
Why should I use an orchestrator like Kubernetes, Amazon ECS, or Hashicorp Nomad?
If you work in software development for the cloud you have probably heard of infrastructure orchestrators such as Kubernetes, Amazon Elastic Container Service, or Hashicorp Nomad.
But why would you need to use one of these orchestrators? Do they make your life easier or more complex?
In this article I’ll discuss the stages of infrastructure management to explain the origins of orchestration, why it exists, and why you might consider using it.
The Solo Developer
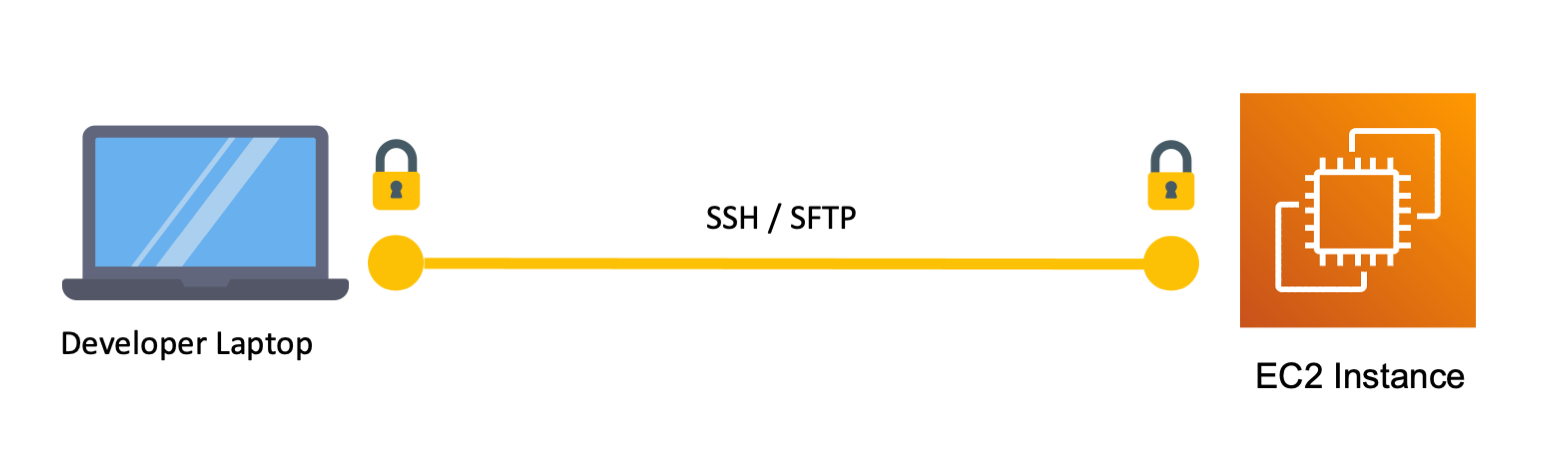
You write code and test it by running it locally on your own developer laptop. But you want other people to be able to use your application, so you need to run it on a server on the internet.
There are a few tools you can use to upload your application to an internet server:
sshis a tool to open a command line that is connected to another machine on the internet. Normally when you run commands in the command line they run on your local machine. When using SSH these commands will run on the remote server instead.scpstands for “secure copy”. It is a command line tool that helps you securely copy files from your local machine to a server, using the SSH protocol.gitis a solution for versioning source code and backing it up. You can use services like GitHub or GitLab as a centralized repository for your source code. Withgityou can then upload the source code off of your dev machine to the remote repository and then usegiton the internet server to download the source code from the repository onto the server.
Next steps: People like your application and start using it. Now you need to run your application on multiple servers. Alternatively you just want to run copies of your application on a couple servers for redundancy, so that if one copy crashes the other will still be running.
