
Scaling a realtime chat app on AWS using Socket.io, Redis, and AWS Fargate
In the last article we deployed a realtime chat application using AWS Fargate. The result was a containerized Node.js process running a socket.io server. This container runs in AWS Fargate without needing a single EC2 server on the AWS account.
But one of the missing pieces in that first article is scaling. Ideally this application should be able to handle many connected clients at the same time, and dynamically adapt as more and more clients connect. This article will show the process of extending the application to automatically scale up as more people use it. You can follow along with the code in the open source repo where the application in this article is being developed:
https://github.com/nathanpeck/socket.io-chat-fargate
Identifying what we need in order to scale
At the end of the first article the architecture for the application looks like this:
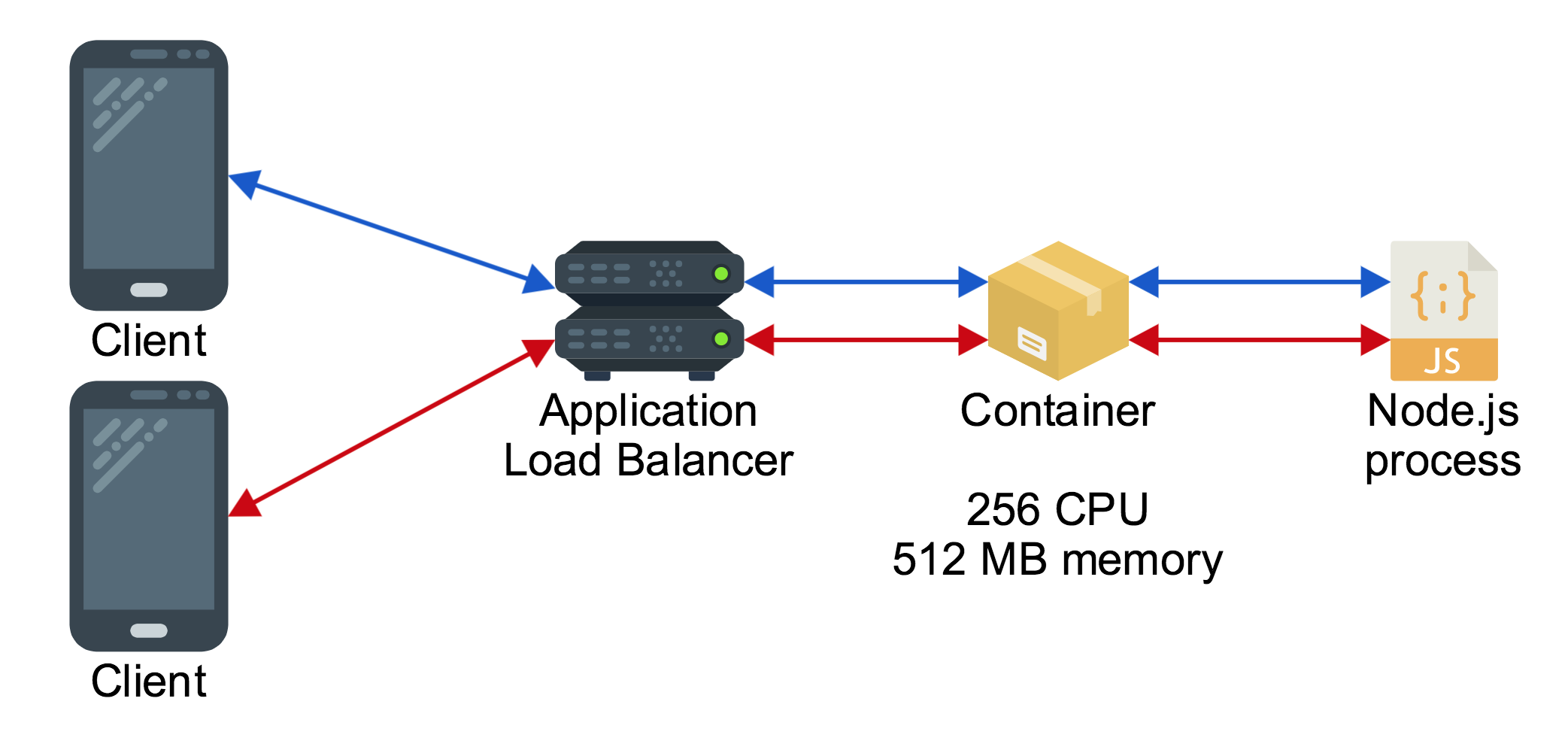
Despite having a load balancer, there is only one container behind it, so all clients connected to the load balancer are being served by the same process. This puts some limits on how many clients can connect to the application, because the more clients connect to the load balancer the more they will be contending for the limited amount of CPU and memory available to that single container behind the load balancer.
