
Improving Observability with AWS App Mesh and Amazon ECS
I delivered this session as part of AWS re:Invent 2020. You can find the recording, PowerPoint deck, and transcript below.
Transcript
Hey everyone. My name is Nathan Peck and I work as a senior developer advocate at Amazon Web Services. Today, I’m going to be presenting to you on how you can improve observability for your applications using AWS App Mesh and Amazon ECS. By the end of the session, my hope is that you’ll be able to answer a few questions.
- What is observability anyway?
- What is Amazon Elastic Container Service?
- And what is AWS App Mesh?
- What observability pieces does Amazon ECS supply?
- What observability pieces can I get from AWS App Mesh?
And then I’m going to show a little look at what all these pieces look like when they’re put together.
So to start with, let’s consider that question of “what is observability anyway?” And to do so let’s imagine a hypothetical scenario where you’ve joined a company and as part of your onboarding, they tell you your job is to take care of a magic box.
So naturally you ask them, “Okay. What is this magic box, and what does it do?”
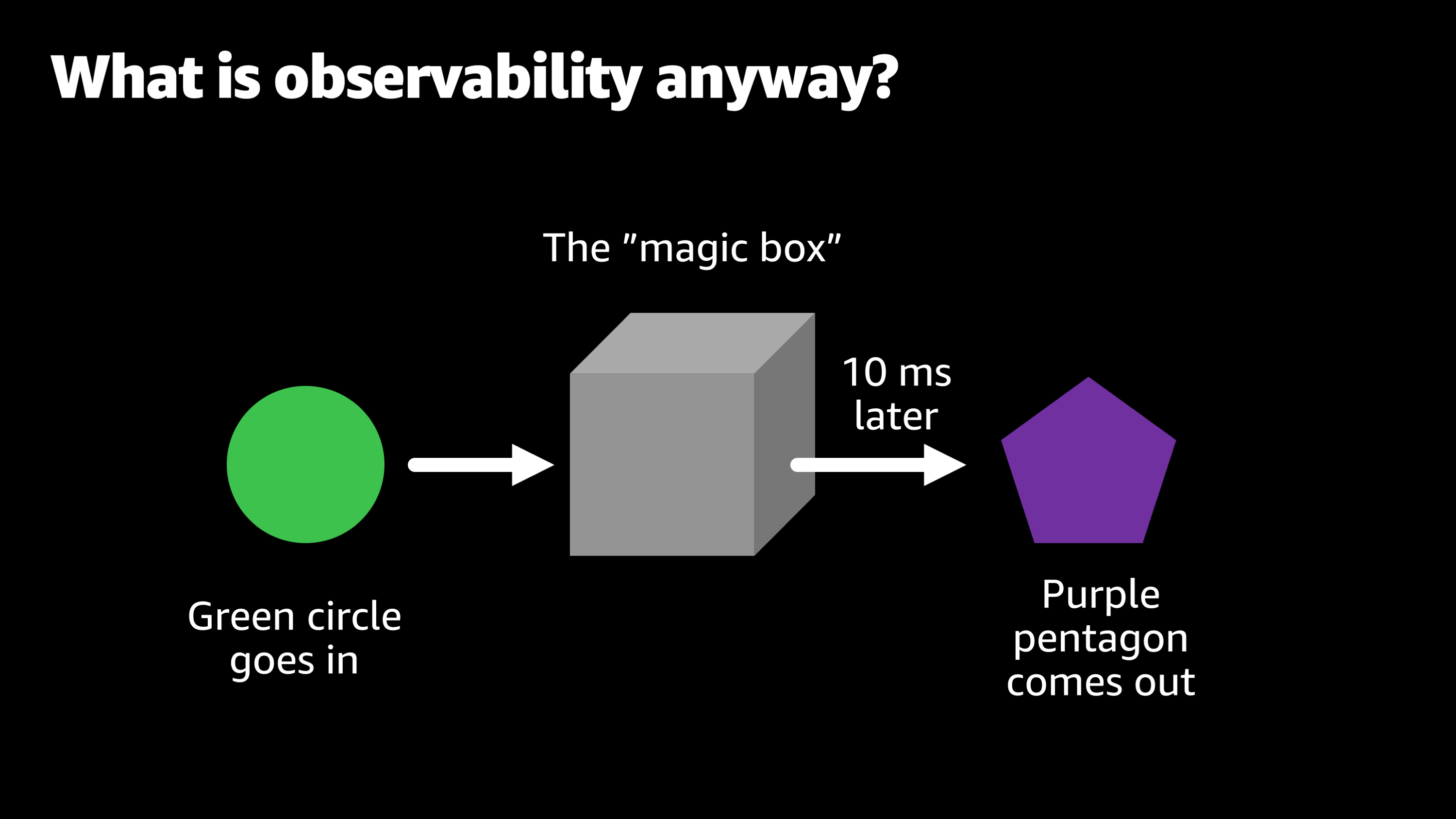
So they say, “Well, the magic box, the way it works is we put a green circle in and then roughly 10 milliseconds later, a purple Pentagon comes out. And we really want you to keep this box functioning. We want to keep turning those green circles into purple pentagons. But unfortunately the people who built this magic box, they left the company a while ago. We don’t really know how the magic box works anymore. They didn’t leave great documentation, so it’s up to you now. You’re going to have to figure out how to keep this box running.”
Now, I know some of you in the audience are probably thinking, “Wow, is this guy actually talking about me?”
If this scenario sounds very familiar to you, I’ve got good news. I’m going to share some things that will make your life easier and help you to solve this particular problem.
But first, let’s go back to this magic box and talk about a few more of the different types of problems that you might have with this magic box.
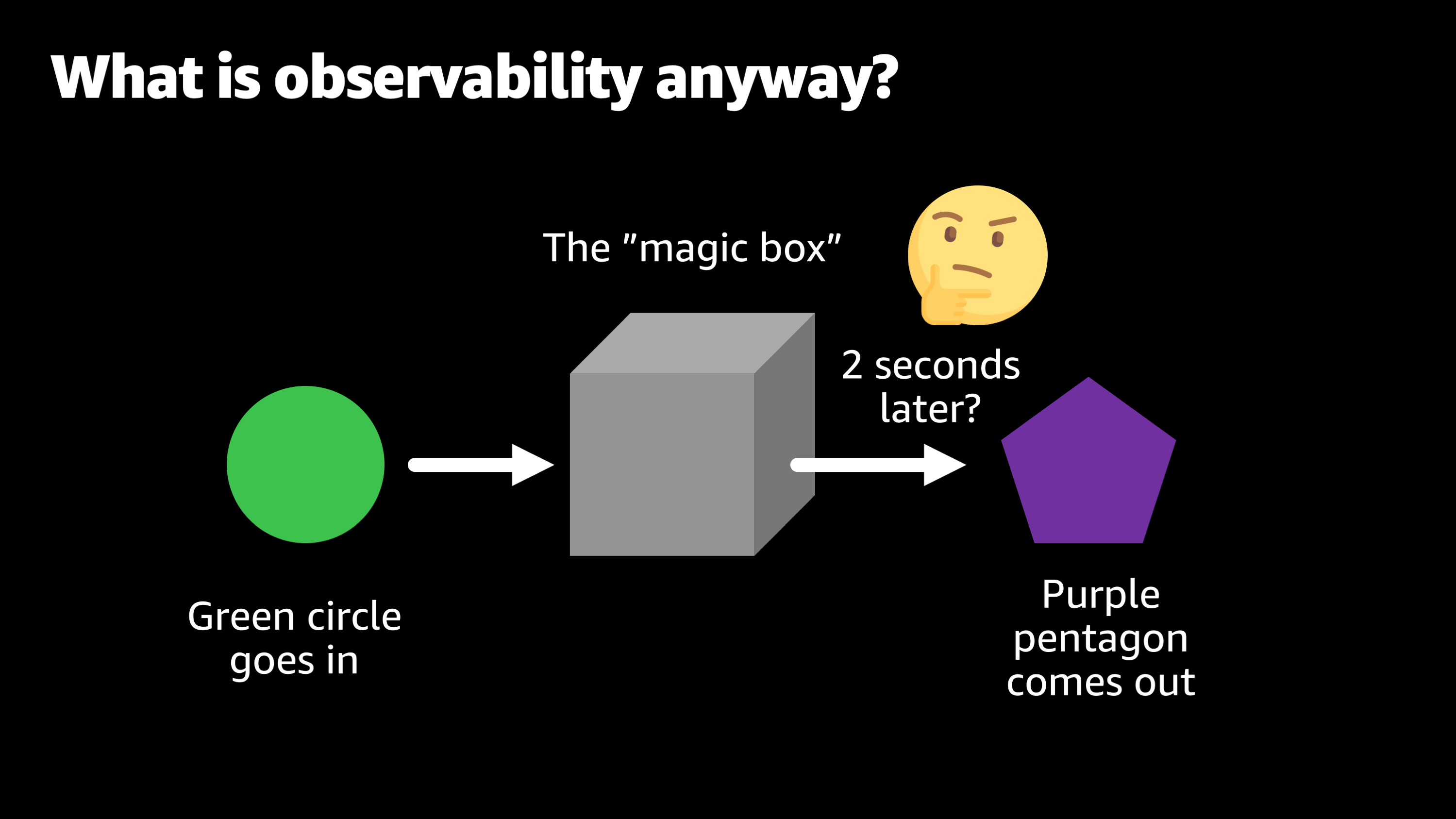
So, one day you’re watching the magic box at work and it’s working at its normal and then, all of a sudden you notice that you put a green circle in and it takes two seconds before that purple Pentagon comes up. So you’re thinking to yourself, “Wow, that’s weird. What should I do to solve this? Should I do anything? Maybe it’ll resolve itself.”
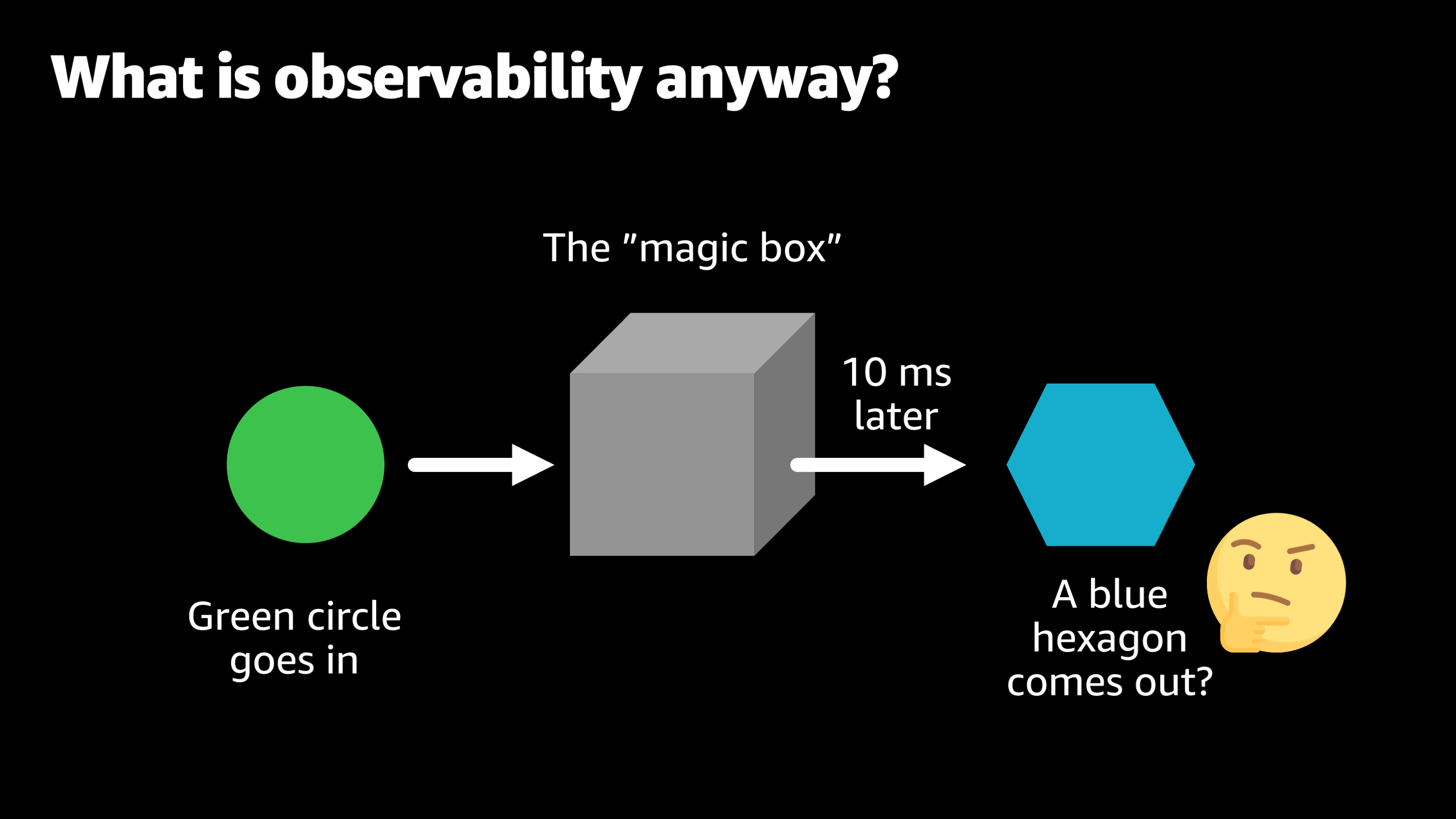
And luckily it does resolve itself, but then the next day you’re watching the magic box and you put the green circle in and 10 milliseconds later, a blue hexagon comes out. So now you’re thinking, “Okay, that’s not really not good. That’s not supposed to happen. What should we do? Should we kick the box? Should we wait again and see if it goes back to normal on its own?”
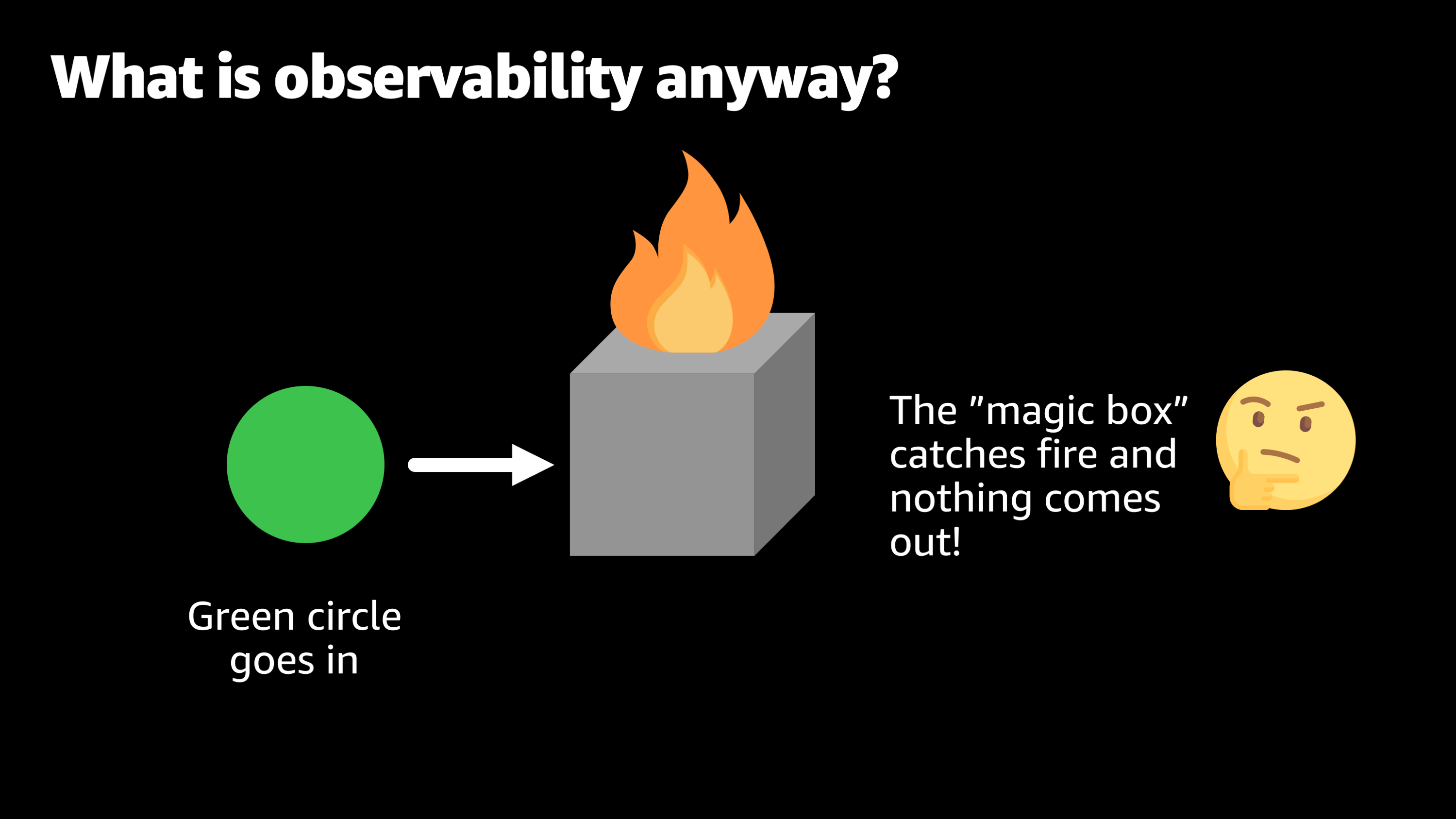
The next day you put the green circle in, and this time the magic box just catches fire and nothing comes out of the box.
So now things are really going bad. Customers are mad. Green circles are just piling up. No one knows how to fix the magic box. And there’s definitely no purple pentagons being created.
Even worse, your customers for the company are now taking the green circles to a different person. They’re taking them to a competitor.
So, what was the problem here?

Well, the problem was there was no observability. When it comes to that magical box, we don’t know what’s in the box. We don’t know why it behaves the way it does. When its behavior changes, we don’t know why it changed, and we don’t know, most importantly, what needs to be done in order to make that behavior more consistent.
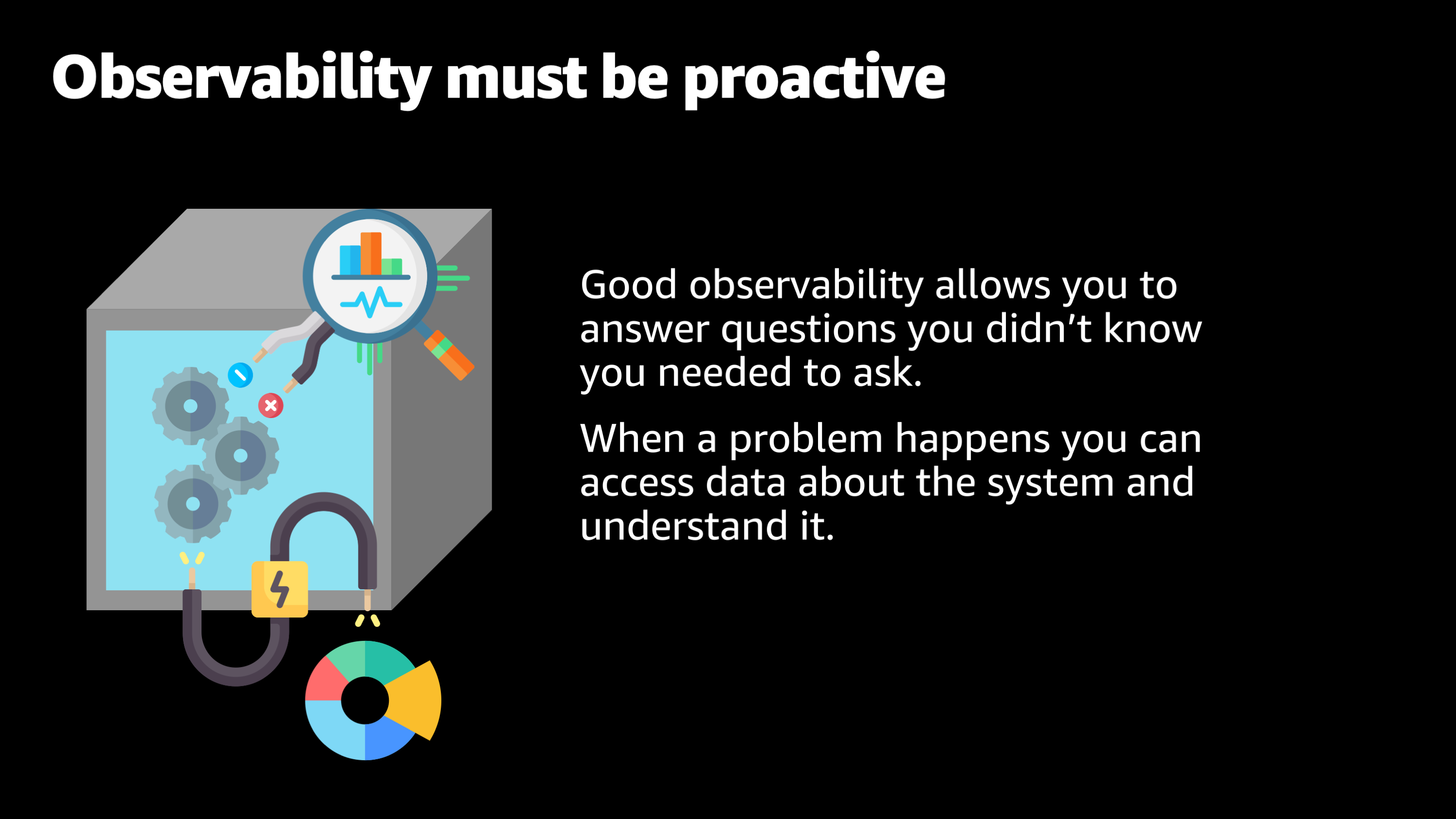
So, observability is the solution to these problems. And the one key thing I want you to get out of this session is this statement: Good observability allows you to answer questions you didn’t know you needed to ask.
So the idea is that when a problem happens such as a delay, an unexpected response, or an error or crash, it allows you to answer that question of why that happened and more importantly, how we can fix it and prevent that from happening again in the future.
This observability has to be proactive. It can’t be something where you wait until a problem occurs, and then you add observability. Observability needs to be something that you set up ahead of time, and it’s always sitting there and ready to go to help you to diagnose an issue that happens after it happens. So, let’s take a look at some of the tools that AWS has built as part of our native AWS platform in order to make it easier to have observability for the applications you deploy.
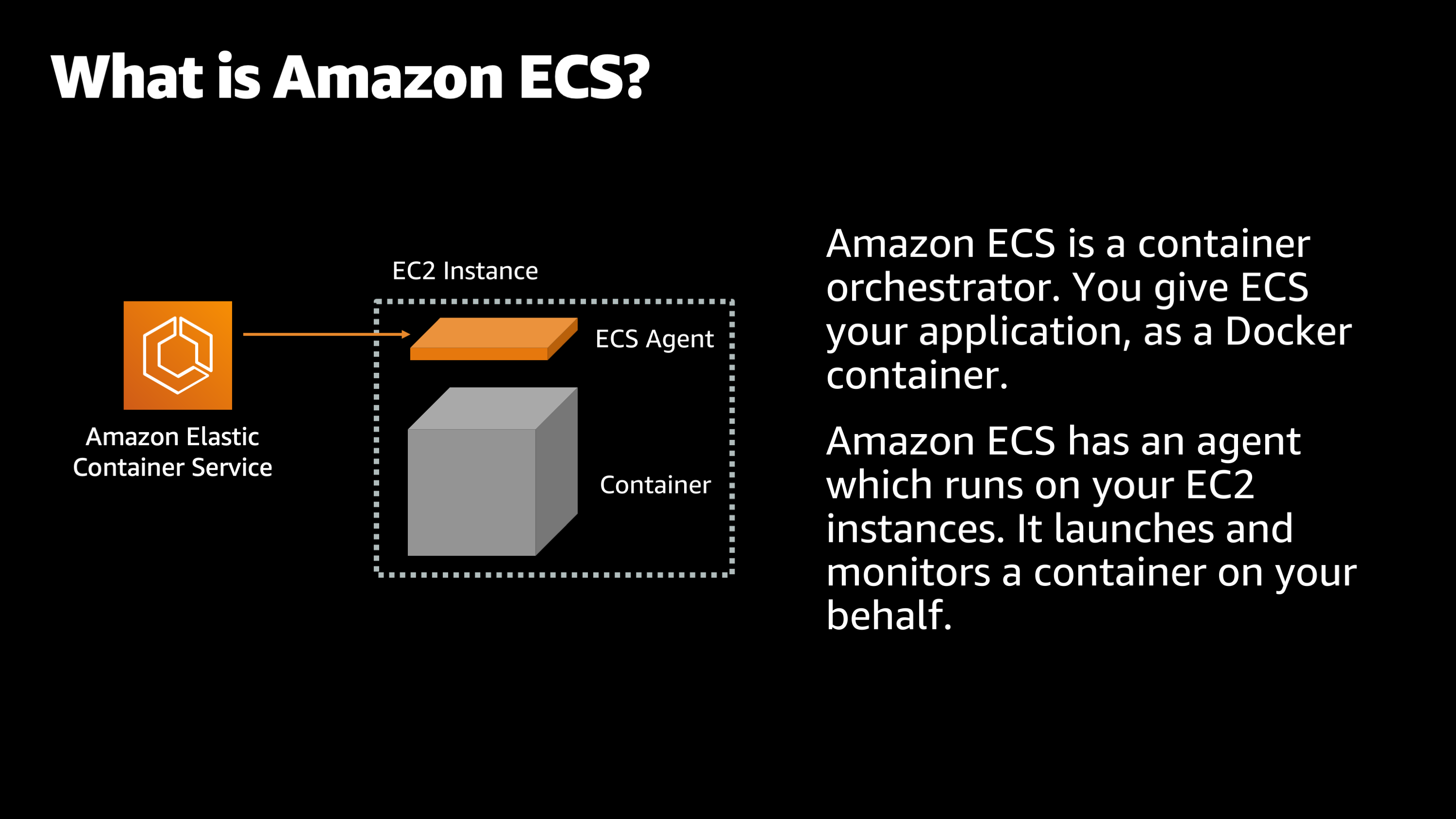
The first tool I want to introduce is Amazon ECS, and what is Amazon ECS? So to start with, Amazon ECS is what’s called a container orchestrator. And just to explain what that is, you know, when there is an orchestra, you have a conductor who sits up there and tells everybody what to do and how to play the instruments. Well, Amazon ECS is similar to that for containerized applications.
You give your Amazon ECS your application in the format of a container image. And then Amazon ECS supplies an agent, which is like that conductor which runs on all of your Amazon EC2 instances and monitors them and acts on your behalf. So then you can tell Amazon ECS, “I would like to launch my application.” And it launches the application container, and it begins to monitor it on your behalf.
So what it’s doing is, it’s watching to see how it’s performing, how the CPU and memory is doing, to make sure that if it crashes, it can restart that application container.
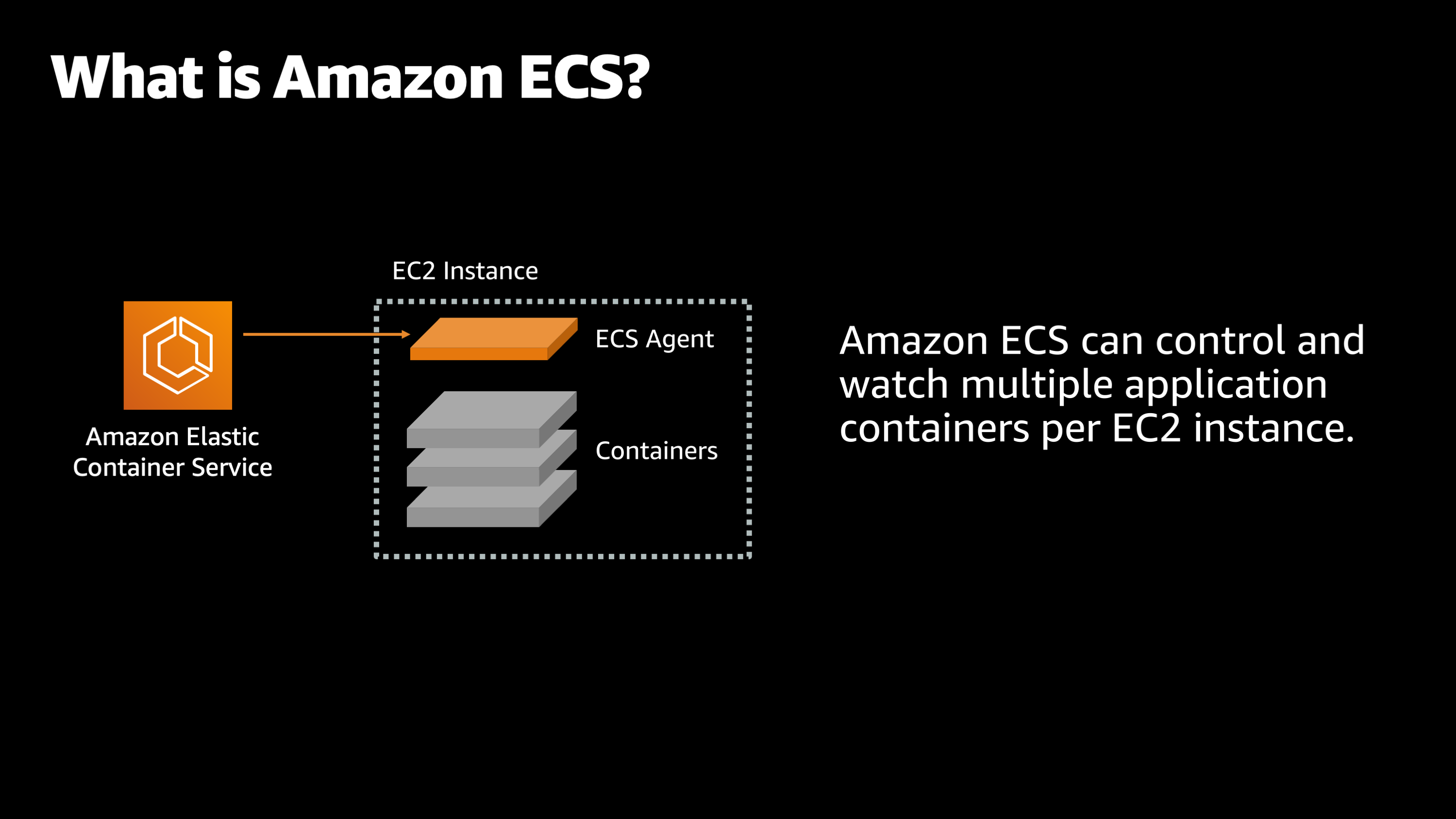
And Amazon ECS has a few more features that make it really easy to work with a lot of applications. The first is that Amazon ECS can control and watch multiple application containers per EC2 instance. So, if I have a variety of different applications, I can have Amazon ECS watching all of them at once.
It’s not like a human, it has no limit to how many things it can keep track of and monitor on your behalf.

And then also importantly, it can watch many applications across many instances, even thousands of them. So imagine if you have a large fleet of maybe hundreds or thousands of computers. It’s very hard to keep track of what’s happening on all these computers. How are the applications performing, what’s going on with their CPU and memory usage and have any of them crashed and need to be restarted. Well, Amazon ECS is monitoring all of that on your behalf. So let’s talk about how that applies to observability.

So, the first thing to understand about Amazon ECS is that its agent has a built-in integration with Amazon CloudWatch. And what that does is, as I hinted earlier, it’s gathering up information about your CPU and memory usage. It’s gathering up other facts such as the application logs that your application might write to standard out and standard error and the health check status.
So maybe you’ve said that this particular endpoint or this particular webpage is a highly critical part of your application that needs to stay healthy. So, you set that as a health check and Amazon ECS is going to start monitoring that going forward.
And then also importantly, when your application does crash, Amazon ECS is keeping track of what’s called the container exit code. What was the reason why it crashed, does it crash with a zero code that indicates there was no issue or did it crash with something like exit code 137? In that case the process ran out of memory.
While Amazon ECS is watching all of that information, it’s keeping track of it. It’s uploading it and storing that in the Amazon CloudWatch for you where you can then explore it later.
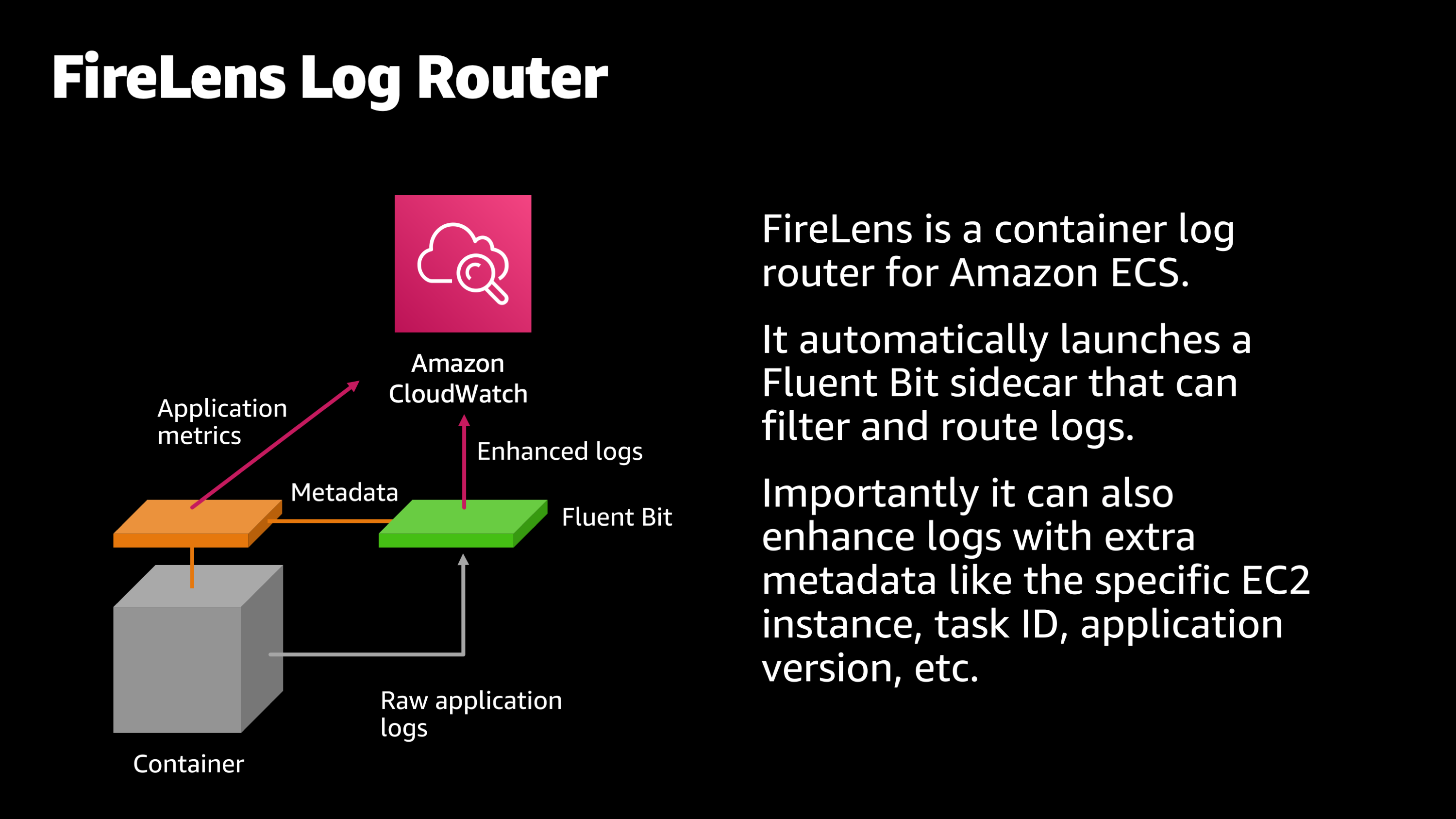
Now, I said it earlier, that Amazon ECS monitors your application logs. Well, I also want to show a different way that it watches the logs. That is using Amazon FireLens. FireLens is a container log router for Amazon ECS that supplements your application logs with extra metadata.
For example:
- What EC2 instance did the log line originate from?
- What application did it originate from?
- What application version did it originate from?
So, logs are a great way to keep track of what your application is doing. But one of the problems that happens when you have a distributed application is you need to communicate from one portion of your application to another application. And observing that service to service communication is really critical.
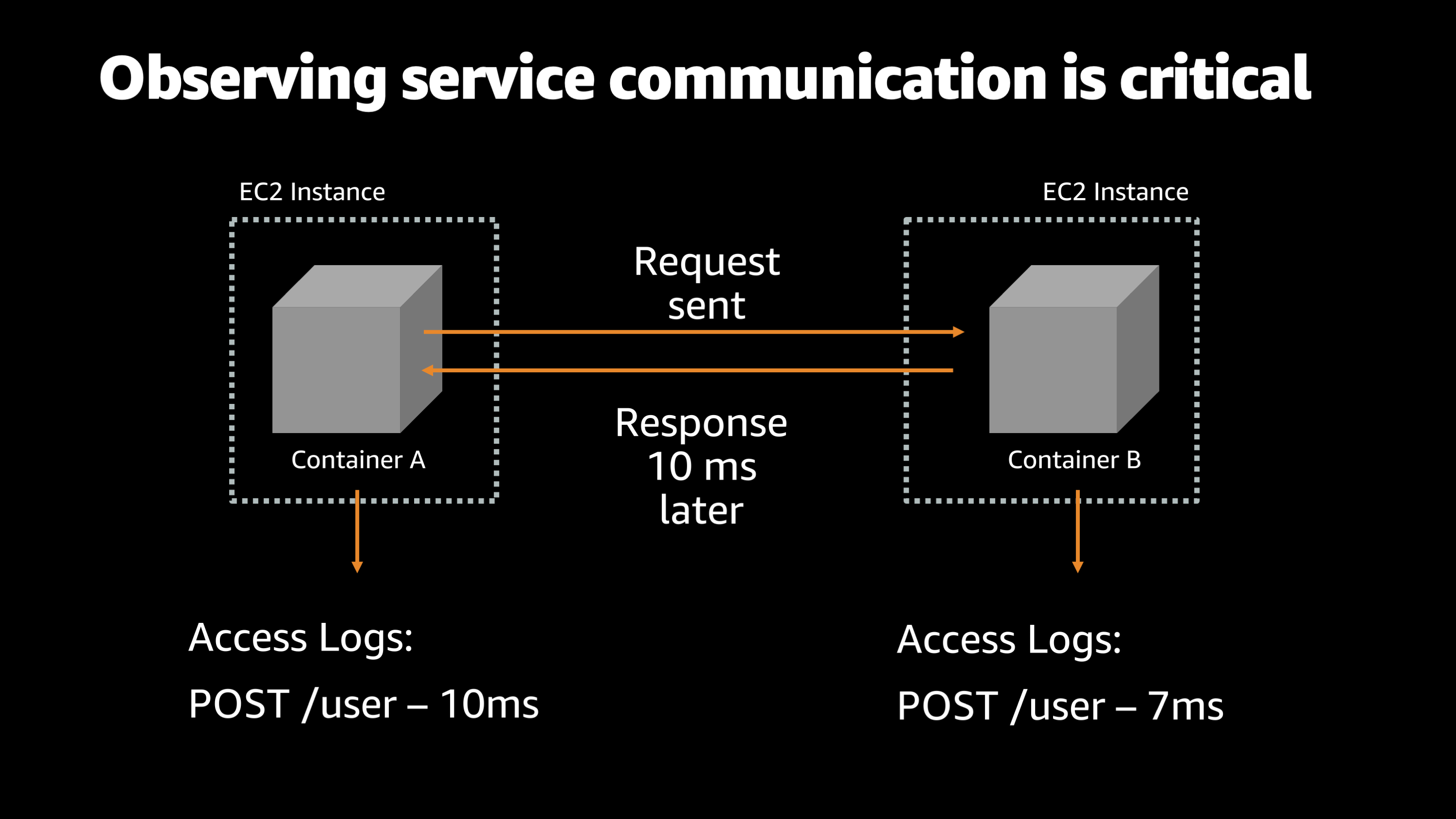
So, for example, here, imagine that you have two containers on different EC2 instances, and they need to communicate with each other. And normally, container A sends a request to the /user endpoint on container B and then, container B, about 10 milliseconds later it sends a response back to container A.
This is a pretty typical type of service to service communication that you would have in a fairly complex architecture. However, if you’re just using access logs and standard output to monitor what’s going on with this applications, you could end up with situations where we don’t have enough logs to actually diagnose issues.

So imagine a scenario where container A sends a request and tries to talk to container B, but all it gets is a timeout error.
So then you look into the access logs for container B and you see nothing showed up. So all you know is that container A tried to send something to container B, but container B logs say, “Well, I never got it. I don’t see anything that happened there.”

So, what’s going on? What could have caused this?
There could be a networking problem. It could be a security group that needs to be configured properly to allow port access between container A and container B. It could be that the EC2 host that was running container B had CPU or memory just overloaded, and wasn’t able to get the job done. It could be that the container process was stuck in an infinite loop and just unable to answer the request, or it could be that the container process had crashed and it was no longer even existing to answer the request.
So, the problem is we don’t have observability. We don’t know what happened here. We don’t know where the request got dropped or why it wasn’t answered.

So this gets into AWS App Mesh and how it can help you with observability. AWS App Mesh is a service mesh. And the core thing that defines App Mesh is a sidecar process that gets launched alongside each copy of your application container.
All of the inbound and outbound network communications for your application actually go through this sidecar process. And that allows the sidecar process to route and observe all of those communications and connections to and from your application.
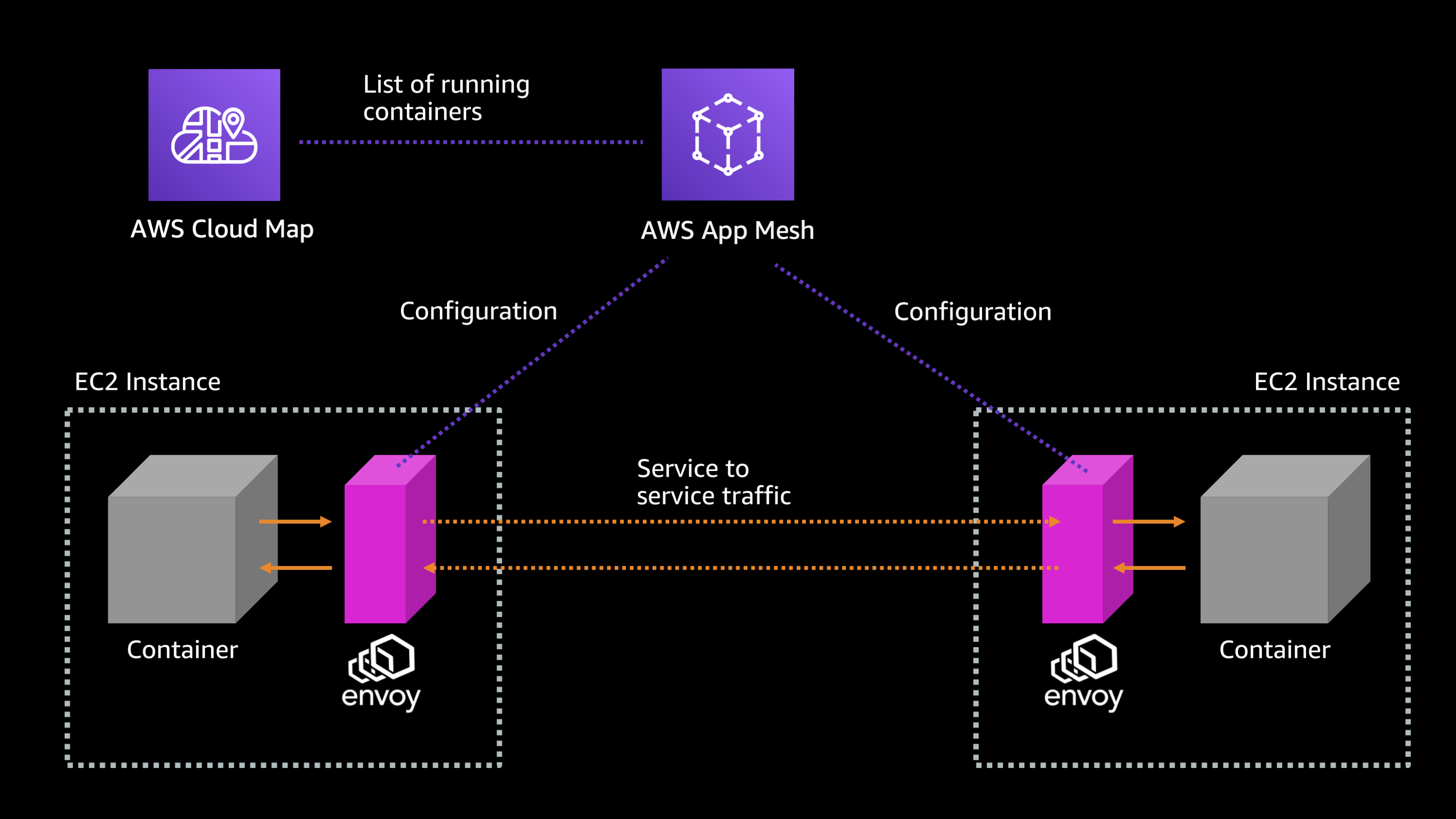
Let me explain by showing a higher level diagram of how that works. So, App Mesh is sitting there in the cloud and it has a list of all of your running containers. It knows where your containers are and whether they’re running. It usually gets that from something like AWS Cloud Map integration with Amazon ECS.
And then you have one or more, typically more than one, containers running across the EC2 instances, and each of them has an Envoy sidecar. So, AWS App Mesh sends down configuration and monitoring health information to these Envoy sidecars that are sitting beside the application.
And then when your application container wants to talk to another application container, it does so through the Envoy proxy. So you can see the network communication goes from container to Envoy, from the Envoy to the other Envoy, then from the Envoy to the other container. And then back through the process through these Envoys.
So, you might be thinking: “Okay. Why would I want to have this extra component in there. Wouldn’t that make things more complicated?”
Well, an interesting thing happens when you have this Envoy sidecar there to route all of your traffic through. It gives you this reliable tunnel between unreliable components.
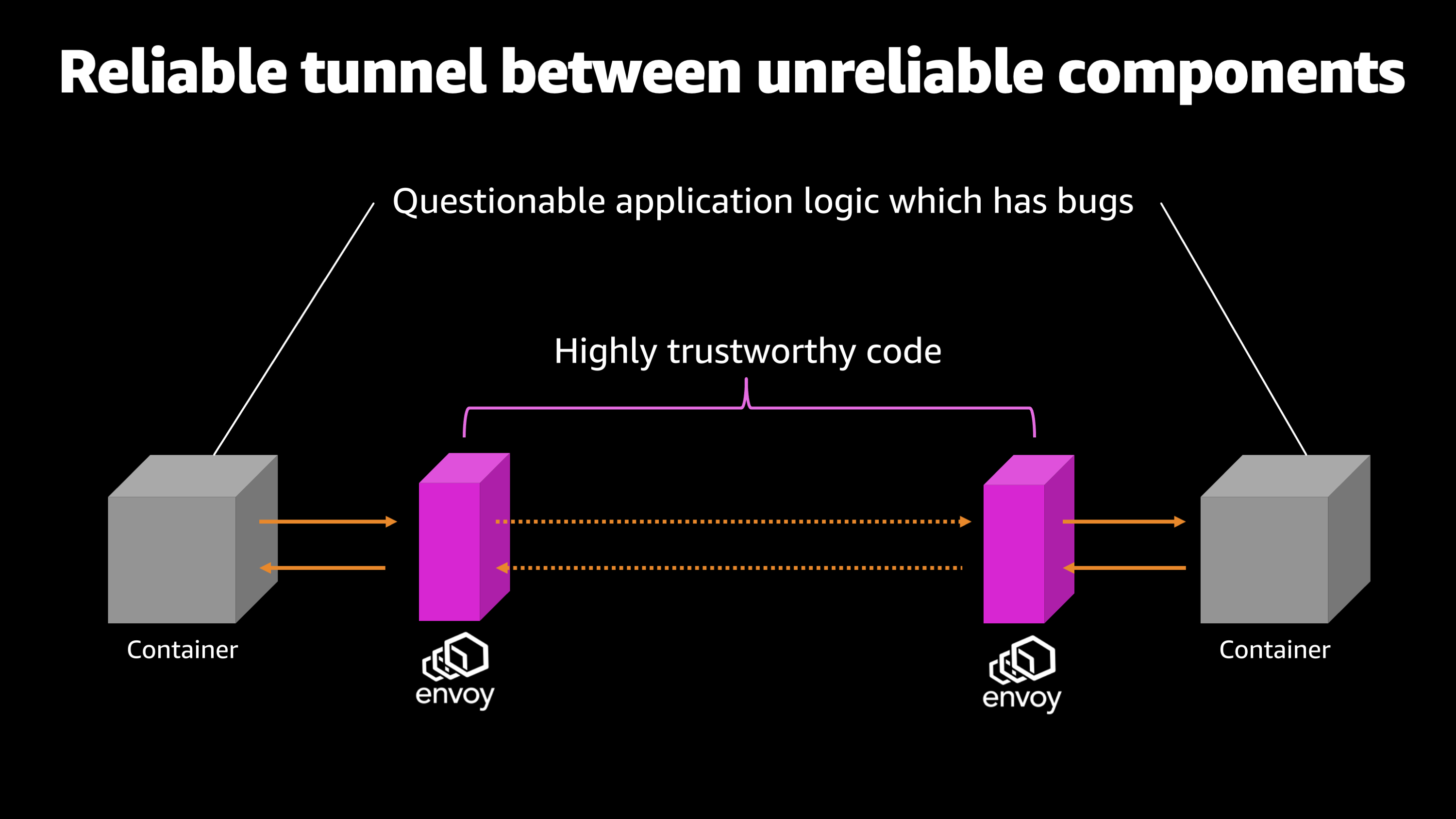
And let me explain what I mean by that. So, generally when you’re writing an application, there’s bugs, there’s issues, there’s things you’ve overlooked, which could cause your application to crash or to fail in unexpected ways.
However, Envoy is this industry standard tool for routing traffic. And we know that it’s highly trustworthy. So, what ends up happening is on either side, we have this questionable application logic, it might have bugs, it might crash, it might be unable to respond for some reason. But then in between we have the Envoy sidecars that are routing and directing that traffic. So we’re able to trust the pipe in between the applications and we’re able to observe each hop independently.
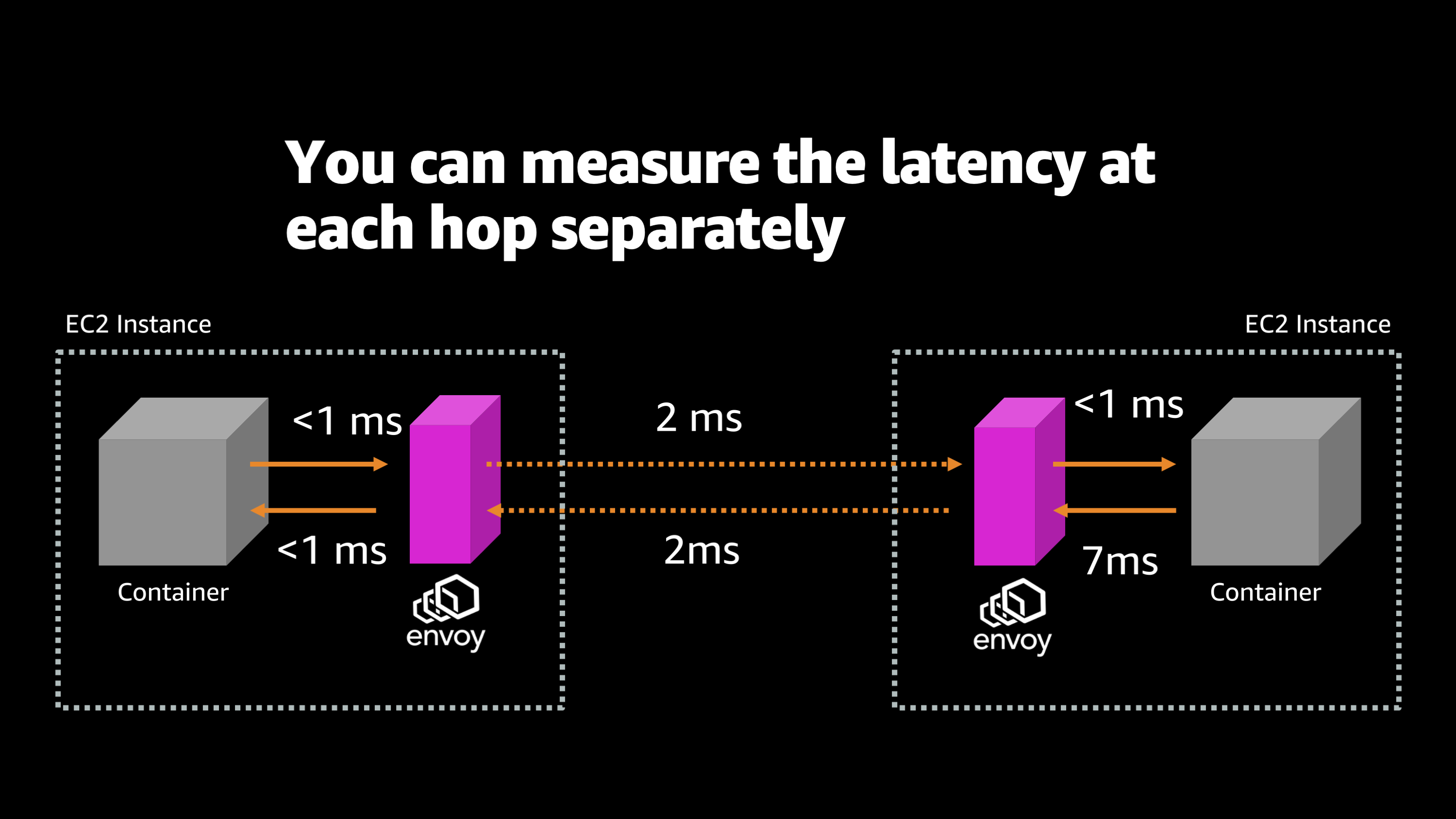
So let me show you what that ends up looking like. Here’s an example of measuring the latency of network communication between two different containers. So here I see that there’s two EC2 instances. Each computer is running a different container and there’s an Envoy proxy there. And I’m able to measure independently how long it takes for communications to go from one piece to the next. So I can see from the container to the local Envoy on the first EC2 instance, it takes less than one millisecond, which is to be expected. It’s right there on the same computer. Then we have a two millisecond hop across the network to the other EC2 instance. Once again, there’s a less than one millisecond jump from that local Envoy to the local container on the other EC2 instance. And then we see that there’s a seven millisecond delay while that container is processing the request and creating an answer before it sends that answer back to its local Envoy. Then once again, we have two milliseconds over the network, back to the originating EC2 instance, and then less than one millisecond from that Envoy to the originating container.
But what I want you to notice is that we have a lot more information now about each of these individual hops and we can measure them independently and start to differentiate between a delay that happened because of the network and delay that happened because the application was slow or any other condition that might’ve happened along this network path.
So, one of the interesting things that can happen is you can tell exactly where communication is breaking.

I have an Envoy proxy set up here and I see that the network connection got dropped. I can see that my originating container was able to send a request to its local Envoy, but that local Envoy was unable to talk to the remote Envoy on the other machine. So that tells me, okay, I know what’s going on here. The networking between these two EC2 hosts is blocked. Maybe there’s a port mismatch, maybe there’s a security group that’s not configured right. Maybe my VPC networking rules were just totally messed up and there was no physical path to actually send a communication over the network to my other servers.
And I can differentiate between that scenario and this other scenario where the request actually made it from the originating EC2 instance to the other instance in the cloud. And it made it to that other Envoy on the other machine, but that Envoy was unable to get a response back from the container.

So here, I know that the communication reached all the way to the other instance that had that service on it, but the service that was on that instance was flawed in some way. It crashed, or it just was unable to answer my request. So I think you’re probably starting to get the idea that that Envoy is really helping me to have a lot more information on what’s going on when I have network communications within my application.
The other cool thing that Envoy does is it allows you to test different versions of your application. So here, for example, shifting traffic and shaping it.
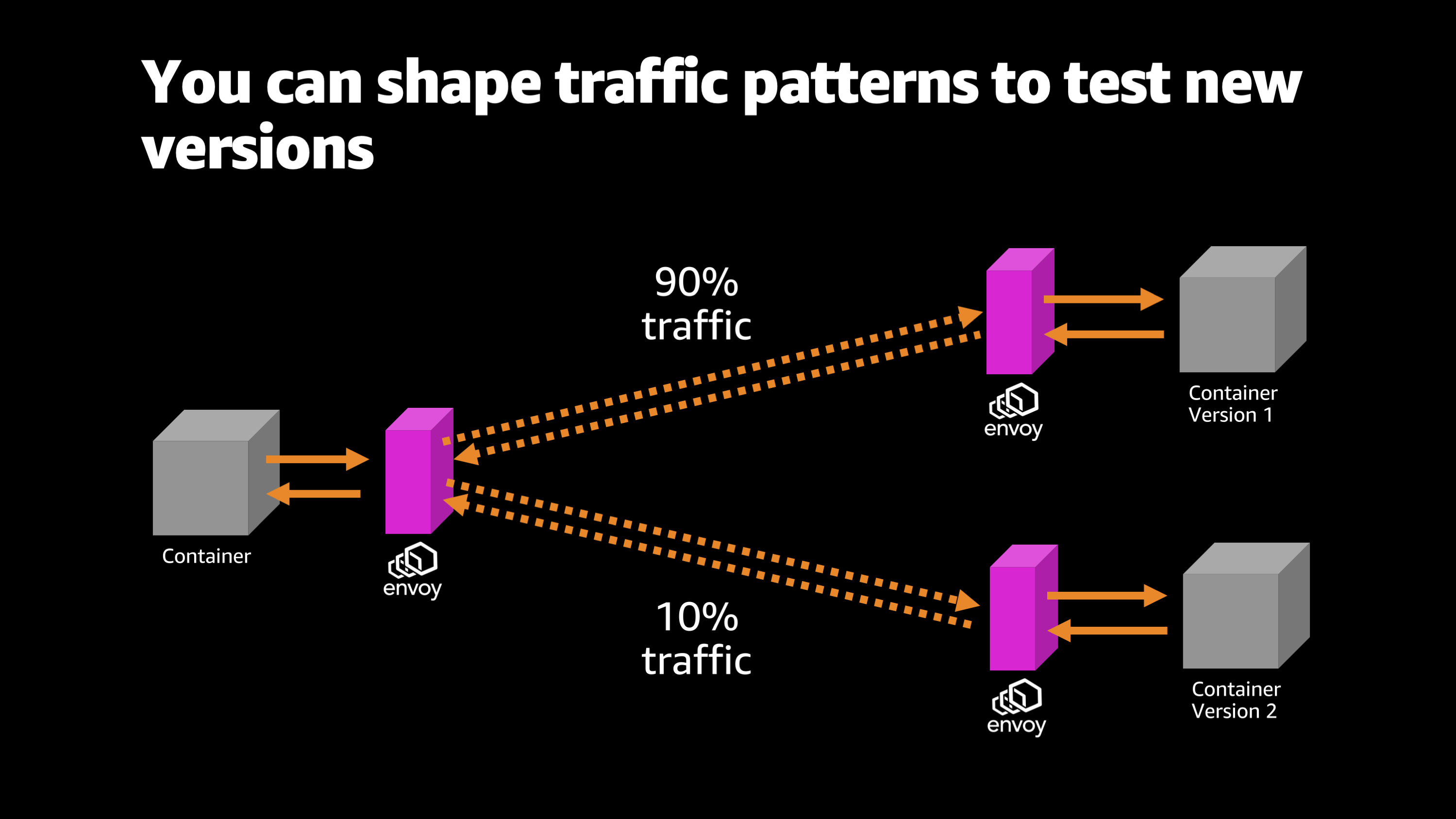
I’m sending 90% of the traffic to one version of the application and 10% to the other applicant version of the application. And I’m able to measure different parameters and latencies and response times and error rates and all sorts of different information about how these different versions of the application perform.
The next piece I want to introduce to this observability puzzle is the CloudWatch agent.
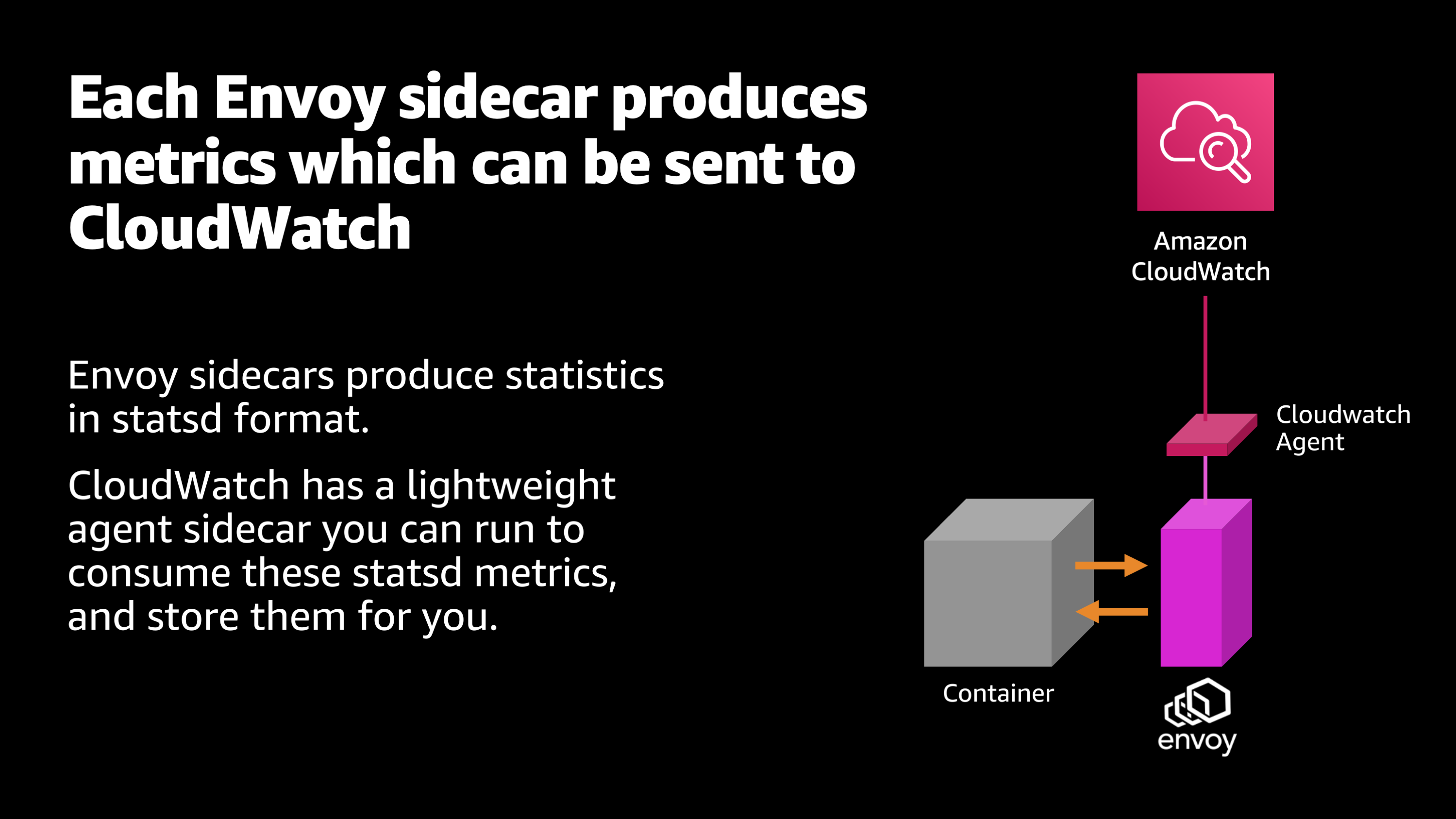
That Envoy sidecar that is gathering all this information, well, we need to gather that information up somewhere where we can actually explore it and make use of it. And that place is Amazon CloudWatch. The Envoy sidecar produces the statistics and makes them available in what’s called statsd format.
And then CloudWatch provides a lightweight agent that you can slot on next to your Envoy sidecar. And it will gather up those statistics and send them off to Amazon CloudWatch, where you can explore them, graph them, create alarms, metrics and stuff like that.
Another piece that can be super useful here is AWS X-Ray.
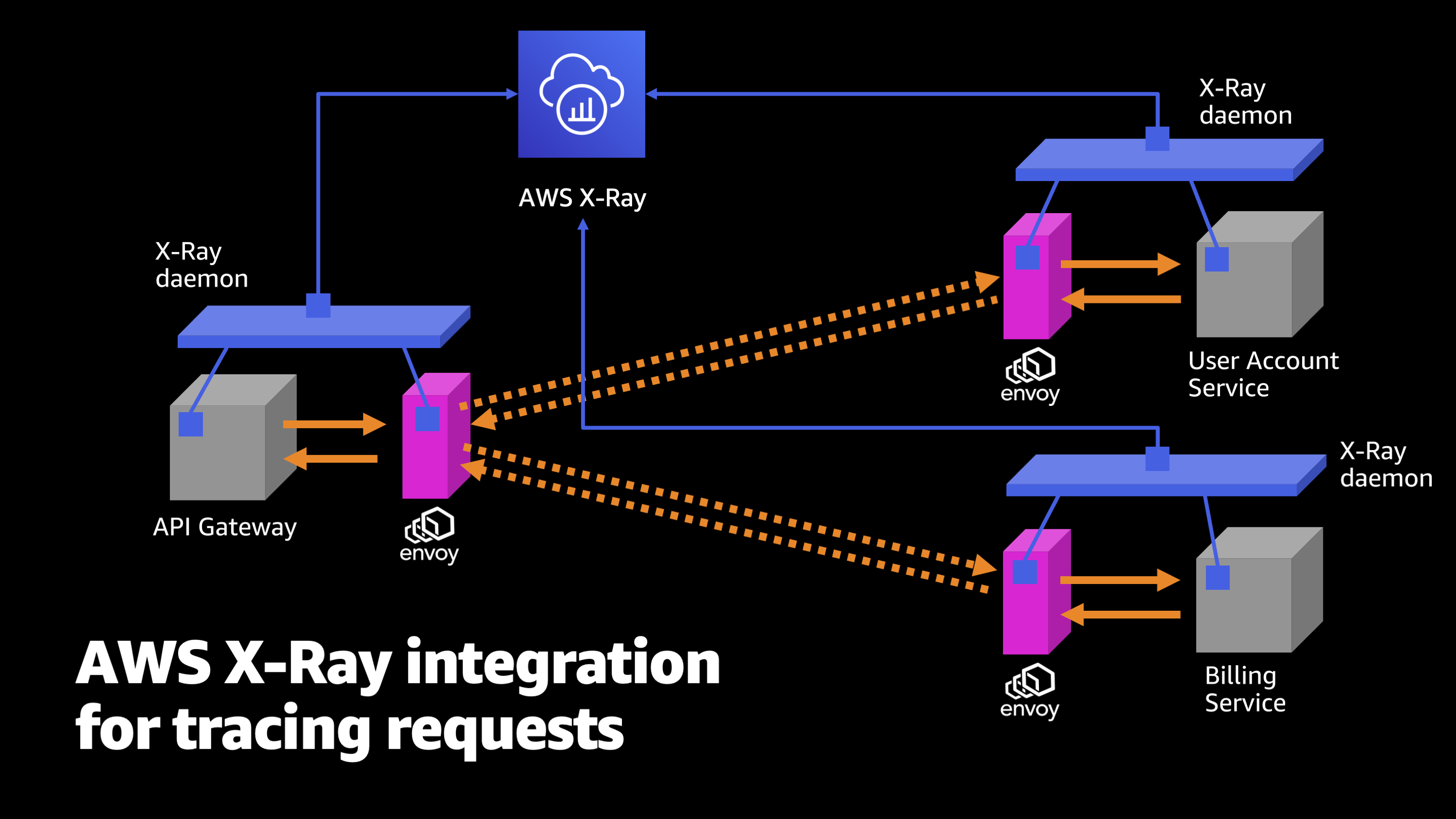
So I’ll show a bit more about what AWS X-Ray is a little bit later. But to start with, let me just introduce it as a tool for tracing requests. It actually hooks into each of the individual pieces of your application, both your container and your application code. It hooks into the Envoy and it hooks into the upstream or downstream Envoy and service that answers the request.
So, it’s gathering up information from all these different individual places. It’s hooking into everything, and it’s watching every single jump and every single part of this process of sending requests and serving it back to an end client.
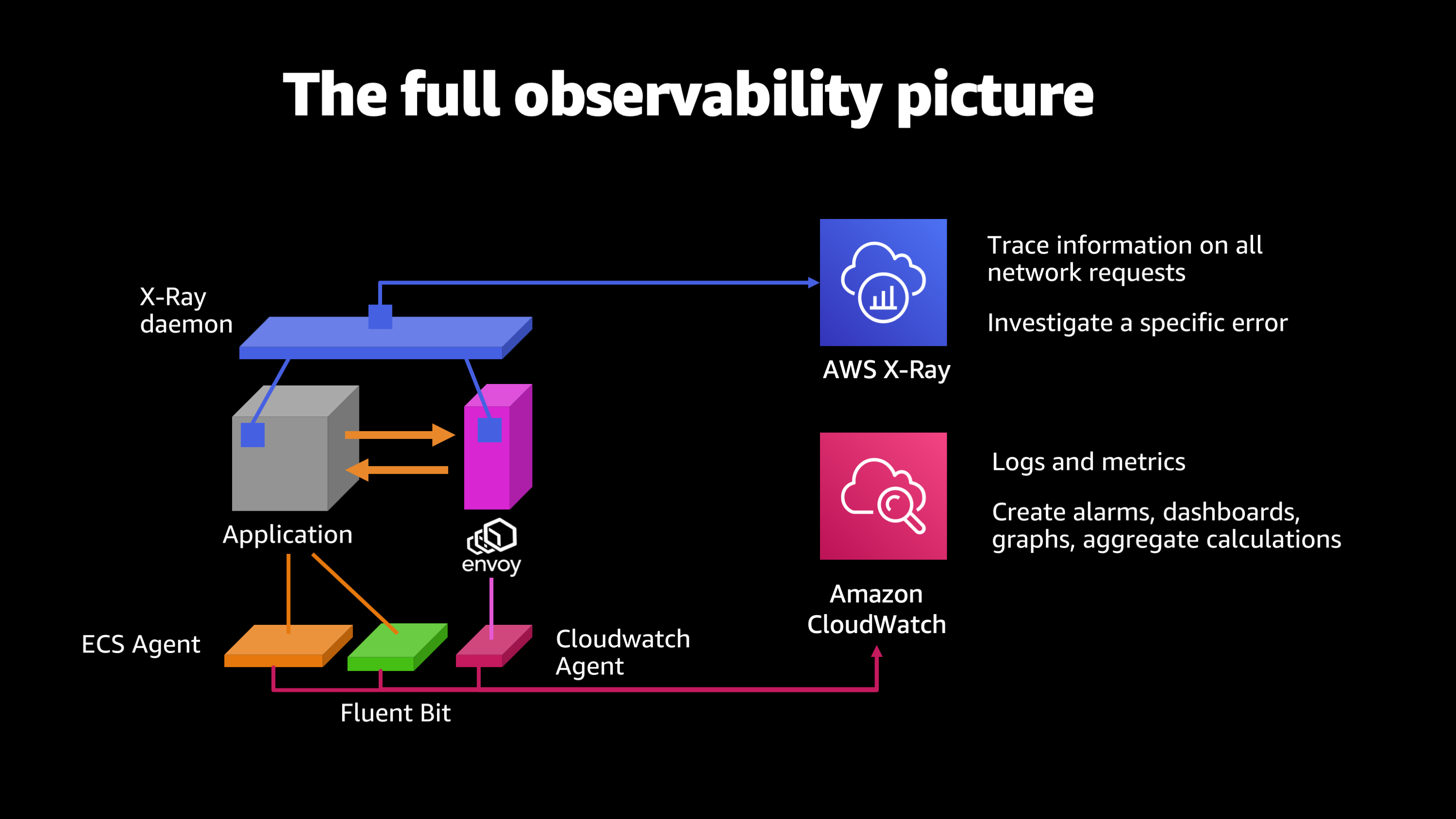
Let me show you what all these pieces look like together on a graphic. We started out with the application, the containerized application, and we have the ECS agent, which launched the container. Its watching that application for its CPU usage, its logs, and that allows you to do things like create alarms, dashboards, graphs, and aggregate calculations about how your application is performing. To that we’re going to add Fluent Bit. So Fluent Bit, what it’s going to do is it’s going to enhance my logs with extra information that makes them more searchable. So now I can start to drill down: Let me look at this particular version of my application, and look at all of the log output that originated from that particular instance and that particular version of the application.
Then we want to start monitoring the network communications for the application. So, we put on Envoy and CloudWatch agent. What this is going to do is, it’s going to start watching all the inbound and outbound connections, their failure rates, their response times, summing up all that information and storing it in CloudWatch once again via the CloudWatch agent.
And then last but not least, we’re going to put on the AWS X-Ray daemon. And what this is going to do is, it’s going to hook into my application site code as well as the Envoy code, and it’ll even hook into the upstream or downstream application code and Envoy quick code. And give me this end-to-end picture of all the different hops and pieces that happened along the way to serving a request back to a client.
So, let’s take a little moment now to look at some of these pieces inside of the AWS console and see what they look like in action. So, first of all, I want to show how you can configure and launch all of these things.
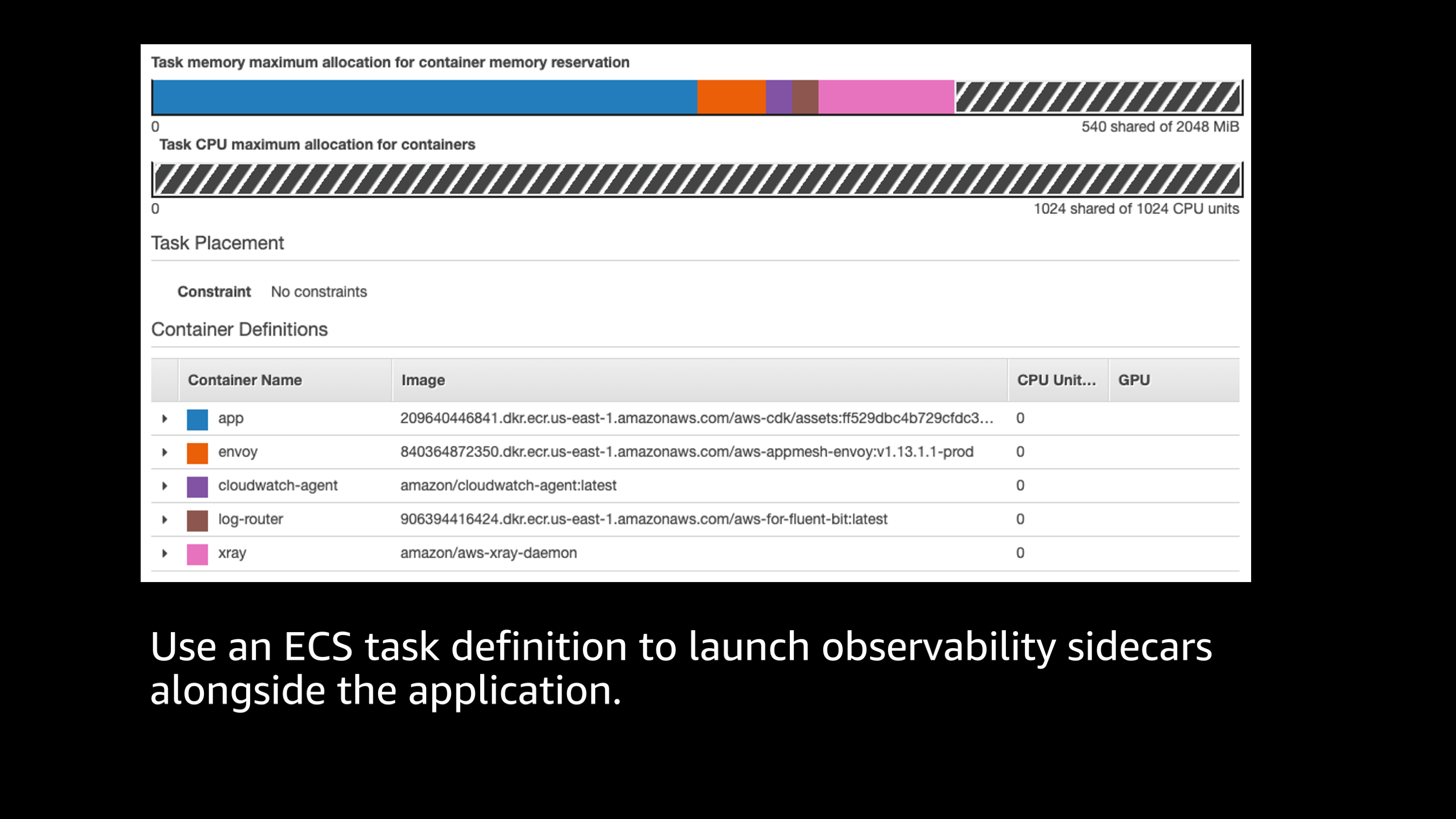
If you’re familiar with Amazon ECS, this is a typical Amazon ECS task definition, and you’ll see that I have launched all of these different pieces as part of a single task definition that I want run inside of ECS. I see the application there, I see Envoy proxy, I see a CloudWatch agent, the log router, which is Fluent Bit, and I see the X-Ray daemon.
All of these things are running together as one package that’s part of my application. And they’re sharing the overall resources that will be launched, or that will be allocated to my task. So you see that I have allocated for this task one CPU and two gigabytes of memory. These particular tools, they’re pretty lightweight. You can see by the graph up the top, that the bulk of the usage is actually going to my application, and all these different little sidecar containers for observability, they take a very small fraction of the overall resources. Most of the resources are actually shared by the application. But these things are very lightweight, very easy to launch together as a package on Amazon ECS.
The next thing that I want to show is Envoy proxy logs.
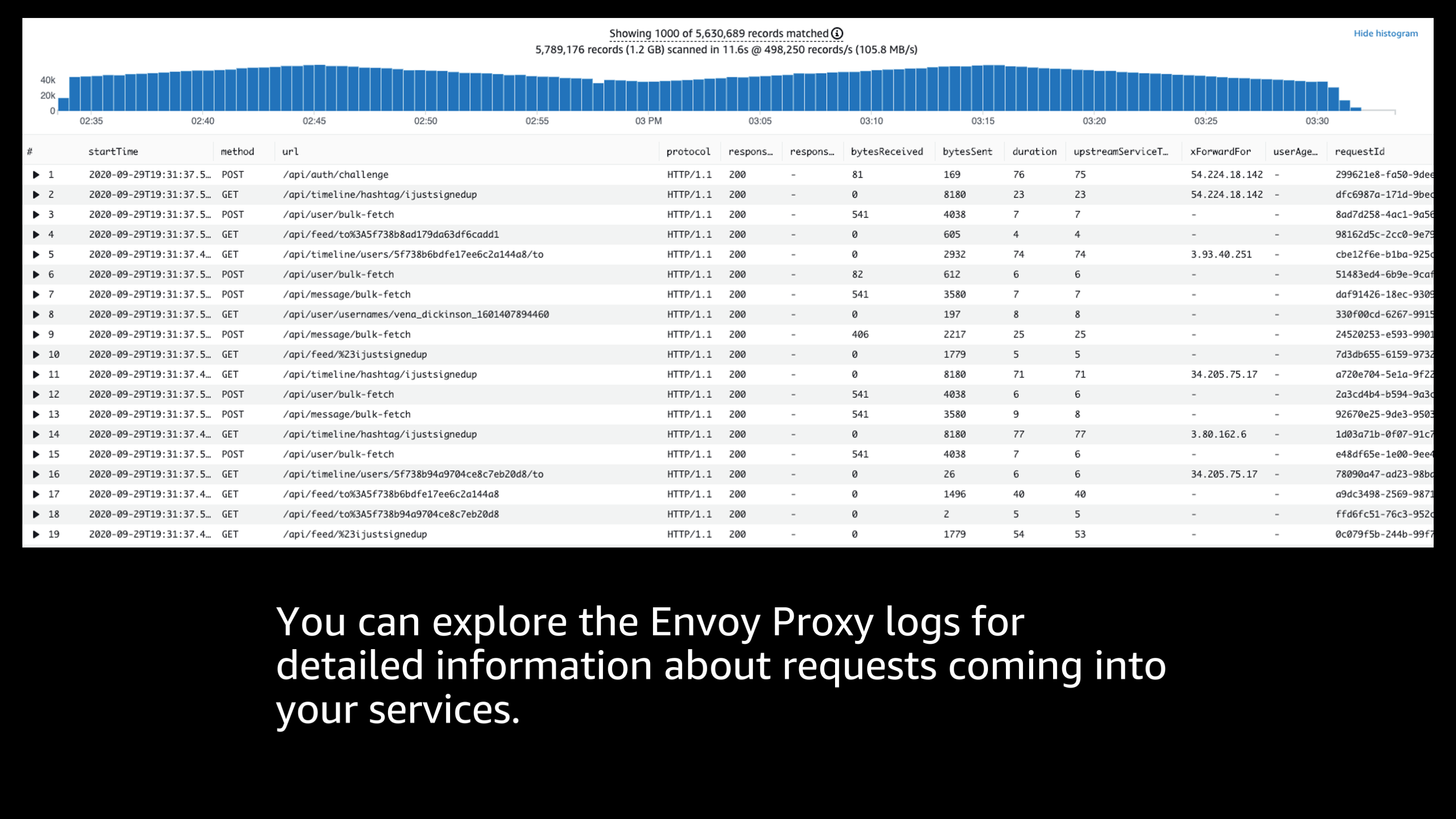
Envoy proxy logs gives you an incredible amount of detailed information about the requests that are coming into your services, where they’re coming from, what the response sizes were, response times, response codes, protocols, URLs, all sorts of different information you can explore.
And I can use in this case CloudWatch logs insights to slice and dice that information along different dimensions and search for specific information or sum up aggregates, create averages to let me know how these communications are performing. So, let me show you a little bit about what that looks like.
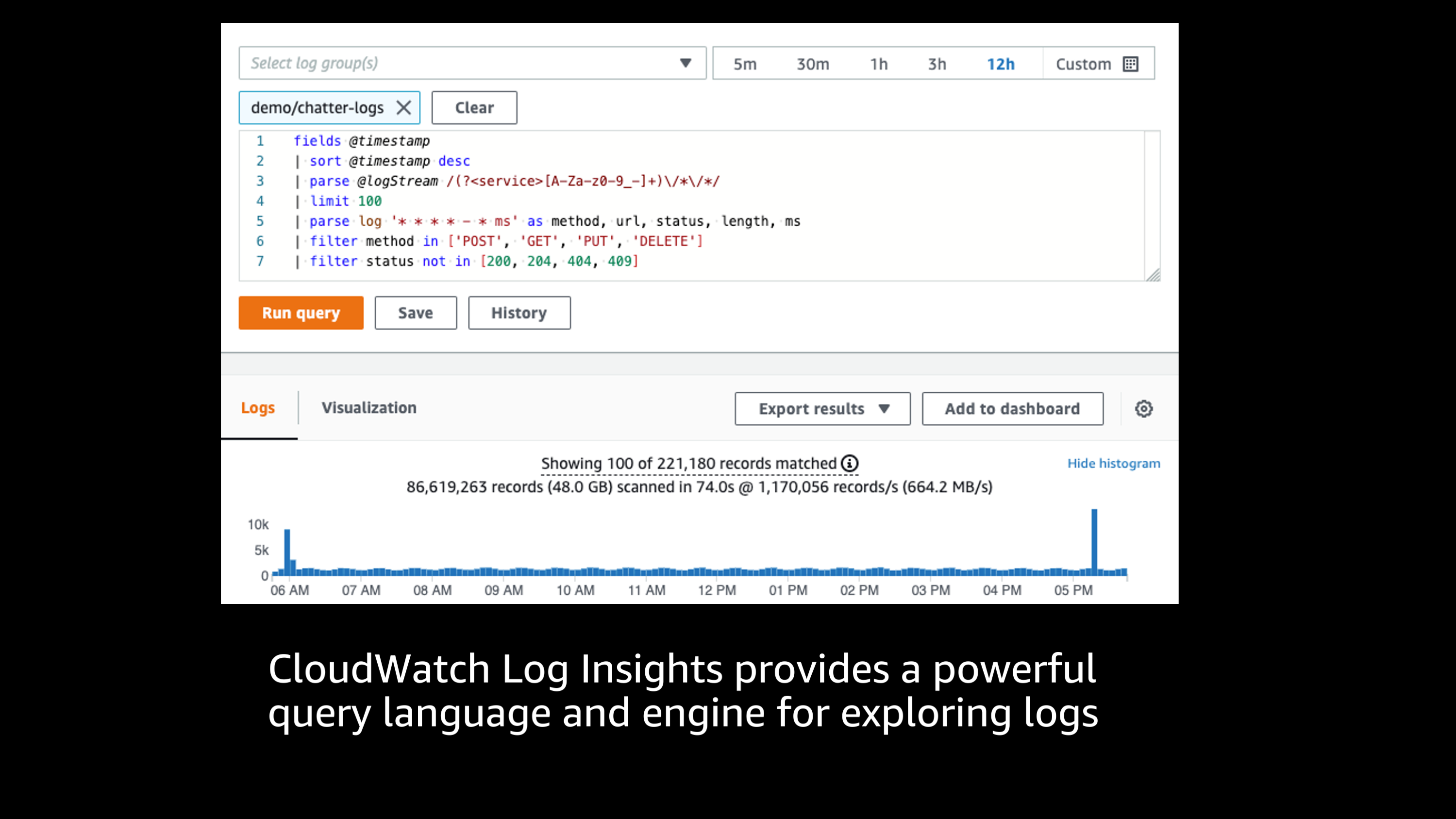
Here you see a more advanced Amazon CloudWatch log insights query. This query language is super powerful and the engine is amazing. The performance is incredible, I’ve worked with terabytes of log information, and it really just crunches all the numbers, can handle a variety of different logging formats, and allows me to gather up stats and filter those logs, parse them in a variety of different ways.
So it’s a super powerful tool for exploring how those requests are actually performing inside of your application.
I talked earlier about CloudWatch metrics, and I want to show you the App Mesh Envoy proxy metrics for a very small cluster of microservices.
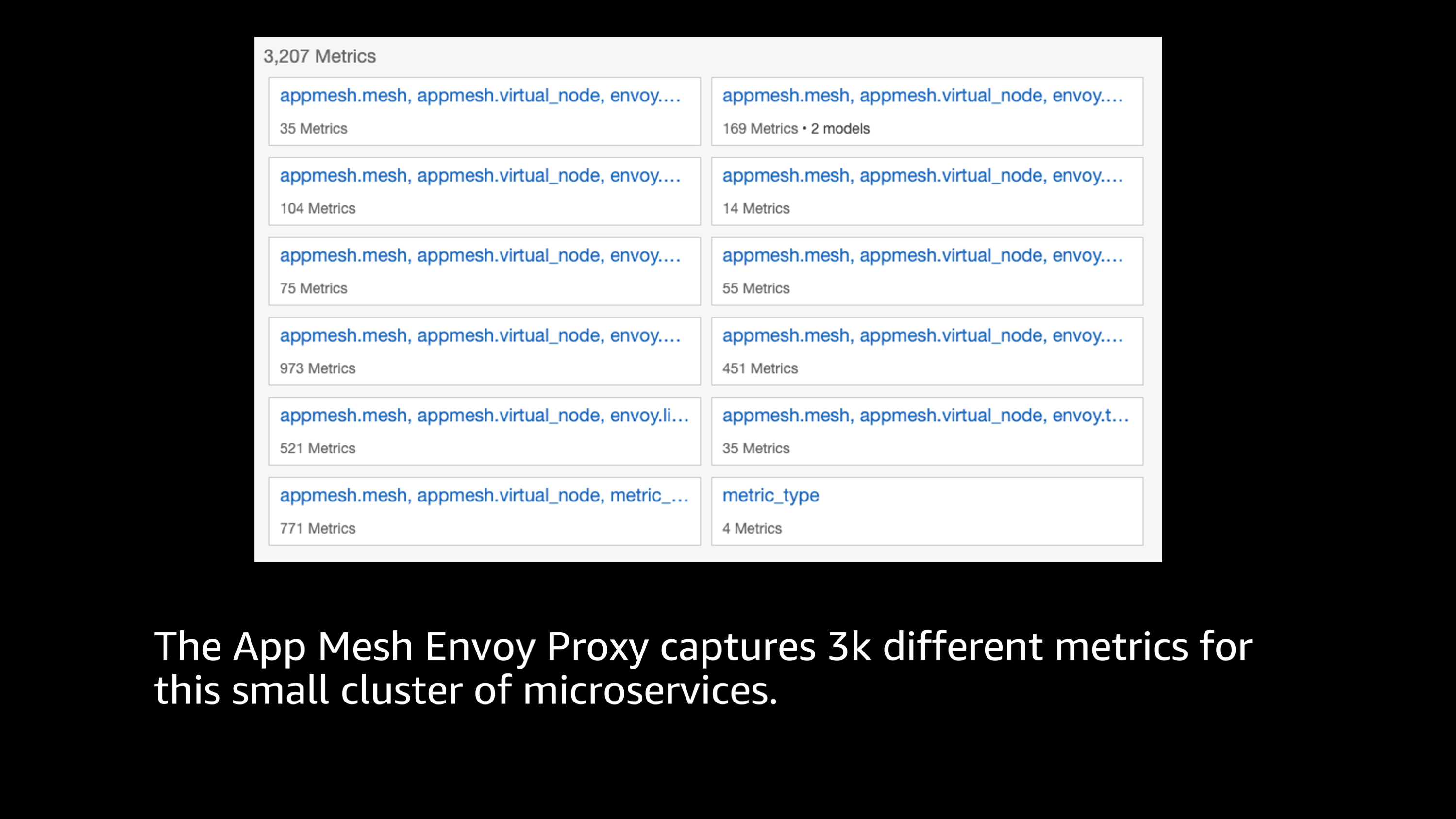
You can see that there’s actually in this diagram 3,207 metrics. So, that’s an incredible number of metrics, but they’re capturing all sorts of different information, not only about response codes, total requests, response times, but even independently from each of the different services to another specific upstream service, what was the latency and performance between those two particular services?
So, there’s a ton of different ways that I can explore this data and dive deeper, to look at different problems and delays in issues that might be occurring inside of a service mesh.
One of the ways that I can make sense of this incredible amount of data is by using CloudWatch features such as anomaly detection.
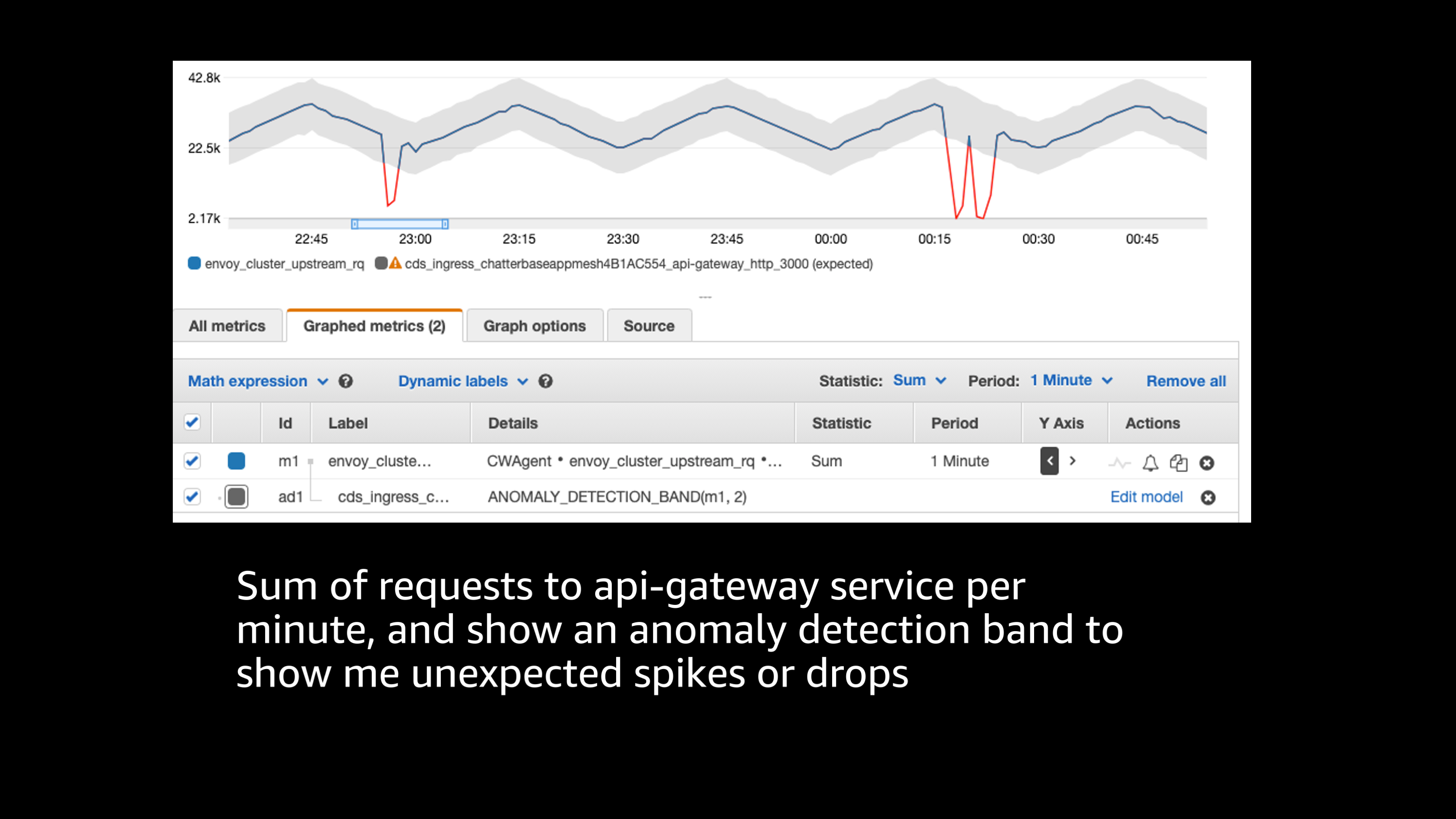
Here in this case, we have a graph and metric per minute, and we’re drawing in an anomaly detection band to highlight anywhere that there’s an unexpected spike or drop. So sometimes there’s a daily pattern or hourly pattern or some sort of pattern to the data where you would expect it to look like a certain particular path, but then there’s an unexpected shape to that. Maybe there’s a big spike in traffic or a big drop in traffic that indicates some major issue. This CloudWatch anomaly detection feature allows me to find those issues and those metrics that are outside of the bounds of where they should normally be.
X-Ray is super cool.
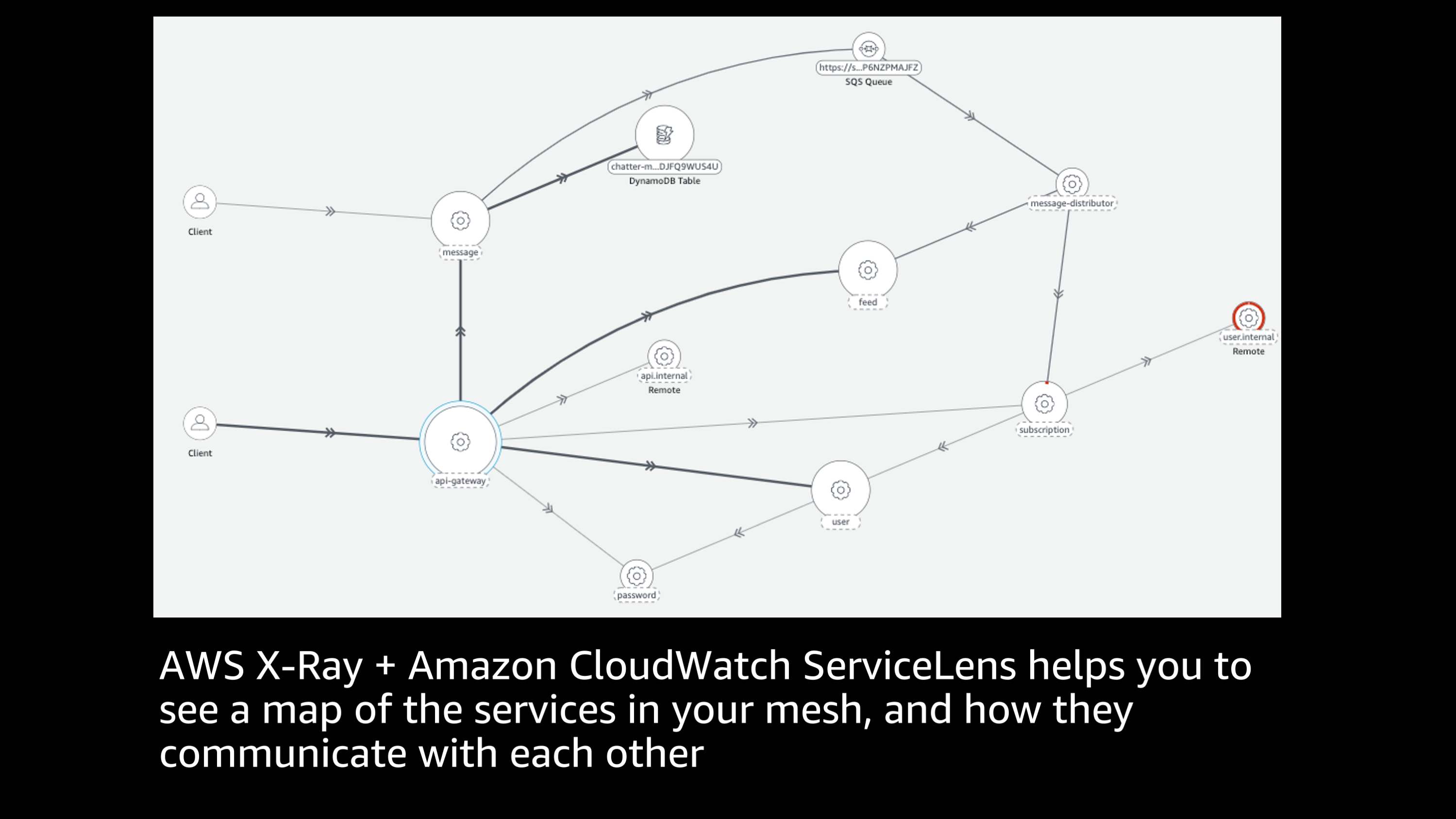
One of my favorite things about X-Ray is the ability to hook into all of my different services inside of my service mesh. It allows me to draw a map of all of the services in my mesh and show how they communicate with each other. So here I get to see this end to end sort of graph of all the different services, how they communicate to each other. There’s a lot of information in this graph. Let me show you. If I zoom in on one specific service, I can exclusively view the connections to, and from that service.
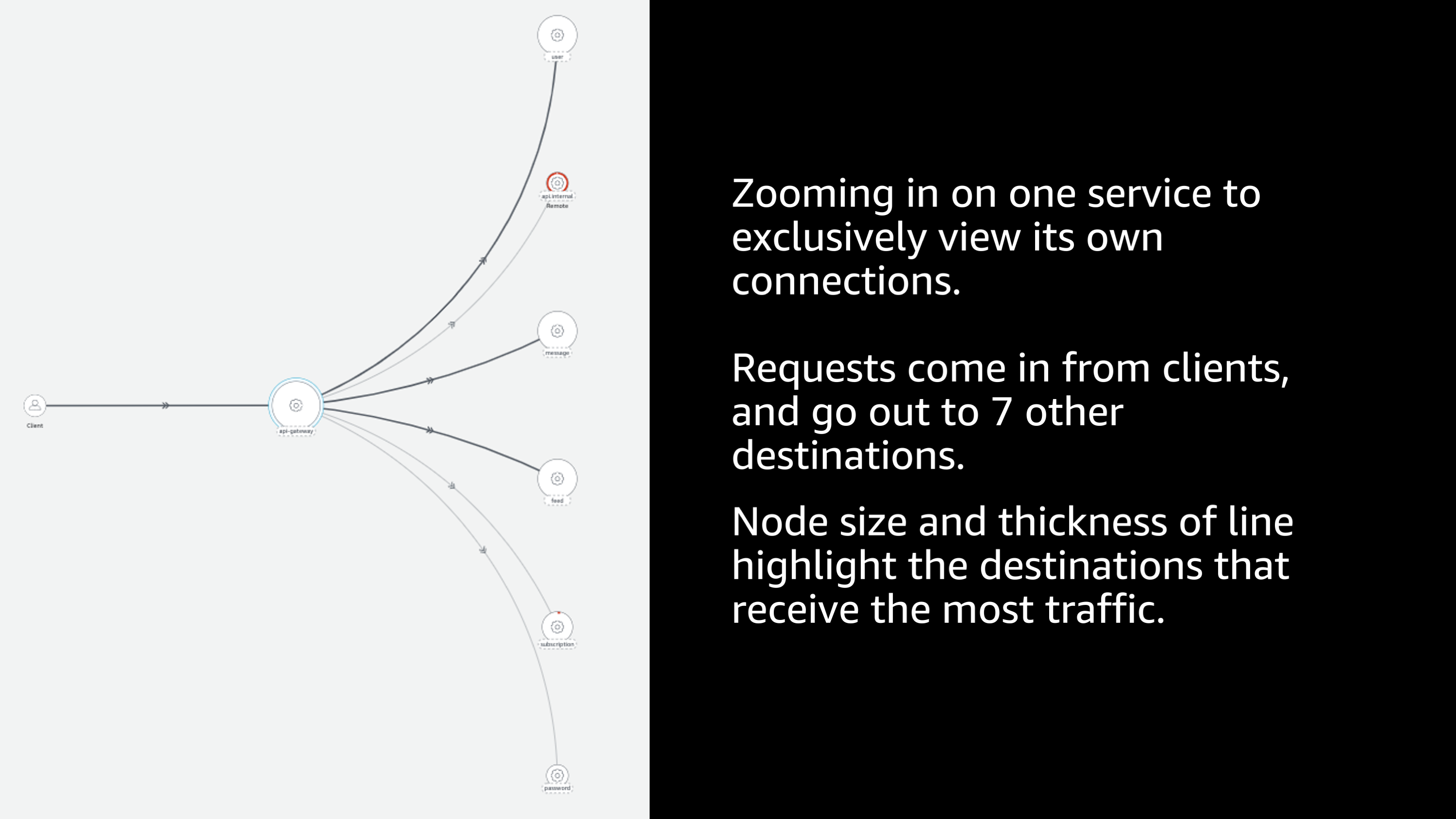
And I can see the relative weight and importance of these different services. I can see that some of the lines are thicker and that indicates that there’s a lot more traffic going to that particular service. Some of the nodes are larger indicating that they receive a lot more traffic in general.
And I see that one of them, it’s hard to see in this slide, but its highlighted red. And if I click on that and zoom in, I can see that there’s an issue there.
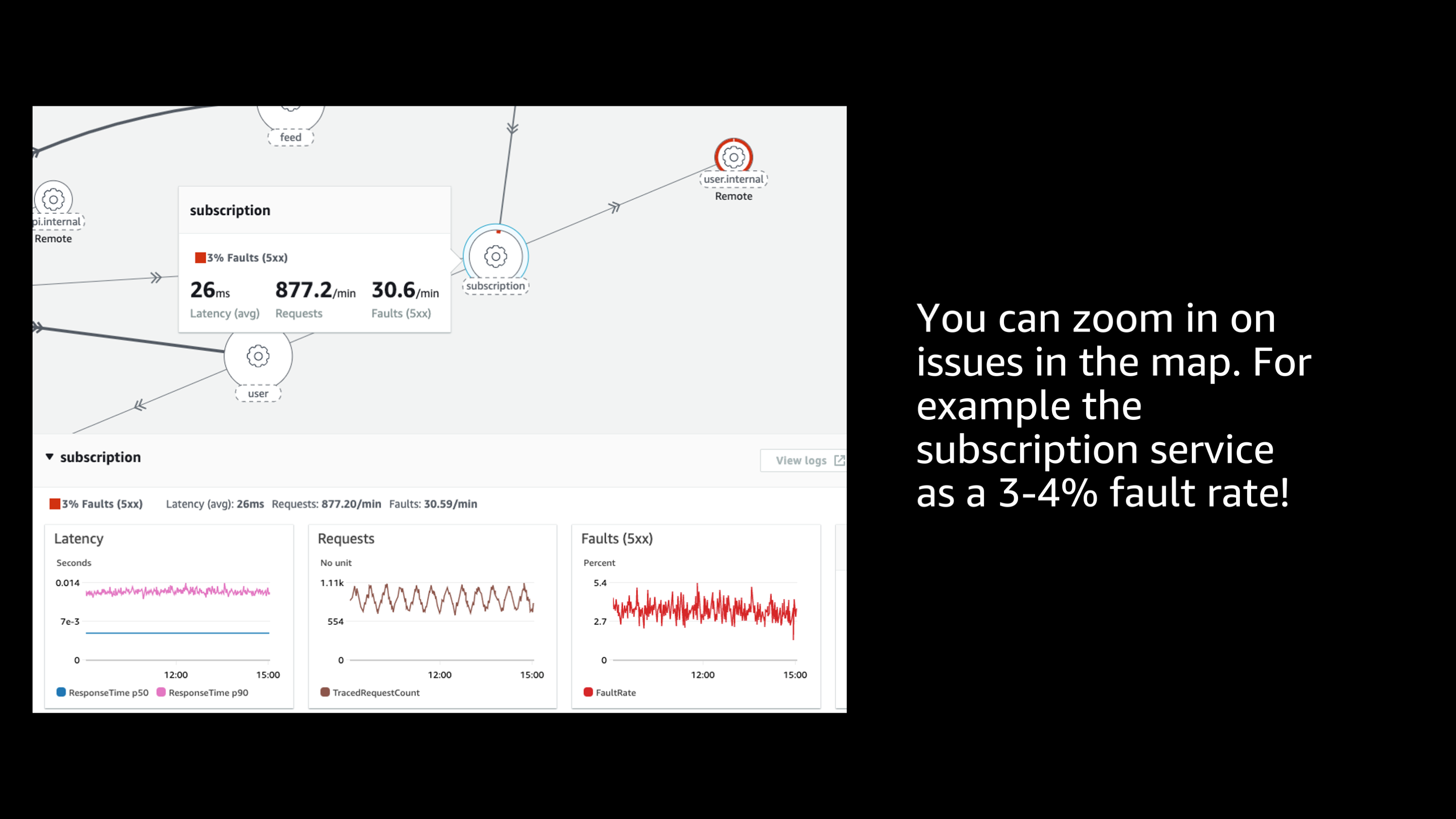
And I can start to see some more information such as latency of requests, and most importantly, the fault rate. So here I can see that that particular service had a 3 to 4% fault rate which is definitely not good. In any case there’s some kind of issue that I need to explore further. So, I can take that information off the service map that is provided by X-Ray.
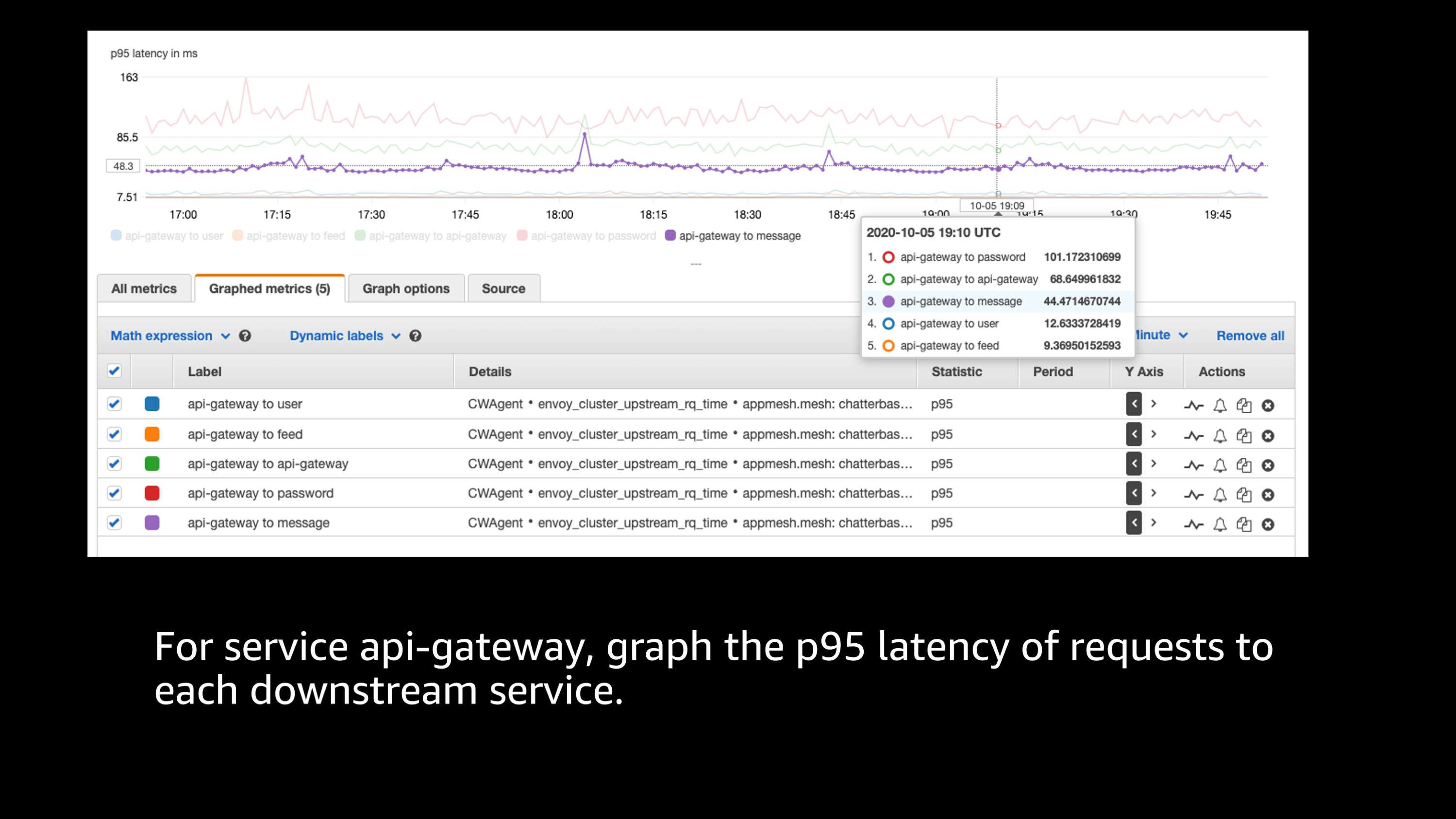
And I can go back to my Envoy stats once again. I can start to look at some information like, “What is the p95 latency of requests to the downstream services?”
I can map those together, I can start to look at it and then I can say, “Okay, I think I’m starting to get the idea that there’s an issue in this downstream services that has a spike in latency.”
Let me zoom in on a particular request in X-Ray and look at the downstream requests that make up that.
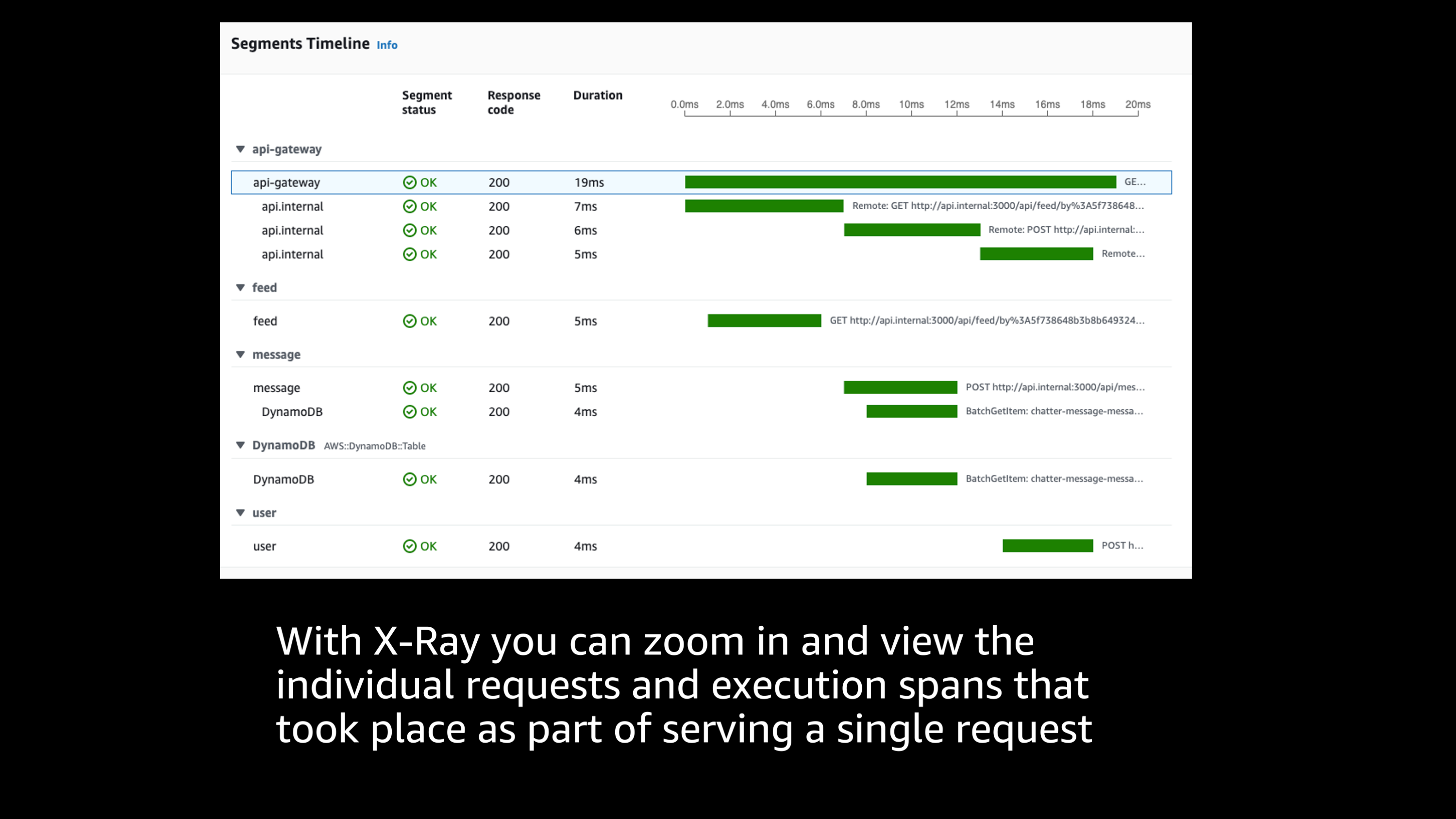
And so I can see from here that the API gateway sends a request and that there’s a variety of downstream services that are answering that request that make up the total response time.
So this particular request looks good. I can see that the total response time was only 20 milliseconds. Everything looks good, but I’m looking for one of those outliers. I’m looking for those outliers that had a really long response time.
So fortunately you can start to search by, “What was the longest response time?”
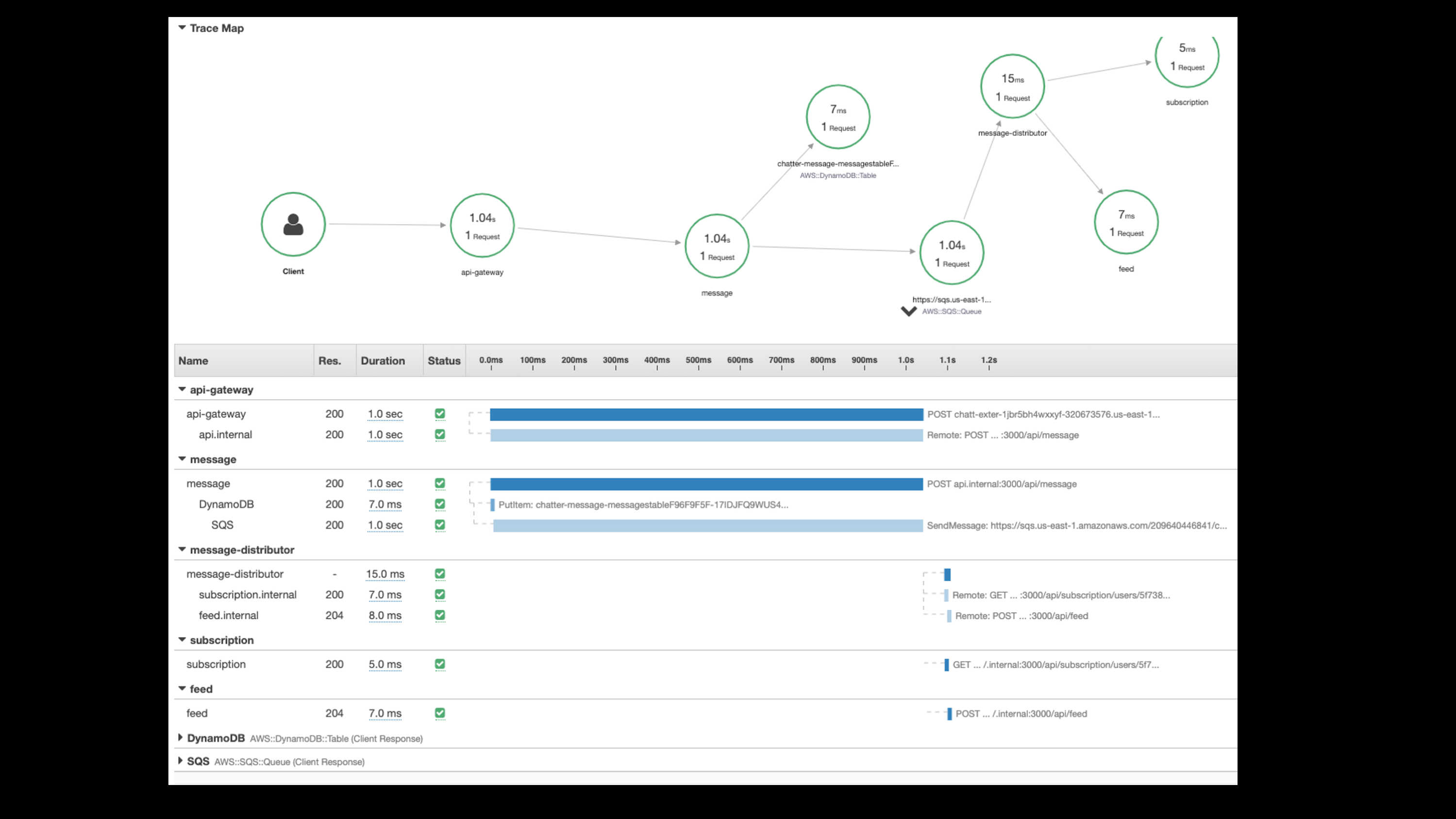
Let me sort by that and find a matching transaction spans. And so I find one here that had actual two second response time. Really long delay here. So, that’s definitely an issue.
Fortunately, X-Ray is capturing information about that transaction including a transaction ID and I can go back to my logs, my CloudWatch logs, and take the transaction ID from this trace that timed out after two seconds, and plug it into CloudWatch Log Insights.
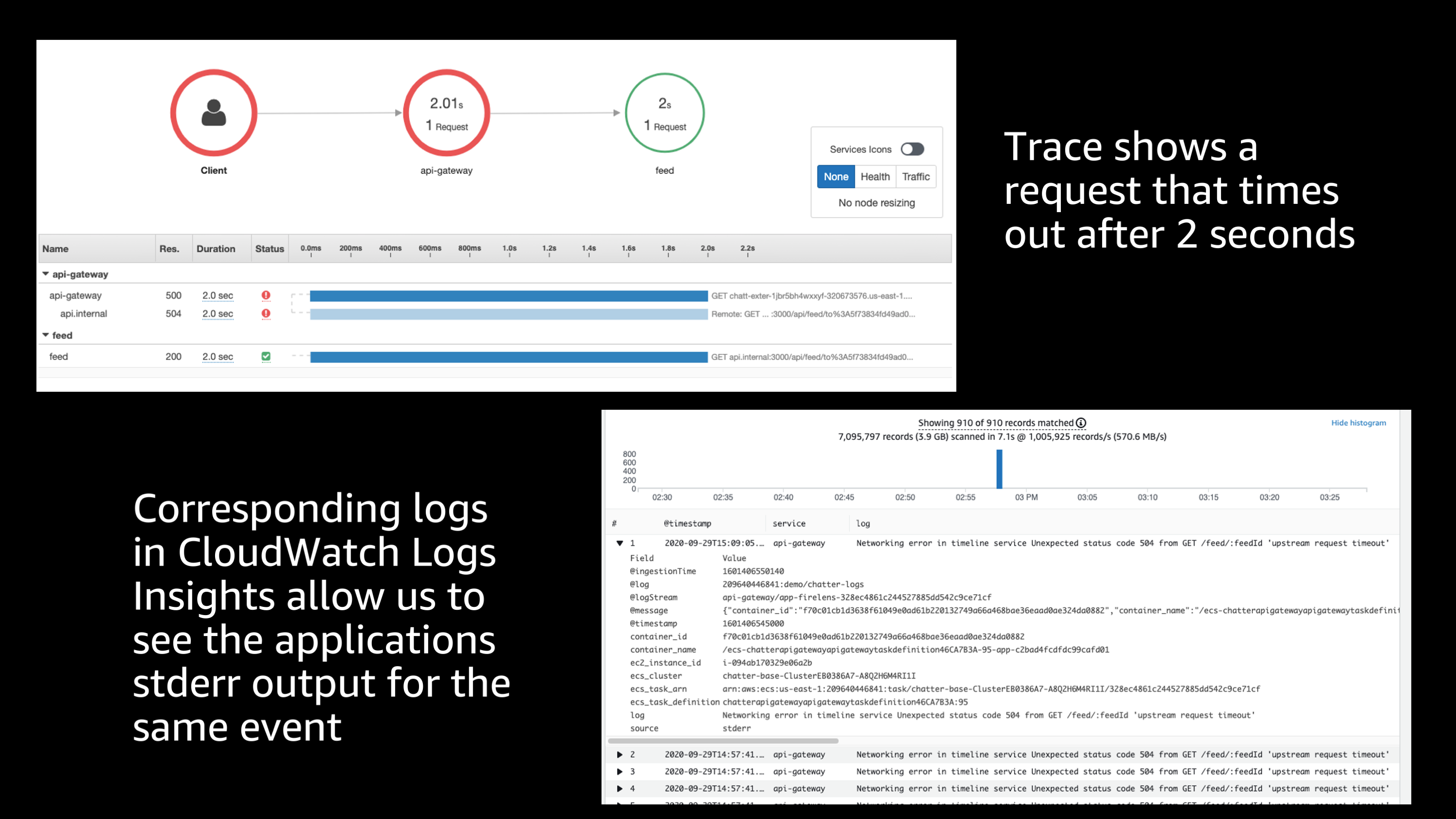
And it starts to query by that to see the application stderr output for the same event that occurred. And based on this, because I had that FireLens router that was adding extra information to my logs, I’m able to see based on that, that the task definition or application version that was running at that time was one that had a known bug that caused this delay.
So, hopefully this gives you an idea of the power of being able to go through all of this information and go from one service to the next, to look at the full end to end picture of a request. Finding an error, going through the logs and metrics to determine where that originated from, all the way down to you being able to go back to the original stderr application output that happened as part of that exact error and information about what instance it occurred on abd what application version. And all of this is super useful.
So once again, I want to show that full picture again of all of these pieces put together.
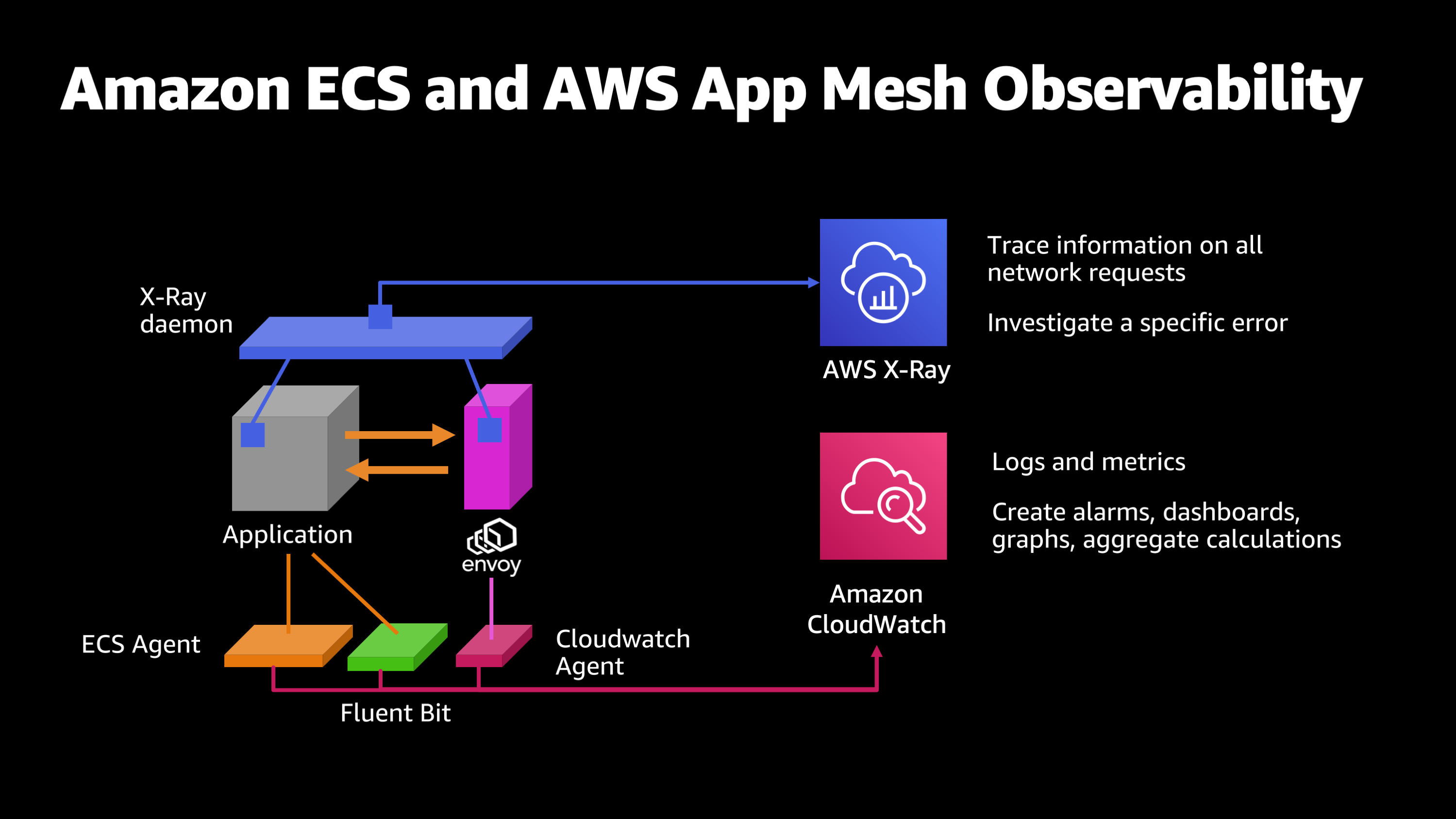
You see Amazon X-Ray, you see the ECS agent, you see Fluent Bit, CloudWatch agent, Envoy proxy. And then you see all the information is going into AWS X-Ray and Amazon CloudWatch.
I highly recommend that you check out other sessions for these different services. They go into more detail if you’re interested in learning more about each of these individual services, because I’m sure the service team members would love to tell you more about how that service in particular can function to help you with observability.

In the meantime, thank you very much for your attention, and I appreciate you attending and watching this.