
Microservice Principles: Decentralized Governance
One of the most important realizations that a software engineer can make in his or her career is that there is no single perfect tool for solving every computer science problem, and that different tools should be employed in different circumstances. The junior engineer has mastered the use of one or a few tools to implement a feature according to specifications within a pre-established framework. The senior engineer has mastered a wide range of tools and is capable of architecting and designing a system from scratch, including picking the right tools and frameworks that best solve a problem.
Highly successful software companies tend to share a common characteristic: just like a senior engineer, the engineering team as a whole chooses the right tool for the job because they are encouraged to do so by an underlying culture of decentralized decision making. In order to avoid developing a software monoculture that would hinder their ability to deliver high quality software, these companies have embraced a development philosophy called “decentralized governance”, as explained in Martin Fowler’s 2014 paper defining microservices. This article explains ways to enable and encourage a engineering culture of decentralized governance.
A Practical Example of Decentralized Governance
To understand what decentralized governance means and how it works, consider an imaginary game studio that has employed decentralized governance to successfully build an ecosystem of software that serves their customers. This game studio has an overall mission: they want to provide a fantastic experience for gamers. A mid-sized engineering team is responsible for delivering on this mission by building and maintaining a variety of different services:
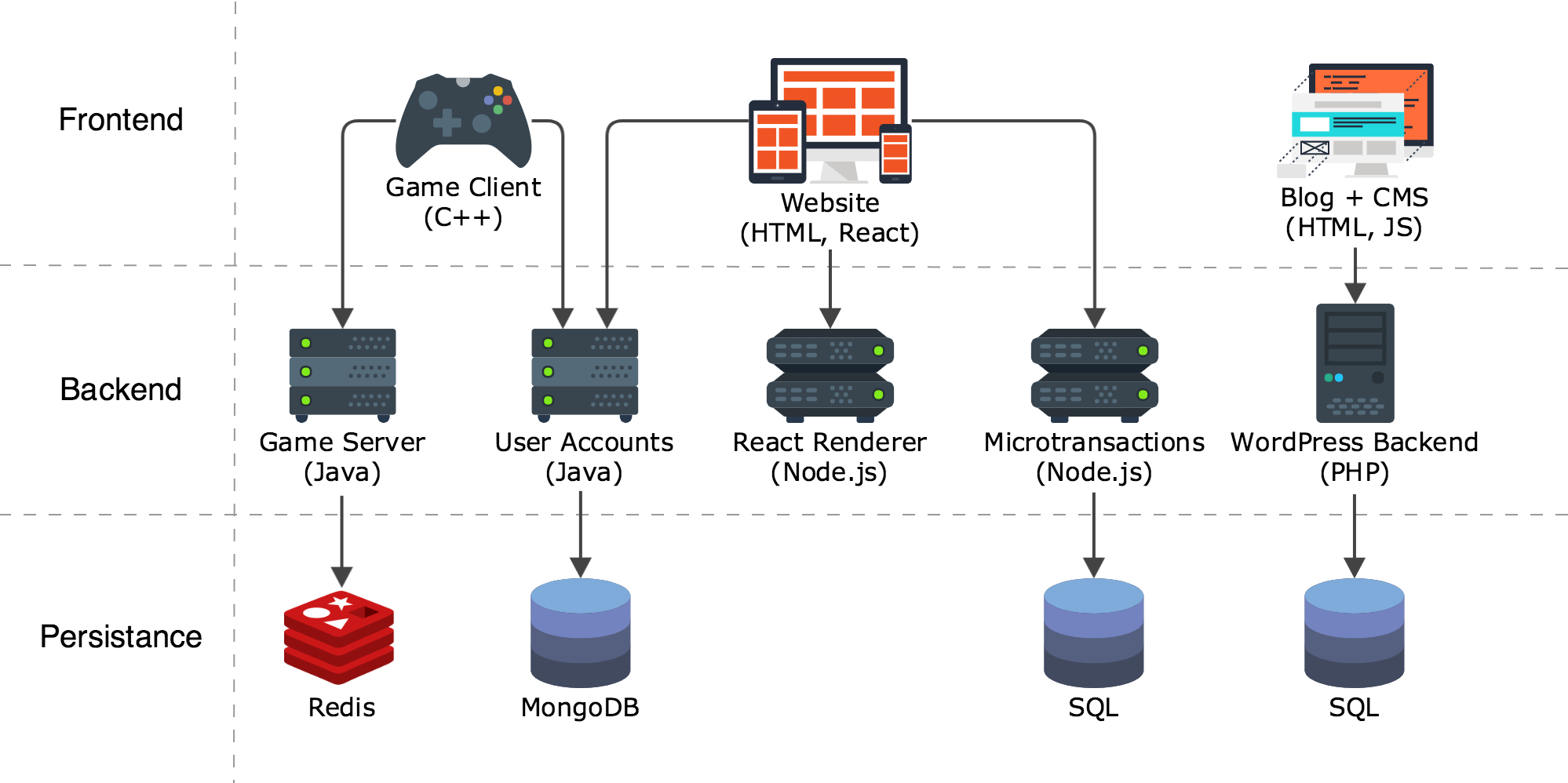
- Game Client (Engineers have chosen to use C++ to build the game client, so that they can provide the highest performance experience possible, even on machines that are a few years old.)