Adding more servers
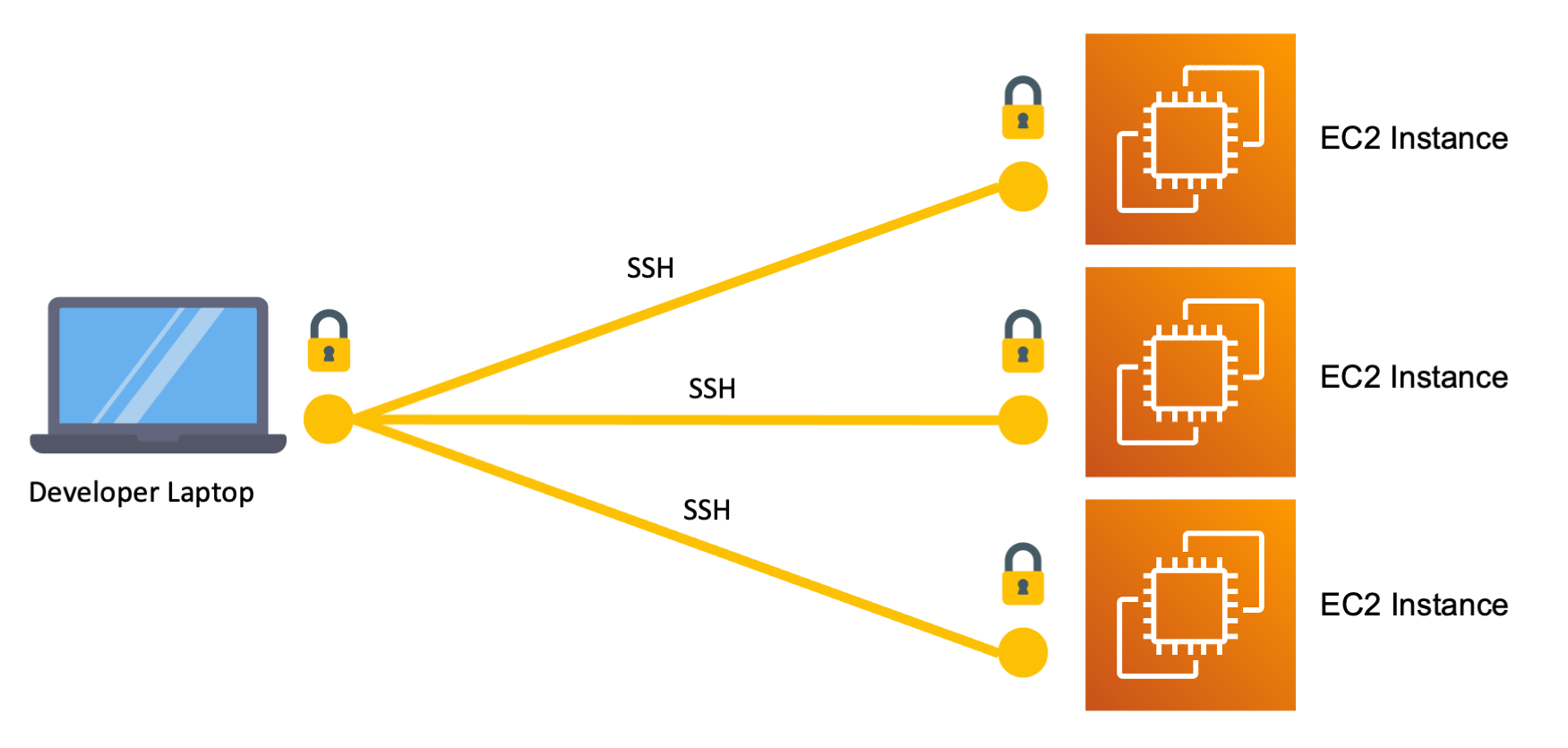
Now that you have more servers to upload your code to it is getting annoying to run multiple ssh, scp, or git commands for each host. You want to run one deploy command and update all the hosts at once.
This is where you start to build automation. You may choose to write your own shell script so you can just run deploy.sh to do the deployment. Or you might choose to use a more powerful tool like Chef, or HashiCorp Vagrant or Packer. Whatever way you choose, you now have a tool which can help you deploy to a list of servers, but that tool still runs from locally on your own laptop.
Next steps: The application and its codebase are getting larger. Your team wants to hire more developers. The problem is you are the only one who has the deploy tool working properly. You go on vacation and now no one is able to deploy to production to fix a bug because they aren’t running the right version of the deploy tooling or they don’t have the right access keys.
Alternatively you do manage to get everyone on the team set up with the right version of the deploy tooling and the right access but now you have conflicts where person A kicks off a deploy, but then person B was trying to kick off a deploy at the same time, and the two deployments conflict with each other and break everything!
