
Microservice Principles: Decentralized Data Management
Microservice philosophy favors decentralization in all aspects of software design. This focus on decentralization doesn’t just guide the organization of business logic. It also guides how data is persisted.
In the traditional monolithic approach to software design it is common to use a monolithic data store, such as a SQL server that contains a single database with many tables. This central database is used as an engine for all data persistence, and often portions of the application logic are offloaded into the SQL server in the form of queries that use complex joins, or even stored procedures.
In contrast microservice architecture favors decentralized data management, as covered by Martin Fowler’s original 2014 paper that defined microservices. This article extends the concept of decentralized data management by showing some of the modern architectural patterns for data management that lead to highly successful decentralized applications.
Thinking in REST
In order to correctly organize data in a decentralized manner it is important to first understand how to model data using Representational State Transfer, or REST for short. REST was defined in 2000 by Roy Fielding and has guided the development of many massively scalable stateless systems ever since.
The core principle of REST is to give each resource that is part of your application a URL, and then use standard HTTP verbs to interact with the resource. For example, the API for a basic social messaging app might be organized like this:
| Method | Path | Intent of request |
|---|---|---|
| GET | /users/ | Fetch a list of users |
| POST | /users/ | Create a new user |
| GET | /users/1 | Fetch user with ID 1 |
| DELETE | /users/1 | Delete user with ID 1 |
| PUT | /users/1 | Update user with ID 1 |
| GET | /messages/ | Fetch a list of messages |
| POST | /messages/ | Create a new message |
| GET | /messages/1 | Fetch the message with ID 1 |
| DELETE | /messages/1 | Delete the message with ID 1 |
| GET | /users/1/messages | Fetch list of messages written by user with ID 1 |
| GET | /users/1/friends | Fetch list of friends for user with ID 1 |
| PUT | /users/1/friends/2 | Add user with ID 2 to the list of friends for user with ID 1 |
| DELETE | /users/1/friends/2 | Delete user with ID 2 from the friends list of user with ID 1 |
This API has three primitive resource types: user, message, and friend. Each primitive type is served by a set of resource paths. In a monolith one central server would handle requests for all the resource paths, and typically this service would be backed by a single database that also stores all the resource types as tables:
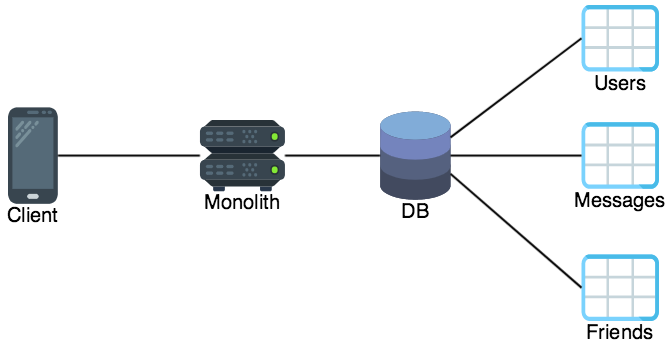
A microservices deployment employing decentralized data management would serve the three resource types using three services: one service for user resources, one service for message resources, and one service for friend relationships. In addition each service has its own database.
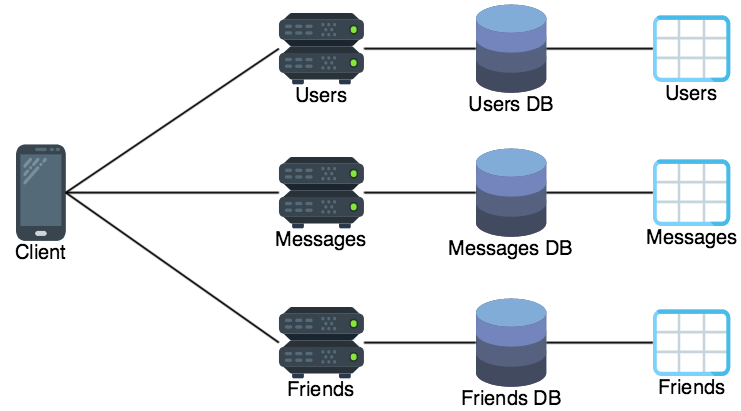
The fact that each microservice has its own database does not mean that there need to be three database servers. In the early days of a platform the three databases will probably just have a logical distinction as three databases all hosted by a single physical SQL server.
However, creating this logical distinction sets the platform up for easy physical scaling in the future. If this platform gains massive adoption the database administrator can split the three logical databases into three databases served by three different physical servers.