- Game Server (The server side team decided to use Java to implement the game server because they wanted high performance and static types, but felt it would be hard to avoid memory leaks or dangerous server side exploits if they used C++. They chose to store game state in Redis for the fastest performance.)
- User Accounts (The user account server was built to handle login and user profile data. It was implemented in Java because of overlap between the game serve team and the account team. It was also developed as a stateless application that uses MongoDB to persist the structured JSON metadata about the user’s account.)
- Website (The front page of the site is HTML and JavaScript that powers interactive elements such as login, account profile modification, and a microtransation store. The team chose to build using React, with server side rendering using Node.js)
- Microtransactions (The game studio makes money by selling virtual items that players can use in the game. The team built a stateless API for this using Node.js, because there is some engineering overlap between the marketing site and the microtransactions API. They choose to use SQL to persist the microtransactions data because they want to use SQL transactions to avoid “double spend”.)
- Community Blog (The community blog is used for announcing game updates, and other game related content. The community team has chosen WordPress as their CMS, so they run PHP, with a SQL backend.)
The CTO of this fictional game studio has employed decentralized governance by allowing each team to be responsible for choosing the best tool for the job. It is highly unlikely that this CTO is intimately familiar with all the specifics of each of the software tools that their team has used to deliver microservices for each feature, but they trust that each team has the knowledge and ability to make the right choice, so they don’t limit teams to using only technology that they are personally experienced in.
The result is that each subsection of the engineering team is able to deliver the best experience that they possibly can instead of being hindered by trying to implement a feature using a centralized technology stack.
Standards, not Specifics
Decentralized governance gives teams the freedom to develop software components using different stacks, but this does not mean that software development should become a “wild west” environment where anything goes. An engineering organization should not try to decree all the specifics of how software is built by each team but it should define some global standards that apply to the methodology behind the software.
A couple examples of good standards are:
- All code should be run through a linter before merge
- All teams should use a peer code review process
Despite these centralized standards there is room for decentralized specifics. For example, the engineering team may choose to use a linter on all projects, but not have a central set of linter rules. Instead each team can pick their own linter rules for their own component. Perhaps the team building C++ wants to use tabs in their code, while the team building in Node.js wants to use spaces.
The goal of global use of a linter isn’t to force all teams to write their code in the exact same way. Instead, using the linter as part of the code commit process allows engineers to contribute to multiple components while ensuring that their code contributions will match with the decentralized formats that have been chosen for each component. The linter is an enabler of decentralized governance.
