
Making my Socket.io chat app production ready with Vue.js, DynamoDB, CodePipeline, and CodeBuild
This is part three of a series on developing a Socket.io and AWS Fargate powered realtime chat application on AWS.
Building a Socket.io chat app and deploying it using AWS Fargate (In part one I just packaged up an open source chat application from socket.io and deployed it on AWS as a single container deployment)
Scaling a realtime chat app on AWS using Socket.io, Redis, and AWS Fargate (In part two I made the application horizontally scalable behind an application load balancer, put ElastiCache Redis behind it for interprocess communication, and configured autoscaling triggers)
At the end of part two the application architecture looked like this:
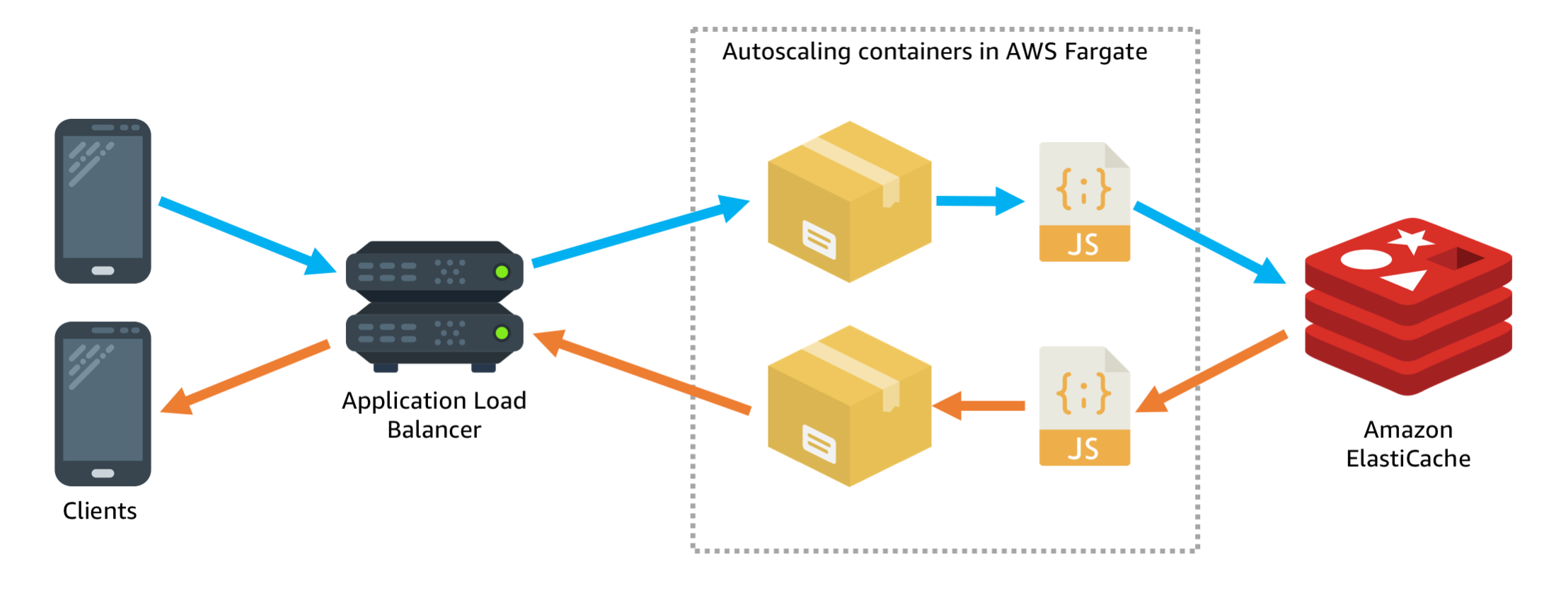
And the application itself looked like this:

There are a few more features that I’d want to see before I consider this application truly production ready:
- A user account system so people can login and persistence of messages that are sent
- A slightly less MVP looking interface
- A proper CI/CD pipeline for quicker and easier iteration on the application
Enhancing the interface with Vue.js
The first thing I wanted was to freshen up the client side interface. The original open source demo app I built on was just using some basic jQuery to manipulate the HTML, but this isn’t very scalable in terms of adding features. I did some investigation into current popular HTML + JavaScript frameworks and decided to pick Vue.js to build my frontend application. I chose this framework primarily because it felt very approachable, with easy to understand methods, and it feels much more stable compared to the constant churn of the React ecosystem.