Avoid SQL JOIN
A critical aspect of good decentralized data management is to avoid SQL JOIN. The need for joins usually starts from efforts to make an API easier for clients to consume. For example, the messaging app we are using as an example might have a timeline view. The timeline needs to have the latest message from each friend of the authenticated user as well as that friend’s name and avatar beside the message.
With the basic REST API that we have defined the client would need to make many API calls to populate this view. For example, a user with two friends would require that the client make the following API requests in order to populate the view:

A total of five requests would be made. One request to get the list of friends of the user, followed by two requests to get the name and avatar of each friend, and two requests to get the latest message from each friend.
Obviously this is unacceptable from a performance standpoint because there is so much extra roundtrip latency between the client and the server before the view is ready to be displayed. A sensible solution to this problem would be to add a new route to the API:
| Method | Path | Intent of request |
|---|---|---|
| GET | /users/1/timeline | Fetch timeline of messages from friends of user with ID 1 |
The client can then fetch this single timeline resource to get all the data it requires to render the timeline view.
The technique used for implementing this new resource is a prime example of the difference between centralized data management, and decentralized data management. In a monolith the logic for serving this route would probably be coded as a SQL join, and offloaded to the database server, which would access all three tables to generate a result:
In a decentralized data management architecture such a SQL join is not only not advised, but actually impossible if the data is properly separated using logical and/or physical boundaries.
Instead each microservice should be the only gateway to accessing its own table. No single microservice has access to all three tables. To expose the timeline resource to a client we create an additional timeline microservice that lives on top of the three underlying data microservices and treats each as resources from which it fetches. This top level microservice joins the data from the underlying microservices and exposes the joined result to the client:
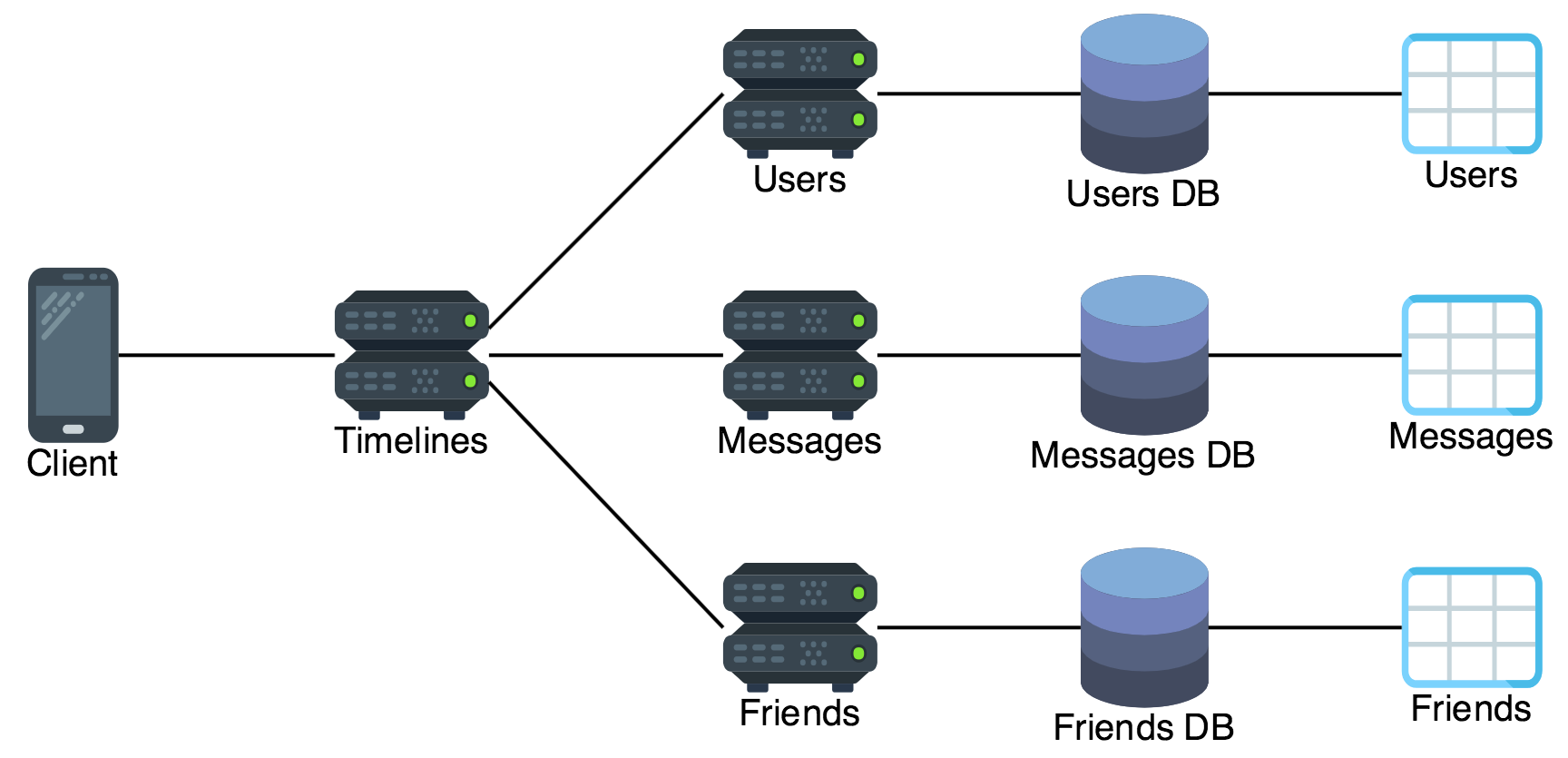
This timeline service can make requests to the backing microservices in a matter of milliseconds because the timeline service and the other microservices are hosted in the same datacenter, and perhaps in containers that are hosted on the same physical machine. To further reduce roundtrip network penalties the timeline service could also take advantage of “bulk fetch” endpoints. For example the user microservice could have an endpoint that accepts a list of user ID’s and returns all matching user objects, so that the timeline service only has to make one request to the friends service, one request to the user service, and one request to the message service.
The timeline service functions as a centralized place to define the logic for what a timeline is. If business requirements change and the client now needs to display the latest two messages from each friend then this can easily be changed in the timeline service without needing to make modifications to the other backing microservices that actually host the basic resources.
Additionally the separation between how the data is stored and how the data is manipulated for display to users allows the underlying microservices to be refactored, as long as they continue to adhere to the resource format that the timeline service expects. The maintainers of the friend service could easily rewrite how the friend relationships are stored without breaking the timeline service. On the other hand the use of join queries requires all joins against a table be reviewed and updated if you need to update the table structure.
Eventual Consistency
One of the side effects of decentralized data management is the need to handle eventual consistency. In a centralized data store developers can use transactional capabilities to ensure that data is in a consistent state between multiple tables. However, this is not the case when data is separated into different logical or physical databases.
For example, consider what would happen if a user fetched their timeline at the exact same moment that one of their friends deleted their account:
- Timeline service fetches list of friends from the friend service and sees a friend ID that it needs to resolve
- Friend deletes their account, which deletes the user object from the user service, as well as all the friend references in the friend service
- Timeline service attempts to turn the friend ID into user details by making a request to the user service, but receives a 404 Not Found response instead
Decentralized data modeling requires extra conditional handling to detect and handle such race conditions where underlying data has changed between requests. For the case of a simple social media application this is typically easy. But for a more complex application it may be necessary to keep some tables together in the same database to take advantage of database transaction. Typically these linked tables would also be handled by a single microservice. Alternatively if related data needs strong consistency but is still to be decentralized it may be necessary to use a two-phase commit in order to manipulate it safely.
Polyglot Persistence
One significant advantage of decentralized data management is the ability to take advantage of polyglot persistence. Different types of data have different storage requirements:
- Read/Write Balance (Some types of data have a very high write volume. This can require a different type of data store compared to data that has low write volume but high read volume.)
- Data Structure (Some types of highly structured data such as JSON documents may be better stored in a NoSQL database such as MongoDB, while flat relational objects may be more efficiently stored in a SQL database.)
- Data Querying (Some data may be accessible using a simple key value store, while other types of data may require advanced querying based on the values of multiple columns.)
- Data Lifecycle (Some data is temporary in nature and can be stored in a fast, in-memory store such as Redis or Memcached, while other data must be retained for all time and needs very durable storage on disk.)
- Data Size (Some data is made up of fairly uniform rows of consistent byte size, while other data may include large blobs that need to be stored in something like AWS S3.)
For the example social messaging app each message is actually a structured JSON document that contains metadata about media files, geolocation, etc. Additionally, it is expected that there will be many users posting messages, and the total number of messages that need to be persisted will grow quickly. For this scenario the team in charge of messages may choose to utilize a sharded MongoDB cluster to persist this structured JSON data.
On the other hand the user and friendship tables have a simple, flat data model and do not grow as quickly, so those services are backed by a Postgres server.
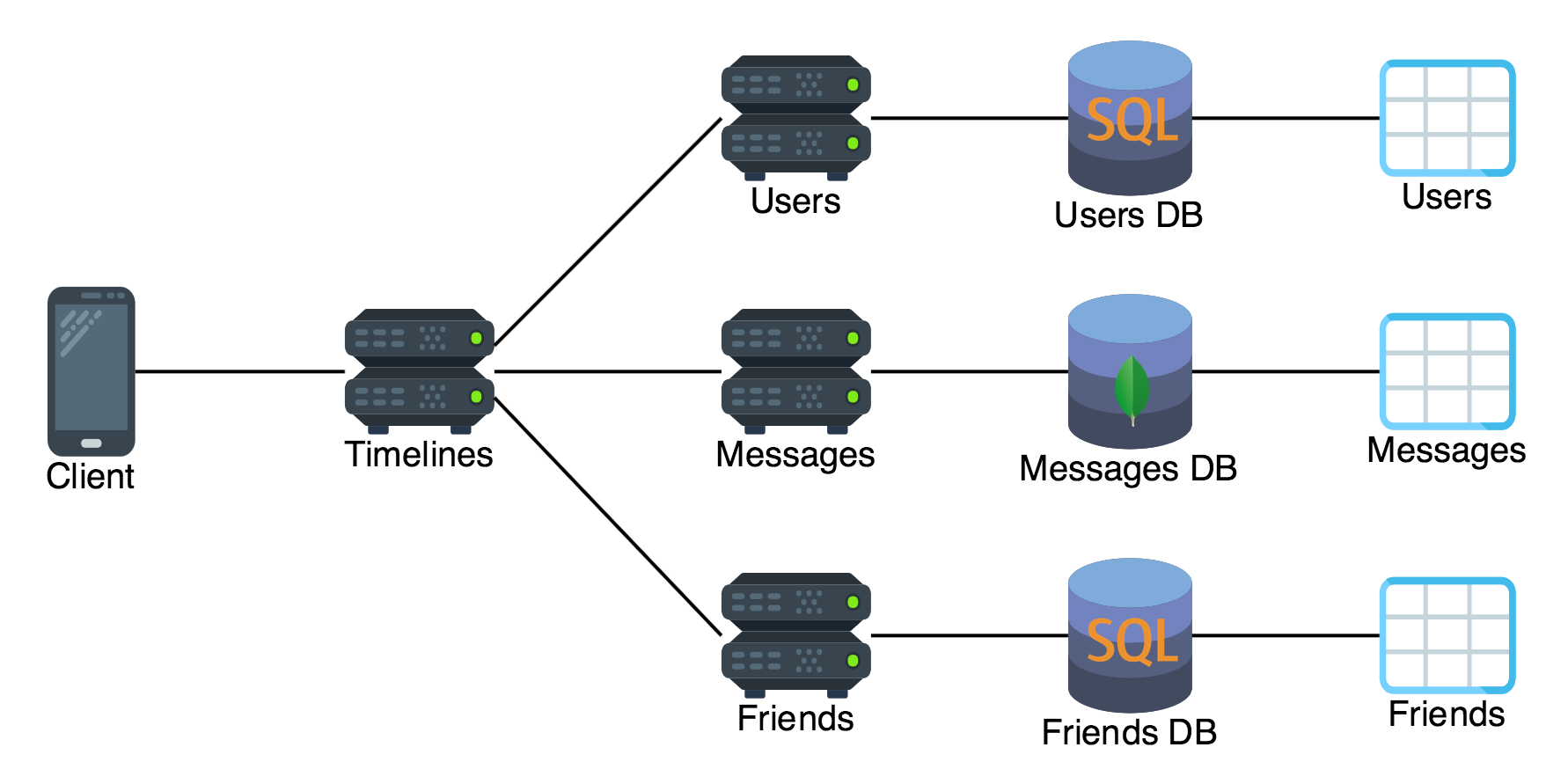
Because this application is utilizing decentralized data management principles it is able to take advantage of polyglot persistence and store the different types of data in different databases that serve the needs of that particular data type.
Conclusion
Decentralized data management can be properly deployed by starting from REST basics to figure out the separations between different resource types. These separations should then drive microservice and database boundaries. Where multiple types of resources are required to serve a composite resource to a client this can be built by using a higher level microservice that joins data from different underlying microservices. This requires careful handling of eventual consistency, but it allows the use of polyglot persistence to store different types of data in storage providers that best handle that type of data.