As another example, perhaps the game studio mentioned earlier considered the diverse set of backend runtimes that need to be deployed on their servers and they decided to set a standard of using docker containers to deploy their microservices:
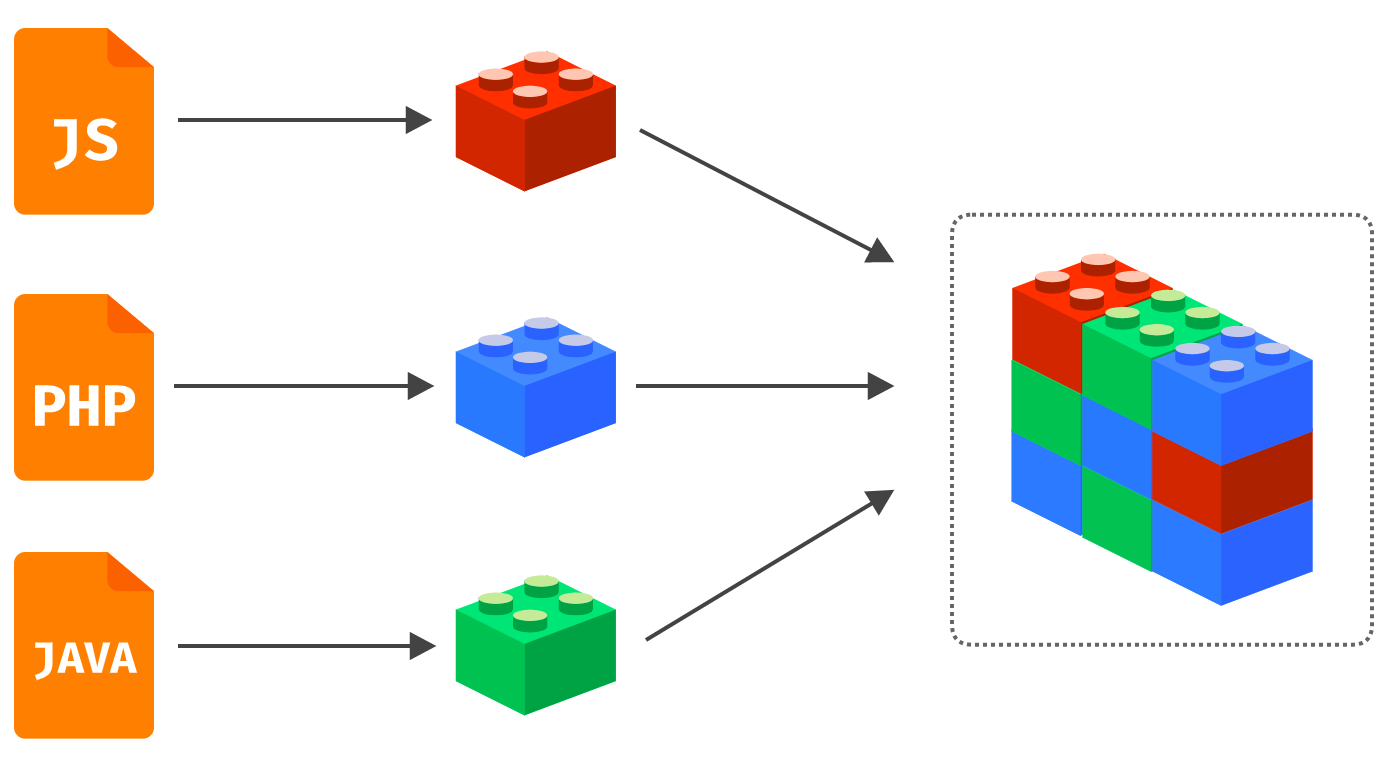
Each team can write code in their language of choice, and choose their own system dependencies and settings, but the engineering organization has a standard that each team must provide a Dockerfile that builds the software and produces a docker container that encapsulates all the specifics of that component. The resulting docker image can be run in a standard way on any backend server using an orchestration tool such as Amazon Elastic Container Service or Kubernetes.
This approach encourages decentralized governance because it allows teams to have a standardized build approach, which allows a common CI/CD pipeline to be utilized. Additionally, the use of Docker containers helps with deploying the resulting polyglot platform in such a way that microservices written with different runtime requirements do not interfere with or break each other.
In summary, decentralized governance doesn’t mean that there are no common standards to how software is built. Rather it means that standards are chosen which enable the team to better build and deploy the code that they have created according to their individual governance plans.
You Build It, You Run It
One of the most powerful approaches to decentralized governance is to build a mindset of “devops” in which engineers are involved in all parts of the software pipeline: writing code, building it, deploying the resulting product, and operating and monitoring it in production. The devops way contrasts with the older model of separating development teams from operations teams by having development teams ship code “over the wall” to operations teams who were then responsible to run it and maintain it.
The old model generally looked like this:
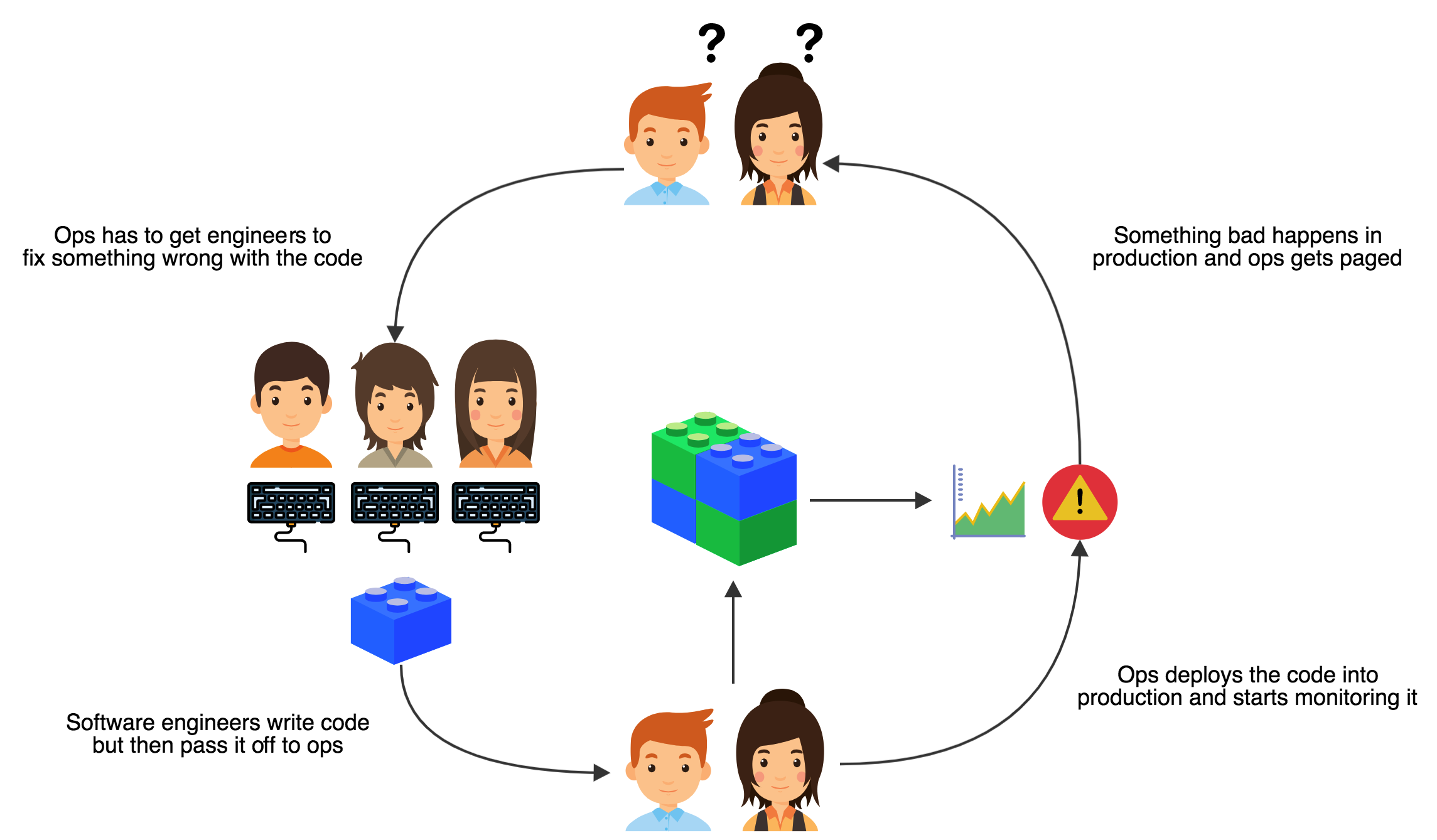
The problem with this model is that the separation between the software engineers and the operations engineers introduces extra steps whenever there is a critical issue with the code. Because operations didn’t write the code they probably don’t understand what is wrong with it, so they have to hand things off to software engineers whenever there is an application bug causing an issue. Because software engineers aren’t involved with operations they don’t have enough understanding of how the code they write affects the overall operation of the platform, other than what ops engineers are complaining to them about.
The “devops” model is aimed at tightening the feedback loop and blurring the line between software engineers and operations engineers:
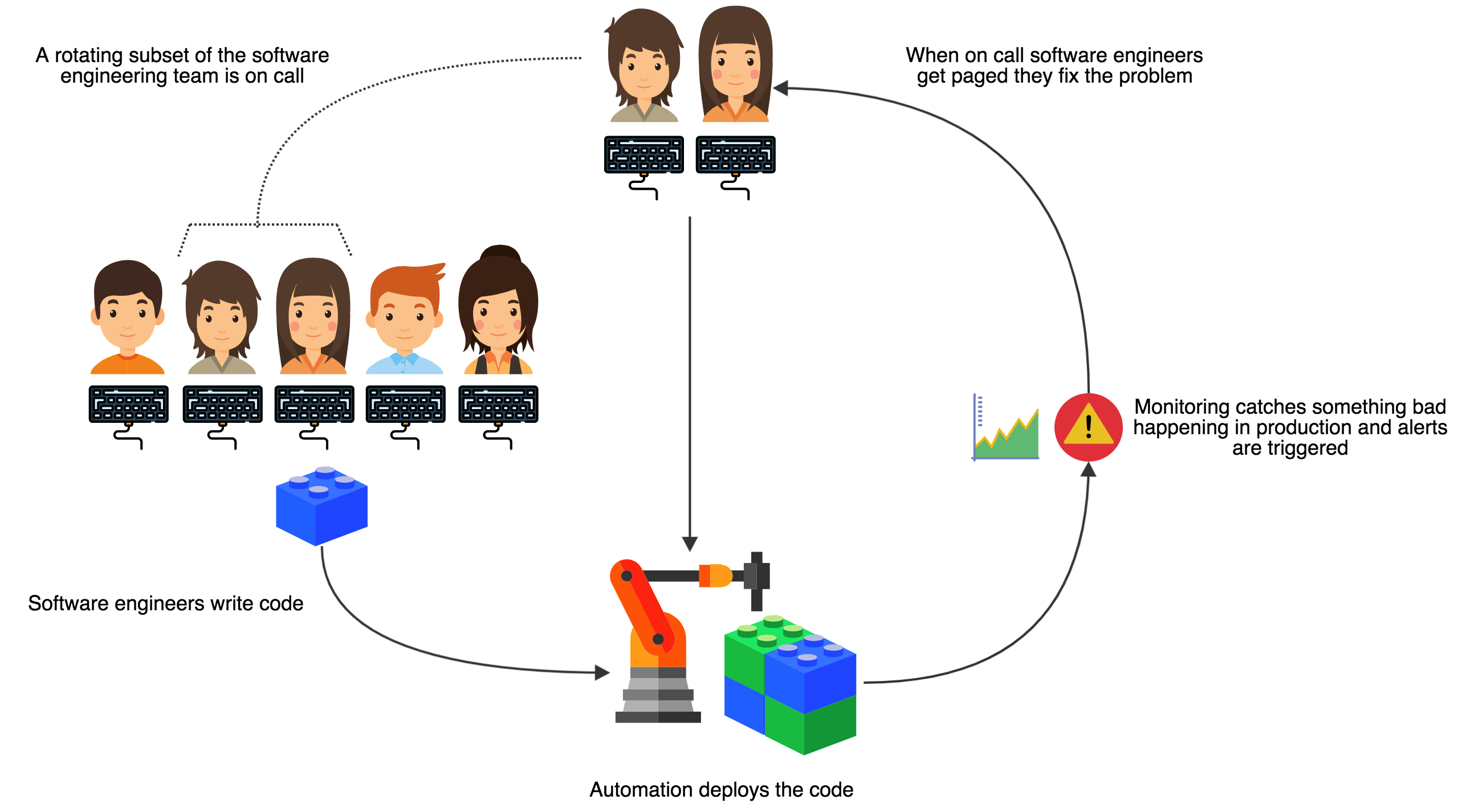
Rather than having operations engineers manually deploying code, in the devops model all the deploys are done using automation which is developed by software engineers. This gives the developers increased visibility and control over how their software is deployed in production. Additionally rather than having a separation between “those who are on call” and “those who write the code” the devops model puts developers who wrote code in a place of responsibility with regard to crashes, outages, and performance issues in production. Not only does this give them increased visibility into the real world performance of their code, but it also helps them learn how to write or refactor code to perform well in production.
With the devops model software developers are never blocked from releasing something by operations. Instead the entire pipeline from initial concept, to writing code, to running a live service is accessible and under developer control. This is the ultimate end goal of decentralized governance, as it allows each service team to fully control the creation, the operation, and the maintenance of its own service.
Conclusion
The goal of decentralized governance is to free a software engineer team to solve development problems more efficiently and with greater velocity. Rather than forcing a uniform monoculture with regard to how code is developed engineering organizations should carefully choose standards that allow different teams to pick their own specifics within the scope of what the standards allow. Additionally, its important to develop a devops mindset within the engineering organization so that developers are more in control of how their individually governed components are built and operated.