The first step to enhancing the frontend was to find a design to work with. I’m not the greatest designer (more of a command line guy to be honest) so I need some help from others. Fortunately Bootsnipp exists, with tons of example Bootstrap designs. I found a nice chat app design and got to work making it dynamic.
Vue.js operates using three things:
- An arbitrary JavaScript object that stores state
- An HTML template
- A DOM location in your HTML document
Whenever the JavaScript object is updated Vue will evaluate the template to figure out if the DOM needs to change and if so make changes to the DOM to reflect the updates. So I just have to write something like this:
Then in my HTML I add a typing component like this:
Vue.js will automatically generate the HTML for the <typing> component, put it in the place in the document that I specified, and automatically update the HTML as the data structure changes whenever I call the addTyper() function.
This makes it very easy for me to take a plain HTML and CSS design and transform it into a dynamic application. I just need a thin layer of code to get data from the server and put it in a local JavaScript object and then Vue.js takes over the responsibility of updating the HTML as I wanted.
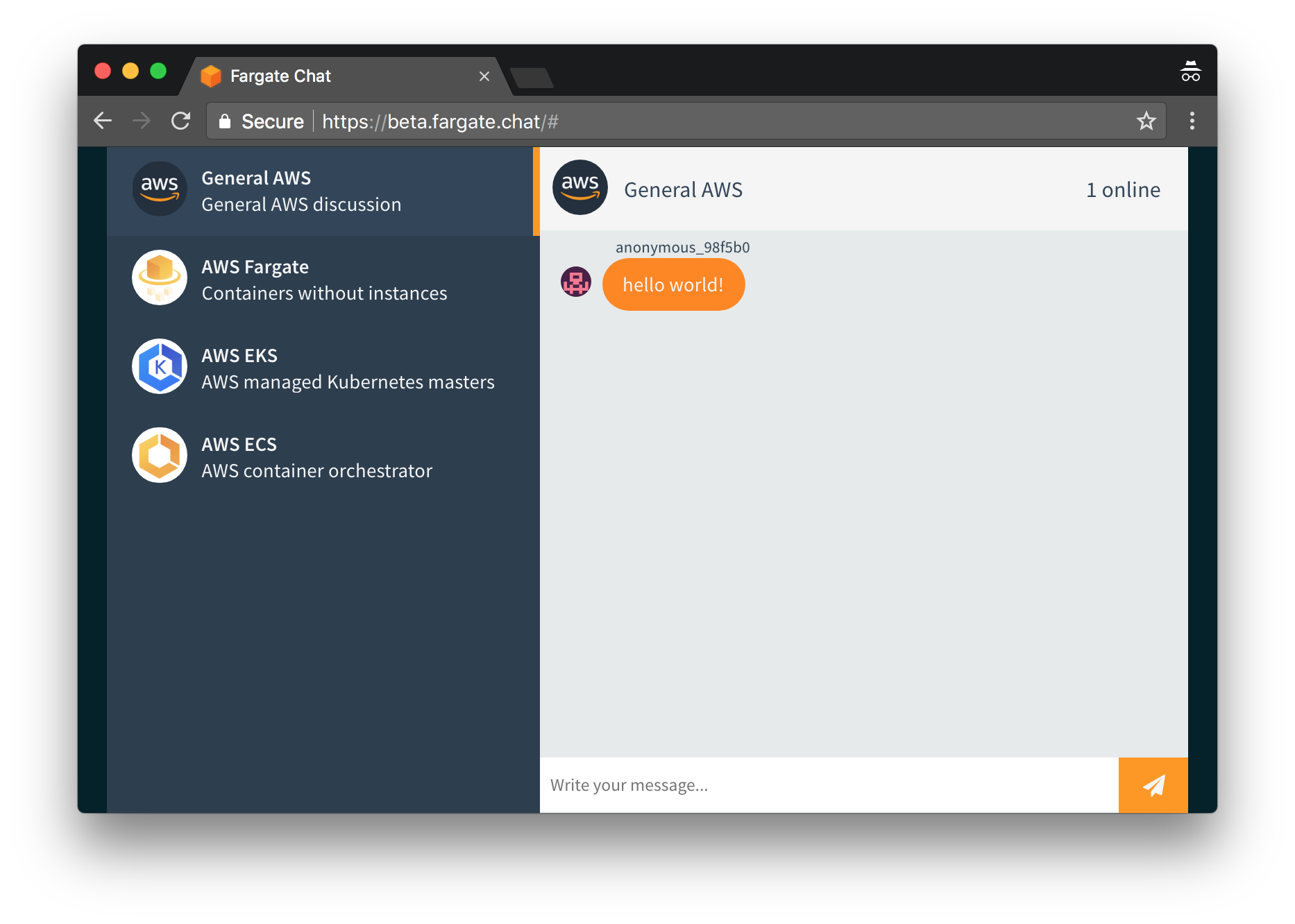
I was very quickly able to turn that basic HTML and CSS snippet into a real application connected to my backend socket.io server. You can checkout the full code for the frontend application, or just enjoy the screenshot below:
Adding message persistence with DynamoDB
One of the major features that I wanted to add to the chat application before I could consider it a production ready MVP was user accounts and message persistence. The initial bare bones version of the app kept no state at all. All messages were ephemerally sent through the Socket.io server and if you refreshed the browser tab the client side application would no longer have any messages.
To solve this problem I choose to use DynamoDB. My mindset when it comes to designing an application is that the less I have to manage the better. Additionally I like to have granular pricing, and DynamoDB fits this model very nicely with the way its read and write units work. For $10 a month I can get far more read and write units than the application actually needs, and if my traffic goes up I can just scale up those read and write units with a few clicks and not have to manage anything.
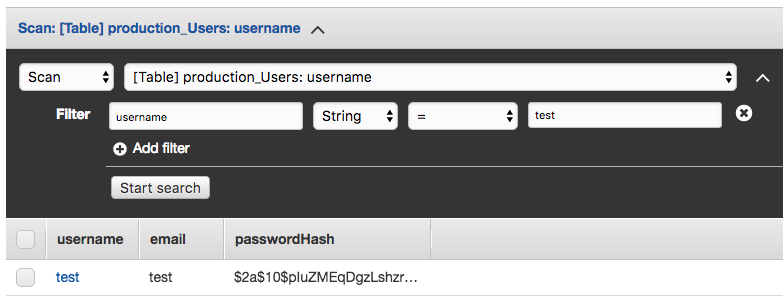
Key design is a challenge with DynamoDB though. Since DynamoDB is a key/value oriented database if I want to use it to store messages I need to carefully design my data model so that I can query it efficiently. The users table is easy. I can use a single key which is the username, and all operations to update or retrieve data from the table are done using the username:
The messages table is a bit more interesting. Because each chat room in the application has multiple messages I need both a main hash key and a range key. The hash key is just the room name. For the range key I choose the unix timestamp of the message + a randomly chosen ID:
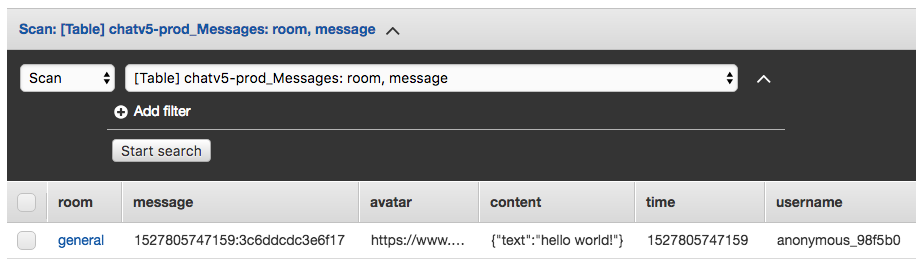
DynamoDB is a key/value store so each combination of hash key and range key must be unique. If I were to use just the room name and the message timestamp then if two messages were posted at the same time and had the same timestamp the second message would just overwrite the first. Adding the random message ID on the end ensures uniqueness for each messages key structure. The reason why I put the message timestamp first in my range key is that it allows me to retrieve messages in time order very easily with a basic table scan.
Another nice benefit of using AWS DynamoDB is that authorizing my code to talk to the database is extremely easy. I just give my task running in AWS Fargate an IAM role which authorizes it to talk to a DynamoDB table, and the AWS SDK handles authentication.
This means I never have to worry about a database password needing to be rotated or being leaked, and I have very granular control. I can define on a per task basis which tables each task has access to, and what API calls they are able to make against that table.
My architecture diagram now looks like this:
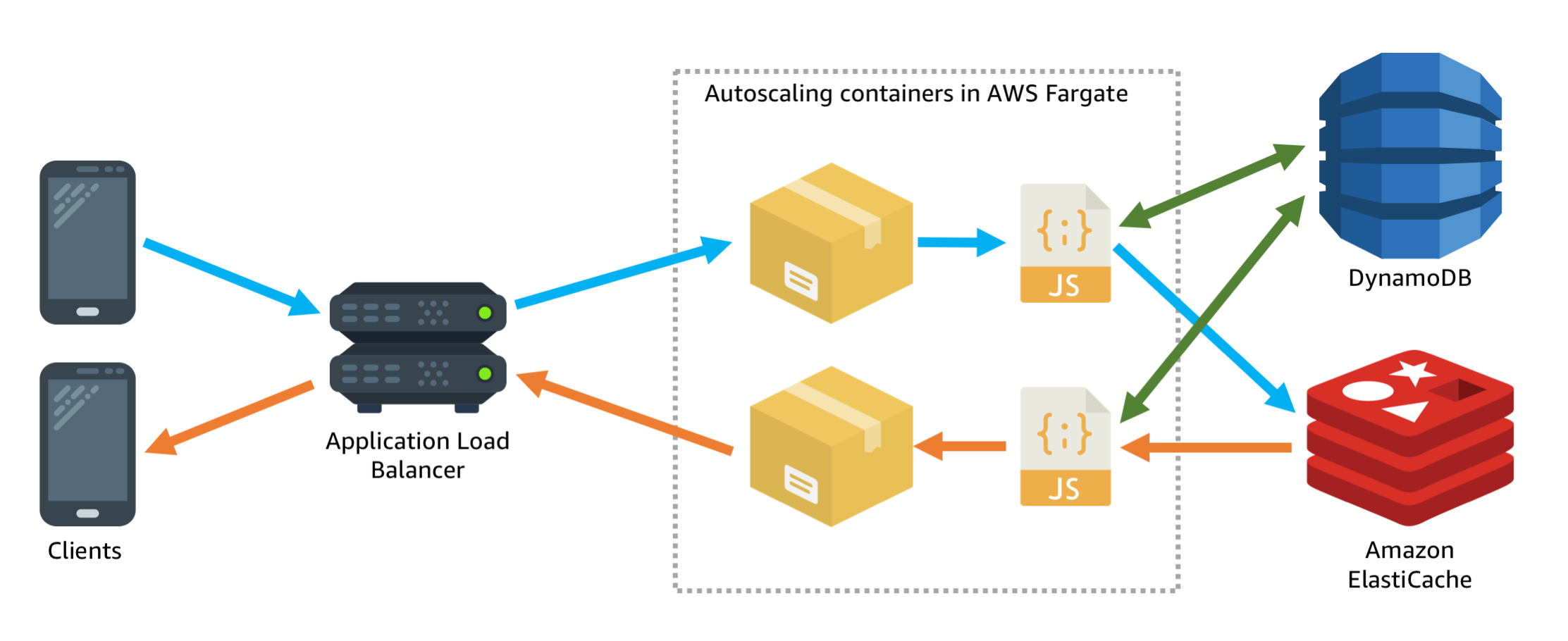
- Autoscaling container tasks in Fargate
- Amazon ElastiCache being used as a message bus between the Fargate tasks
- DynamoDB being used as durable persistence for user accounts and messages.
The missing piece: automated deployments
One last missing piece is deployment automation. As the architecture gets more pieces I really don’t want to have to deploy it all by hand. I’m already using CloudFormation to describe my architecture as code:
- cluster.yml (Create a VPC, basic networking rules, security groups, load balancer, etc)
- resources.yml (Create the ElastiCache, DynamoDB tables, and IAM role for the application)
- chat-service.yml (Launch the task in the Fargate cluster, connected to the load balancer)
In addition to deploying these three templates I also need to build my docker container using the Dockerfile, and push it to Amazon Elastic Container Registry. The build is an especially interesting part because we need to do the build on a computer somewhere. One of my goals with this architecture is to not have to run any instances myself. So I will be using AWS CodeBuild to do the build. CodeBuild will run a docker inside of docker container that does my build and pushes the built docker container to Amazon ECR.
My chosen workflow to automate this application deployment looks like this:
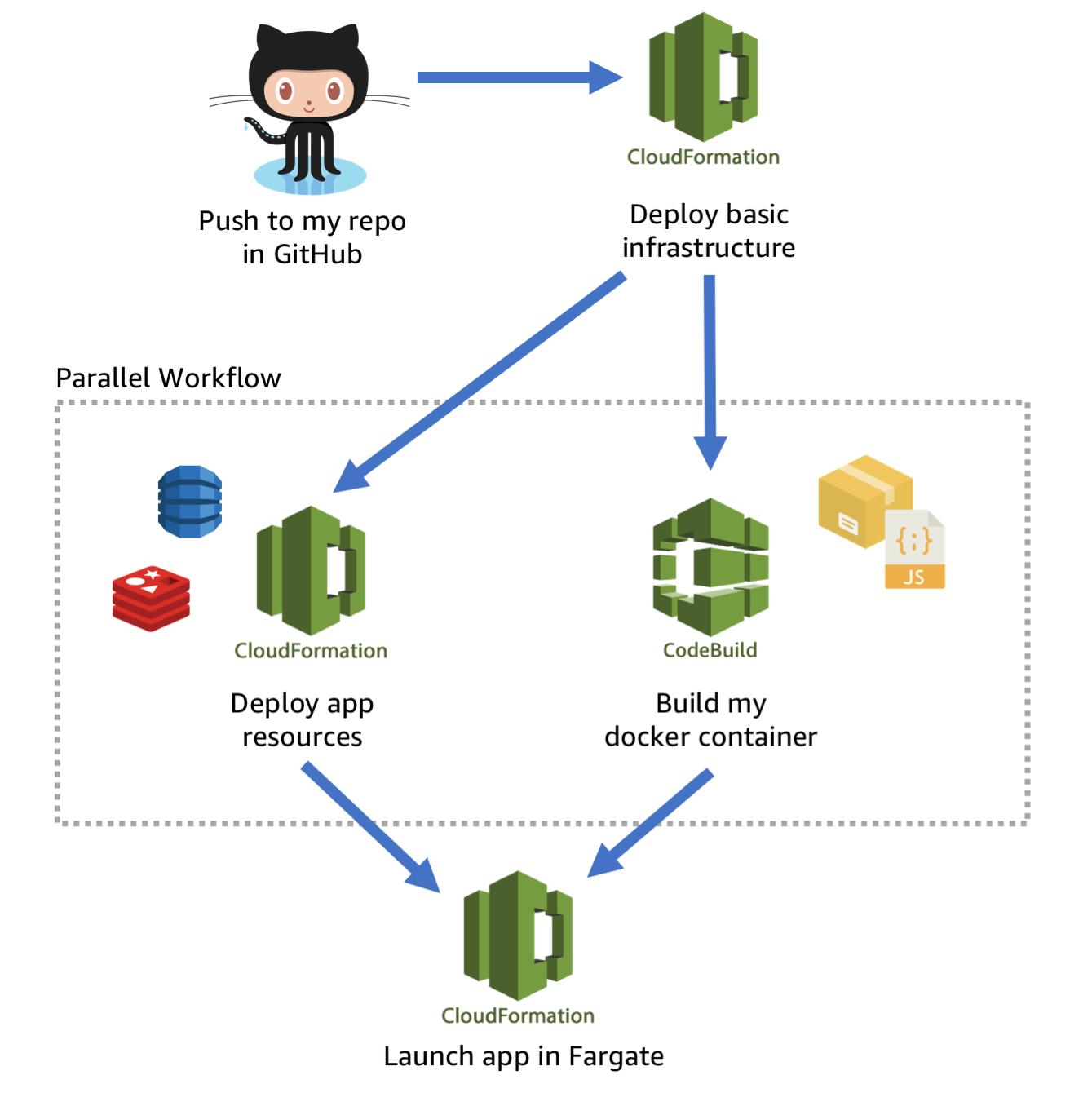
- Push my code to a git repository. All I have to do is
git commitand thengit pushand everything else is automatic. I don’t want to have to touch the AWS API or the AWS console manually. - Deploy basic infrastructure. Automatically create the VPC and networking rules using the cluster.yml template.
- In parallel build the docker container using AWS CodeBuild, and create the application’s fundamental resources such as ElastiCache, and DynamoDB tables. These steps can take place in parallel because they don’t depend on each other.
- Now that all the application resources are ready to go, we can execute the container in AWS Fargate.
In order to orchestrate this build I choose AWS CodePipeline. I define my build and pipeline stages using CloudFormation. When I deploy this single parent CloudFormation stack is creates a pipeline according to my specification:
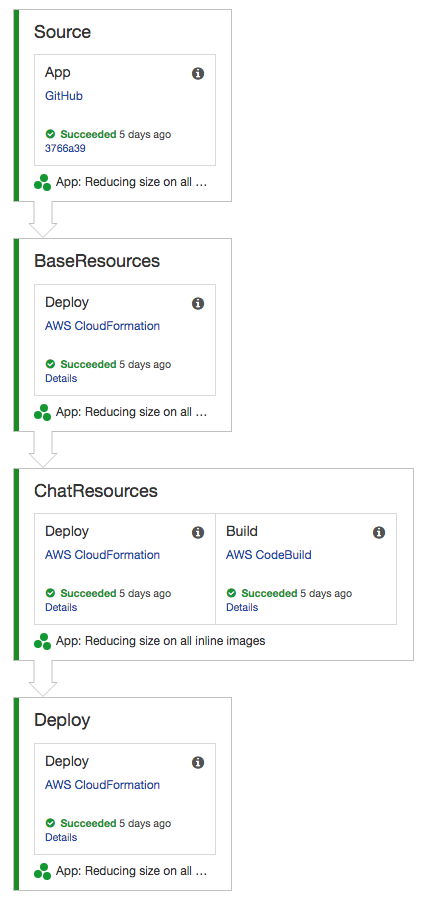
The pipeline is fast, only taking about 11 minutes end to end with a fresh environment that has nothing deployed yet. After the first run it gets even faster because the base CloudFormation template and chat application resource template is already deployed, so the only things that need to be updated is the CodeBuild and the final deploy.
Conclusion
This chat application is gradually getting more full featured, and the best thing is that is 100% open source so you can learn from the code and use techniques from it yourself. You can find the source code on Github:
https://github.com/nathanpeck/socket.io-chat-fargate
The repository also includes instructions on how to deploy the application yourself onto your own AWS account if you want to experiment with it. Or you can just check out a live running copy of the current state of the application here: