. The producer can just “fire and forget”, trusting that the message broker’s queue will ensure that the message eventually reaches the right consumers. Even if all consumers are too busy to respond to the event immediately, the queue will hold onto the event until a consumer is ready to process it.
Another benefit of the observer model is future extendability of a microservices system. Once an event broadcast is implemented in a producer service, new types of consumers can be added and subscribed to the event after the fact without needing to change the producer. For example, in the social media application at the start of the article there were two consumers subscribed to the user signup event: an email verification service, and a friend recommendation service. Engineers could easily add a third service that responded to the user signup event by emailing all the people who have that new user in their contacts to let them know that a contact signed up. This would require no changes to the user signup service, eliminating the risk that this new feature might break the critical user signup feature.
The observer model is a very powerful tool to have in a microservices deployment, and no microservice architecture can reach its full potential without having at least some observer based communications.
Conclusion
The microservice principle of smart endpoints and dumb pipes is easy to understand when you embrace the concept of decentralization of architecture and logic. Despite using “dumb pipes” microservices can still implement essential messaging primitives without the need for a centralized service bus. Instead, microservices should make use of the broad ecosystem of frameworks that exist as dumb pipes for both request-response and observer communications.