There are two ways we can scale the application to handle more traffic:
Vertical Scaling
When you scale vertically it means that giving the application more resources to work with without increasing the number of workers. So instead of giving the server process 256 CPU (the equivalent of 1/4th of a core) we can give it 1024 CPU (the equivalent of one whole core). This will allow the Node.js process to serve more concurrent clients.
But there is an upper ceiling to how many more clients we can serve by scaling vertically. For Node.js, because the flow of execution in the program is single threaded we can’t get very much use out of more than one core of processor power. (In reality the internals of Node.js itself are multithreaded so it can utilize more than one core at full load, but the actual execution of our business logic code is limited.) So if we need to handle more clients we need more than just vertical scaling.
Horizontal Scaling
When you scale horizontally it means running more copies of the application which can work in parallel with each other, each with their own vertical resource allocation. Then client connections are distributed across each of these copies of the application.
This ends up being a more effective way of scaling because it is easy to dial up the number of application instances even when the application has reached its limits vertically.
So with this understanding of scaling techniques it’s clear that we want something like this:
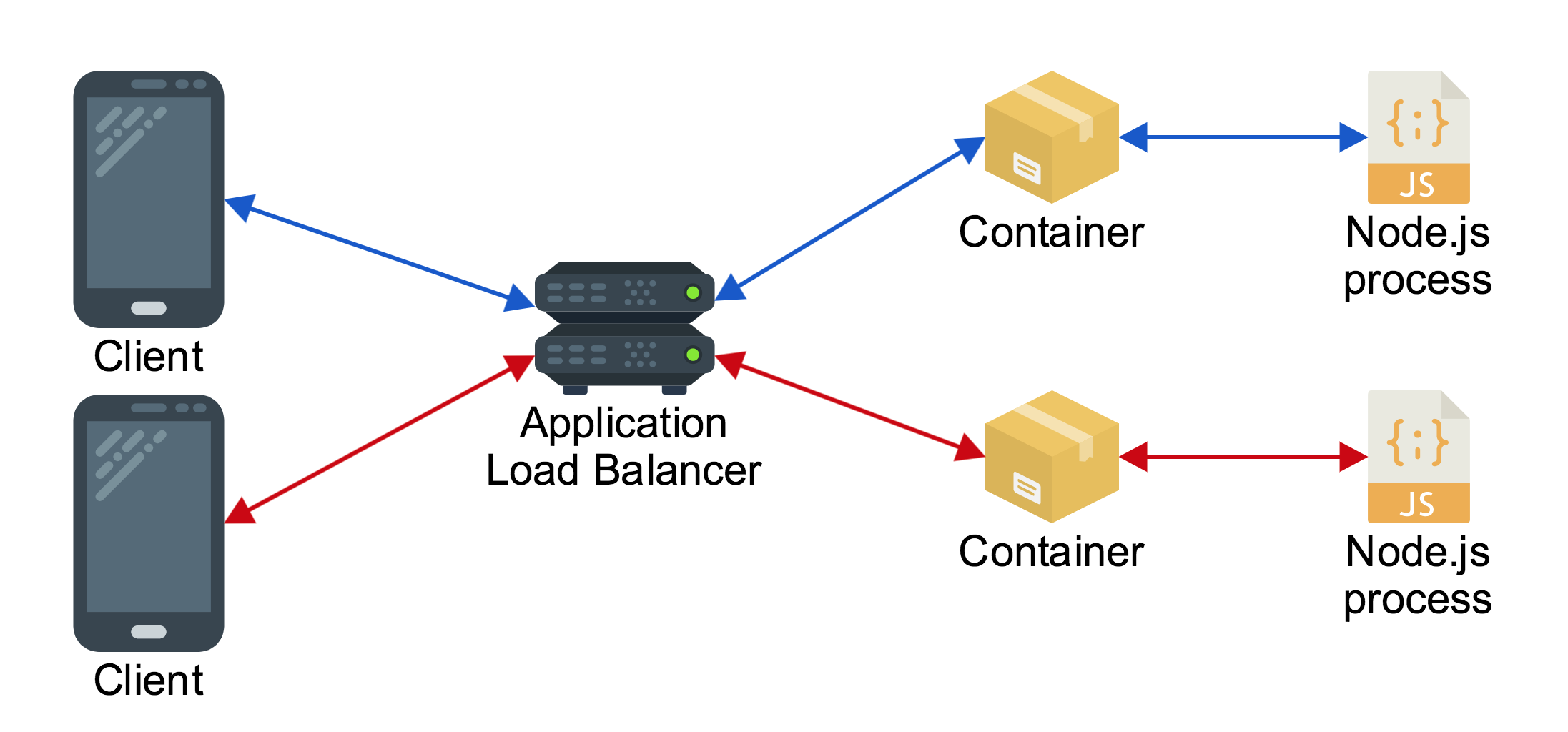
The only problem is that out of the box this deployment will not function as we expect if the code is deployed with zero changes. The intended behavior of this application is that people who send messages will see each other’s messages, but if two clients are connected to different server processes they will only see the messages of other people who are connected to that process, not every single message.
To solve this problem we can make use of the socket.io-redis adaptor, which uses Redis as a message broker to pass messages between each Node.js process. The result looks like this:
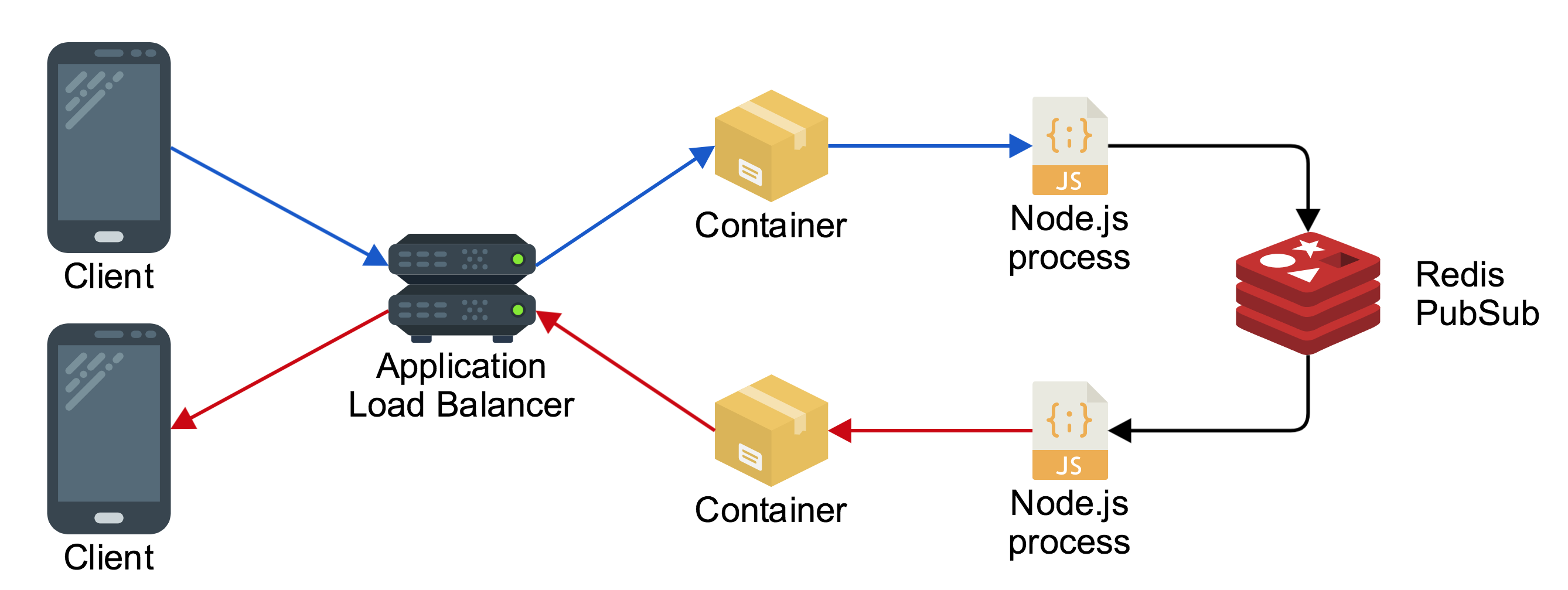
A client connected through the load balancer sends a message to one Node.js process in one container, and it broadcasts the message using Redis to the other Node.js process, which sends the message back down to the other connected client.
Setting up horizontal scaling locally
Implementing the Redis adaptor in our socket.io powered application is just a few lines of added code to the index.js file:
There is one important thing to understand in this code, and that is how to configure the Redis adaptor. Rather than hardcoding the address of a Redis server it is better to use an environment variable, in order to follow twelve-factor app standards. This allows building and running the same docker container both locally for testing, and in production on AWS.
There is one other thing that must be fixed in order for this app to function properly when horizontally scaled. If you look at the code in the original demo application it is storing the count of connected users in the process memory as a variable, and it just increments whenever someone joins, and decrements when they leave:
This won’t work if there are multiple processes because each would have their own count of connected users and would only be able to show the count of the fraction of the connections that is connected to that particular process. Instead its necessary to add some code to use Redis to keep track of the connection count as well.
With the necessary adjustments made to the code you can test out the setup locally with the following commands:
git checkout 4-scaling
docker build -t chat .
docker network create chatapp
docker run -d --net=chatapp --name redis redis
docker run -d --net=chatapp --name chat1 -p 3000:3000 -e "REDIS_ENDPOINT=redis" chat
docker run -d --net=chatapp --name chat2 -p 3001:3000 -e "REDIS_ENDPOINT=redis" chat
This creates a network for the three containers to be run in. The network allows containers to talk to each other by using their hostnames. The next step is to launch the Redis container, and two copies of the chat container, bound to different ports. Additionally when launching the chat containers we use a flag to pass the hostname of the Redis server in as an environment variable.
If you run docker ps you see three containers running:

And you can open two browser tabs, one connected to localhost:3000 and one connected to localhost:3001
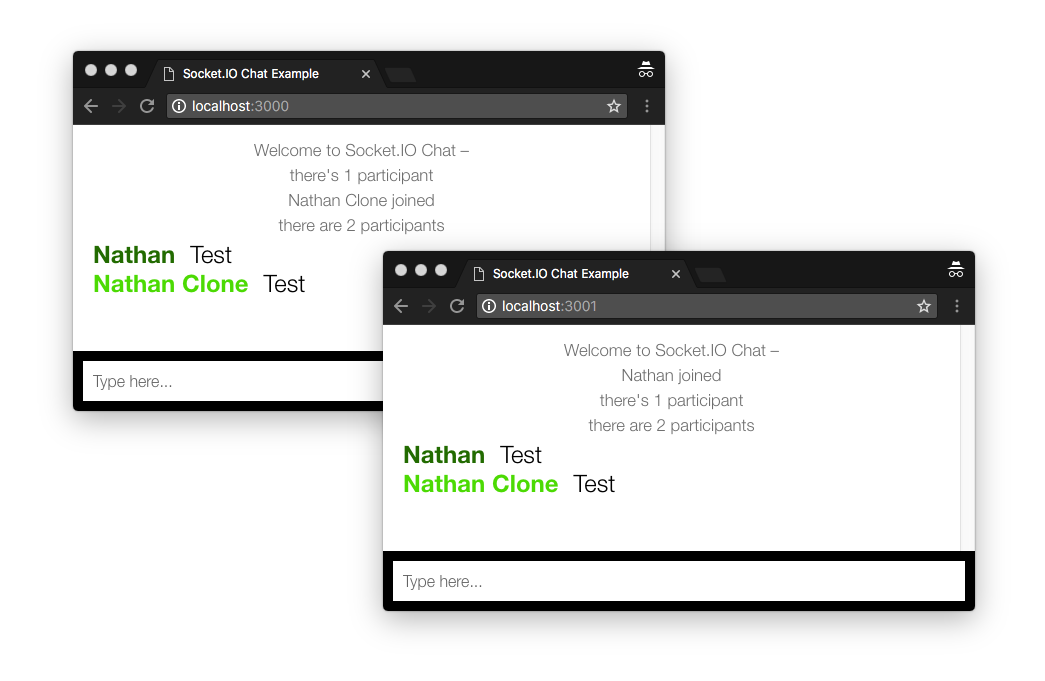
As expected when a message is sent to one process it shows up in the client connected to the other process, and the participant count is accurate as well.
Deploying on AWS Fargate behind ALB
Now that all the pieces for horizontally scaling are running locally, a little bit of AWS specific prep work is needed for horizontal scaling.
First of all we need to run a Redis server on AWS, just like the Redis that is running locally. For this architecture let’s use Amazon Elasticache to run Redis. This service hosts a secure, Amazon managed Redis server in the same VPC as the Fargate containers. A security group allows the containers to connect to Redis:
You can deploy the recipes/resources.yml to deploy an Elasticache Redis which the Fargate containers can connect to. This template also exports a variable RedisEndpoint which is the address that the containers need to connect to. Just like an environment variable is used locally to tell the docker container where to connect, the docker container runnin in AWS needs the same environment variable. This is specified in the task definition, which is defined at recipes/chat-service.yml
This tells Amazon that when it launches the docker container in AWS Fargate it should add the REDIS_ENDPOINT environment variable with a value imported from the recipes/resources.yml stack you launched earlier.
One more step for this application to work properly is to configure the load balancer to use sticky sessions. This is necessary because socket.io makes one request to set a connection ID, and a subsequent upgrade request to establish the long lived websocket connection. These two requests must go to the same backend process, but by default the load balancer will send the two requests to random processes, so the connection will be unstable.
We can fix this by setting the stickiness.enabled flag on the target group for the service:
Rebuild and push the application again as we did in the previous article:
docker build -t chat .
docker tag chat:latest 209640446841.dkr.ecr.us-east-1.amazonaws.com/chat:v2
docker push 209640446841.dkr.ecr.us-east-1.amazonaws.com/chat:v2
Then using the CloudFormation template at recipes/chat-service.yml you can redeploy the service. This time use the new ImageUrl and set the DesiredCount to two instead of one. I also choose to vertically scale the containers to have one entire core and 2 GB of memory:
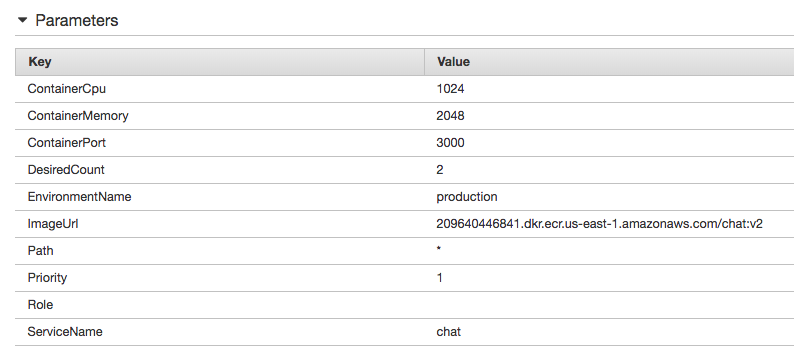
Enabling AutoScaling for the Application
There is one more step before we can truly consider this application production ready, and that is enabling autoscaling. Now that the application can horizontally scale there are two running instances of the service, but if traffic increases it should be able to automatically scale up and run more than two without any human intervention. This is accomplished by using the following AWS services:
- Amazon Elastic Container Service (Responsible for capturing metrics about the running containers and putting those metrics into Amazon CloudWatch)
- Amazon CloudWatch (Responsible for storing container metrics and watching over the metrics via CloudWatch alarms)
- Amazon Application AutoScaling (Allows you to build a scaling policy and attach it to an Amazon CloudWatch alarm, such that if the alarm goes off the scaling policy executes)
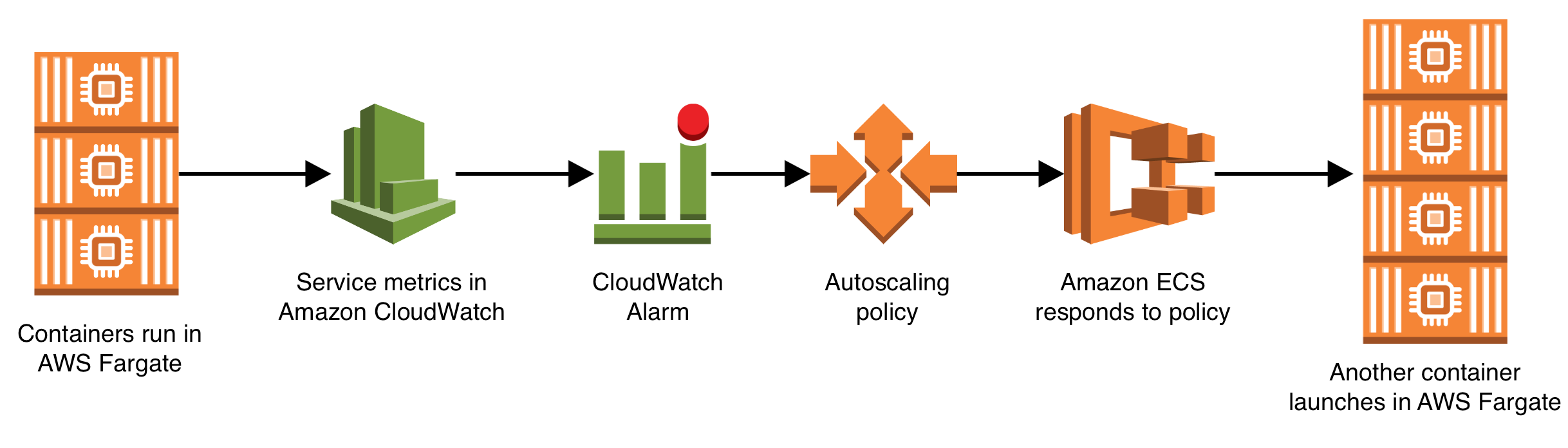
You should checkout the full Gist of the CloudFormation resources for enabling autoscaling. To summarize: it creates a scalable target for the service running in AWS Fargate, two alarms (one for high CPU usage, and one for low CPU usage), and two scaling policies (one for how to scale up, and one for how to scale down). The definition is quite verbose, but it gives an incredible amount of control over exactly how the scaling works, including the ability to create a step scaling policy, where the number of containers increases by a large amount if the CPU usage metric has breached the target threshold by a larger amount.
Conclusion
In this installment we added on all the resources necessary to take our realtime chat application from a single process deployment to a horizontally scalable service running in AWS Fargate, and backed by an AWS managed Redis. As load increases on the service and CPU usage increases the application will automatically scale up and run more instances of itself, and when CPU usage decreases it will automatically scale down.
And once again everything in this architecture operates without a single EC2 instance on the account!

There is nothing to manage or maintain on this AWS account except for the application code itself. If you want to try this architecture out you can get the full open source code for this application, and the CloudFormation templates to launch it:
https://github.com/nathanpeck/socket.io-chat-fargate
Or try out a live demo of the current state of the application:
In the next installment of this series we will explore how to use IAM roles to authorize containers running in AWS Fargate to access other AWS resources on your account. To demo this I’ll add a DynamoDB table for serverless persistence of chat messages that are sent in the application.