Adding more developers
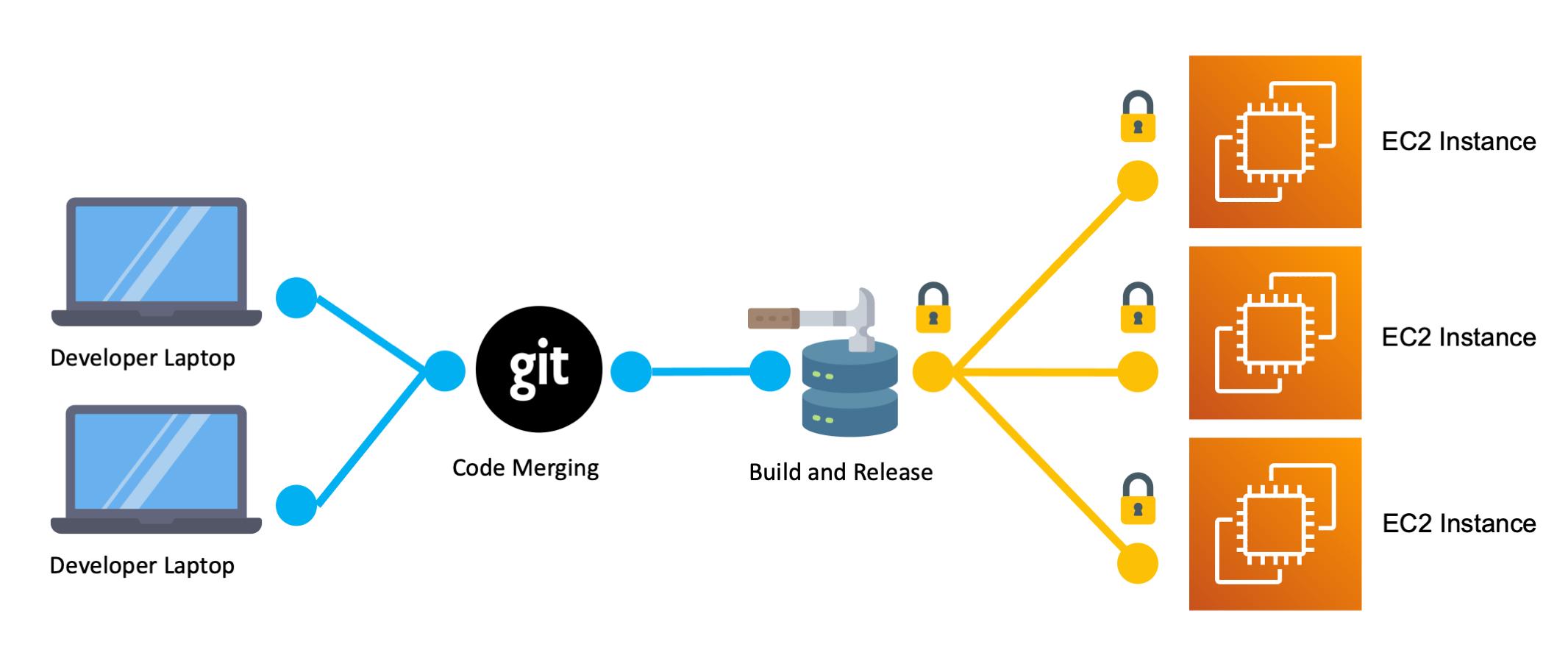
To solve these problems and to make it easier for multiple developers to work together you make git part of the release process, and introduce code merging and an automated code release server. Now developers merge their code together using git before release, rather than just running releases from their own dev machines. This allows conflicts to be
resolved before they cause problems. You can also use pull requests so that code can be reviewed before it gets merged in.
But most importantly developers no longer have to start deployments manually. The build and deploy server is a service that watches your git repository for changes. It is looking for new commits that are pushed to the git repository, reviewed, and merged in. When it sees this happen it pulls the code down onto the build server, runs any build scripts such as npm install or go build, and then the server automates uploading all the built code to all of your servers.
There are a variety of tools you can use for this, but they might include: Github Actions, your own self run service like Jenkins, or a managed service like CircleCI, or AWS CodePipeline and CodeBuild.
This centralized build and deploy server is now automating the release and all developers have to do is push and merge their code into the code repository in order to deploy.
Next steps: The deploy server only does a deploy to your servers when there is a change to the code. However, you now want the servers to be dynamic. During the day your application has high traffic so you want to increase the number of servers, while at night you have low traffic and you want to decrease the number of servers. Additionally, you occasionally may want to terminate a server, or replace it. It is frustrating to have to go back and kick off another deploy or update the deploy process to account for the changes to the server infrastructure capacity.
Making infrastructure capacity dynamic
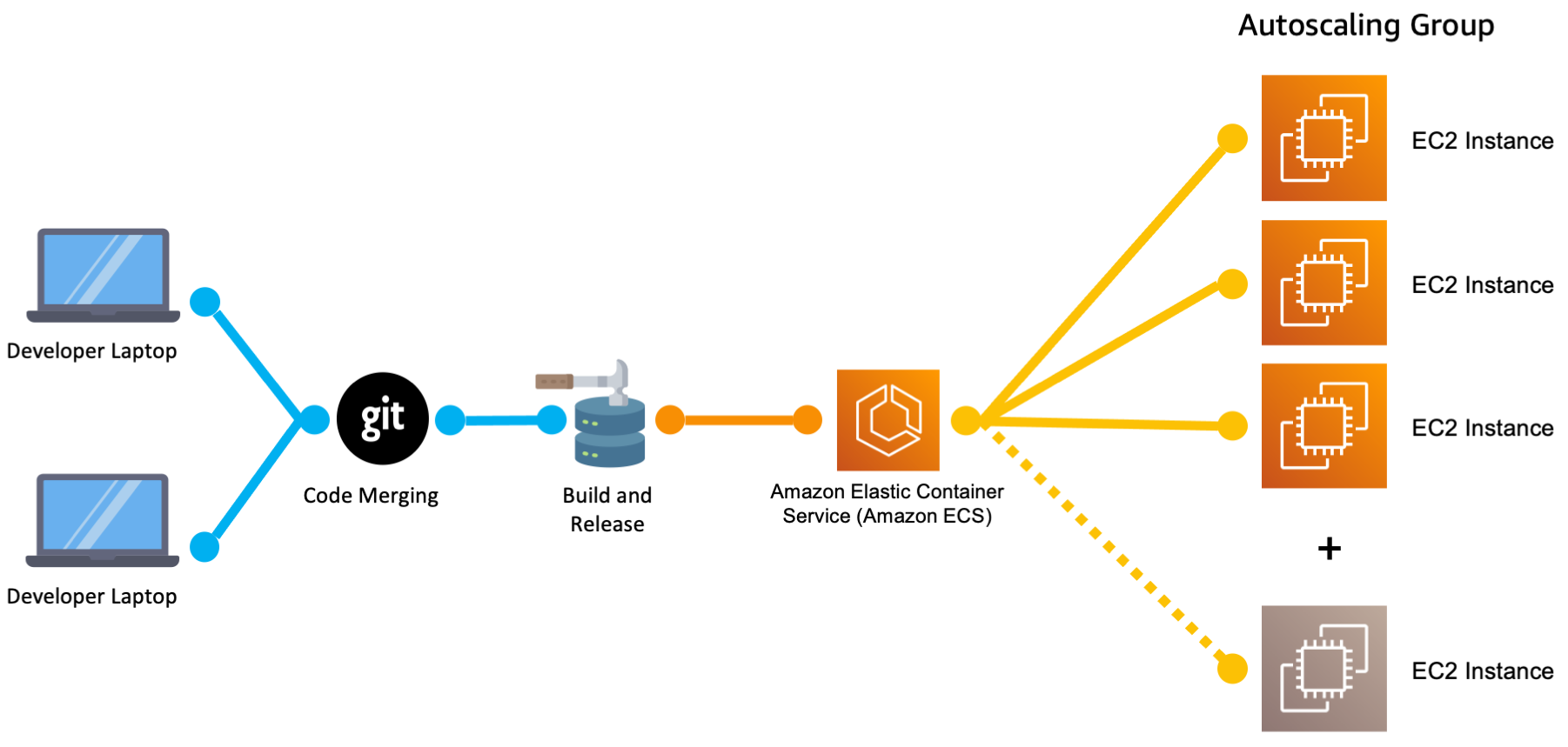
An orchestrator sits between the build server and the actual server capacity. In the diagram above it shows Amazon Elastic Container Service as the orchestrator, but you could also use Kubernetes, or Hashicorp Nomad.
No matter which orchestrator you use, the orchestrator is responsible for continuously monitoring the servers and the application (or applications) running on the servers. The orchestrator is proactive in adjusting to changing infrastructure circumstances.
For example if a copy of the application crashes, then the orchestrator will restart it. If a server suffers a hardware failure and stops working, the orchestrator can launch a new copy of the application onto a different server. If you add or remove servers from the pool of capacity the orchestrator can spread the application across more servers, or squeeze multiple copies of the application onto a single server.
Best of all you can now also use the same orchestrator and the same infrastructure capacity for multiple applications:
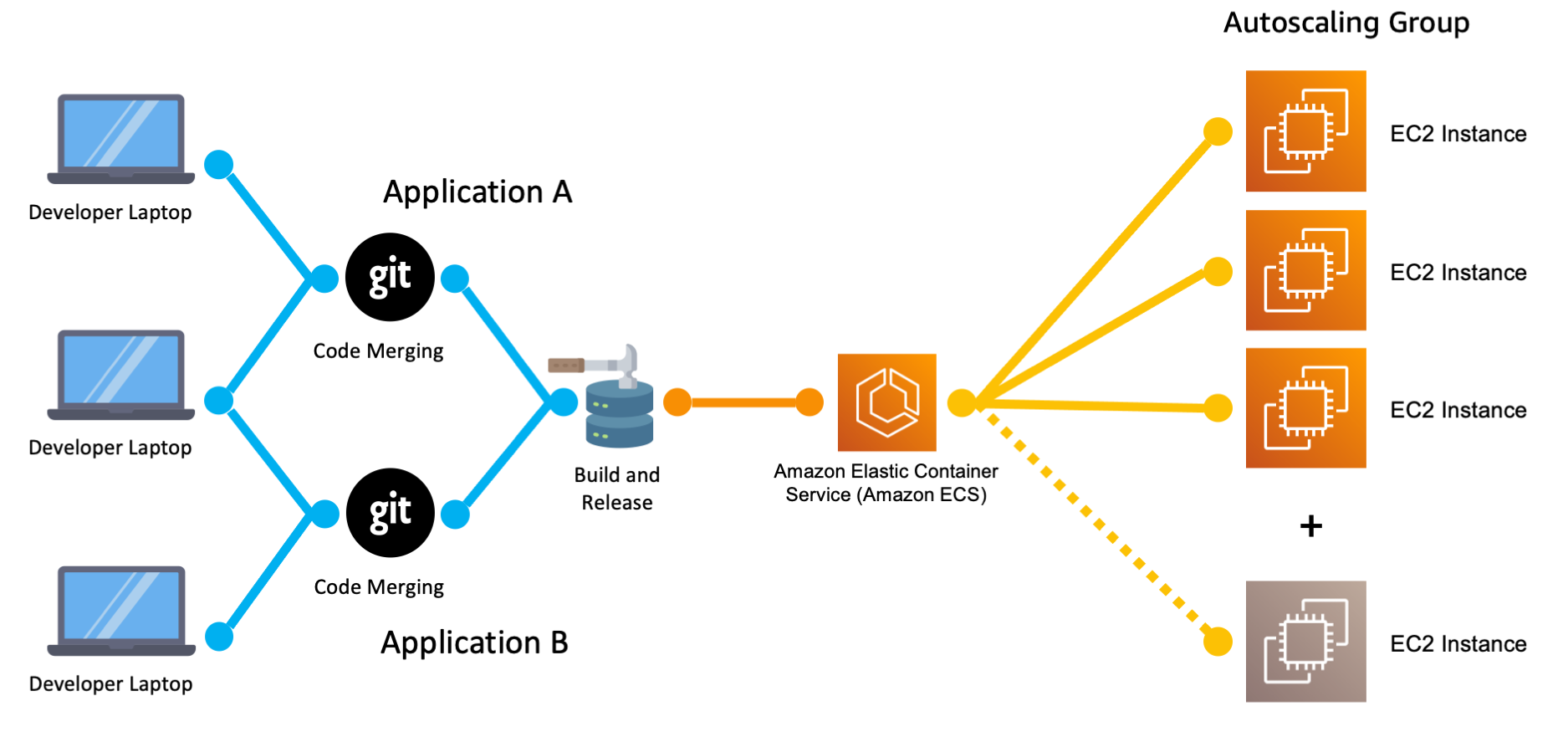
As the application gets larger you find that some portions of it are better suited to be split off into their own microservices. This isn’t a problem because you have an orchestrator that can easily launch, and keep track of multiple applications across multiple servers.
No matter which orchestrator you use it will reduce operational overhead for humans because it continually functions in the background, 24/7, ensuring that your applications get launched and stay running on your compute capacity.
What stage of orchestration are you at?
It is totally okay to start out with manual, human driven orchestration if that is all you need.
But it is also nice to know that if you run into challenges as you continue to build and scale your development operations, then there are tools to help you reach the next stage of infrastructure management.
Hopefully this article helps you understand what those stages are, what tools are available at each stage, and what tools to consider for future usage!
If you have any questions or comments please reach out to me on Bluesky.
You can also download the source file for the diagrams in this post: