
Answering some misconceptions about AWS Cloud Development Kit
You might know me as a strong advocate for AWS Cloud Development Kit (CDK). I feel that CDK is one of the best ways to create your infrastructure on AWS so I spend a fair amount of time talking about CDK and writing and sharing example code. Along the way I’ve noticed some misconceptions that I think should be addressed.
What is AWS Cloud Development Kit?
If you haven’t heard of CDK yet, then you should know that it is an open source software development kit to define your cloud application. CDK supports most of the popular programming languages for writing application code. It is likely that you can use CDK in the same language you are using to write your application code. With CDK you can write code in an imperative language, which generates declarative descriptions of resources to create. For example I can define a simple Lambda function which reads items from a DynamoDB table like this:
const myDynamoTable = new dynamodb.Table(this, 'items', {
partitionKey: {
name: 'itemId',
type: dynamodb.AttributeType.STRING
},
tableName: 'items',
});
const myLambdaFunction = new lambda.Function(this, 'getAllItemsFunction', {
code: new lambda.AssetCode('src'),
handler: 'get-all.handler',
runtime: lambda.Runtime.NODEJS_10_X,
environment: {
TABLE_NAME: dynamoTable.tableName,
PRIMARY_KEY: 'itemId'
}
});
myDynamoTable.grantReadData(myLambdaFunction);These few lines of CDK code create an infrastructure as code description of the architecture behind the scenes. In this case CDK is generating a CloudFormation YAML description of the infrastructure, which is then deployed using CloudFormation to create real resources on your AWS account. In most cases a few lines of CDK calls can expand into hundreds or even thousands of lines of underlying YAML configuration.
Now let’s look at a few misconceptions about AWS CDK.
Misconception #1: You should use CDK because YAML isn’t a real language
This is false. YAML is definitely a real programming language. If you don’t believe me look at some of the advanced Ansible YAML docs for loops and conditionals. Or look at this block of YAML which uses YAML anchors and references to generate a billion laughs attack:
a: &a ["lol","lol","lol","lol","lol","lol","lol","lol","lol"]
b: &b [*a,*a,*a,*a,*a,*a,*a,*a,*a]
c: &c [*b,*b,*b,*b,*b,*b,*b,*b,*b]
d: &d [*c,*c,*c,*c,*c,*c,*c,*c,*c]
e: &e [*d,*d,*d,*d,*d,*d,*d,*d,*d]
f: &f [*e,*e,*e,*e,*e,*e,*e,*e,*e]
g: &g [*f,*f,*f,*f,*f,*f,*f,*f,*f]
h: &h [*g,*g,*g,*g,*g,*g,*g,*g,*g]
i: &i [*h,*h,*h,*h,*h,*h,*h,*h,*h]There are extensions to YAML that allow you to use extra commands such as !include for including one YAML file inside another file. There are definitely YAML experts out there that could add half a dozen even more advanced things I’m missing here.
YAML is extremely powerful, and those who work with it in advanced ways deserve great respect. That said, it’s normal for server side software that accepts YAML as input to deliberately choose not to support these more advanced features and extensions of YAML. Server side software expects a basic, static YAML file. And that is understandable because accepting arbitrary user input is a dangerous job for any bit of code. And it only gets more dangerous when the logic of parsing and processing the input format is more complicated.
You can still write advanced YAML and run it through a preprocessor (sometimes also called a template engine). This preprocessor evaluates loops, includes, anchors and references right there locally on your dev machine. The final product is a static YAML artifact that can be sent to a server side infrastructure as code provider. This pattern of using a local preprocessor to generate your final YAML is growing in popularity. For example see Kustomize for Kubernetes or Jsonnet.
AWS CDK is another tool to help you generate your final static YAML artifact. It’s not that YAML is bad. YAML preprocessing is just a client side job, not a server side job, so you need a local dev tool to do the advanced bits. In my opinion CDK is an elegant tool for accomplishing this YAML preprocessing. It is approachable for developers, because it does not require learning as many completely new things. You can benefit from your pre-existing knowledge of the programming language you already use day to day, and use that language to generate static YAML for the other underlying tooling.
Misconception #2: CDK is imperative and infrastructure as code should be declarative
You can write CDK code in an imperative language. However you can also use CDK with a declarative language. For example you can actually use declarative, static YAML to define your CDK app. CDK consumes this input YAML and then as its final artifact produces a different static YAML file for CloudFormation. This tool for CDK is called decdk.
The second thing to understand here is that even if you write CDK code using an imperative language the end product of CDK is a declarative artifact. The following diagram summarizes the flow:

- Developers write code that calls the CDK SDK. This code is probably written in an imperative language
- CDK transforms these SDK calls into a declarative format such as CloudFormation
- CloudFormation uses this declarative description of what to create and makes imperative API calls to create the infrastructure on your behalf
- You have infrastructure for your application.
Personally this flow works well for me and I trust that CDK will produce a sensible declarative template, so I rarely work directly with CloudFormation. I just let CDK handle that for me. If you do have worries about the imperative code introducing reproducibility problems you can tell CDK to give you the generated templates to commit to your source code repository and/or deploy separately later.
The main thing that should be understood is that CDK is based on declarative fundamentals under the hood, even if you choose to interact with its API using an imperative language.
Misconception #3: You only need CDK if your infrastructure is complex
This one is a bit subjective. I personally believe that CDK benefits you tremendously no matter how simple your infrastructure is. Let’s consider a really simple application: a mobile client talks to a load balancer, which distributes traffic to one or more instances of your application code. Your code reads from and writes to a database table.
If you were planning this on a whiteboard you’d probably represent such an architecture with a diagram like this:
However when you want to write the infrastructure as code for this simple setup you will quickly run into a lot more pieces that you need to think about:
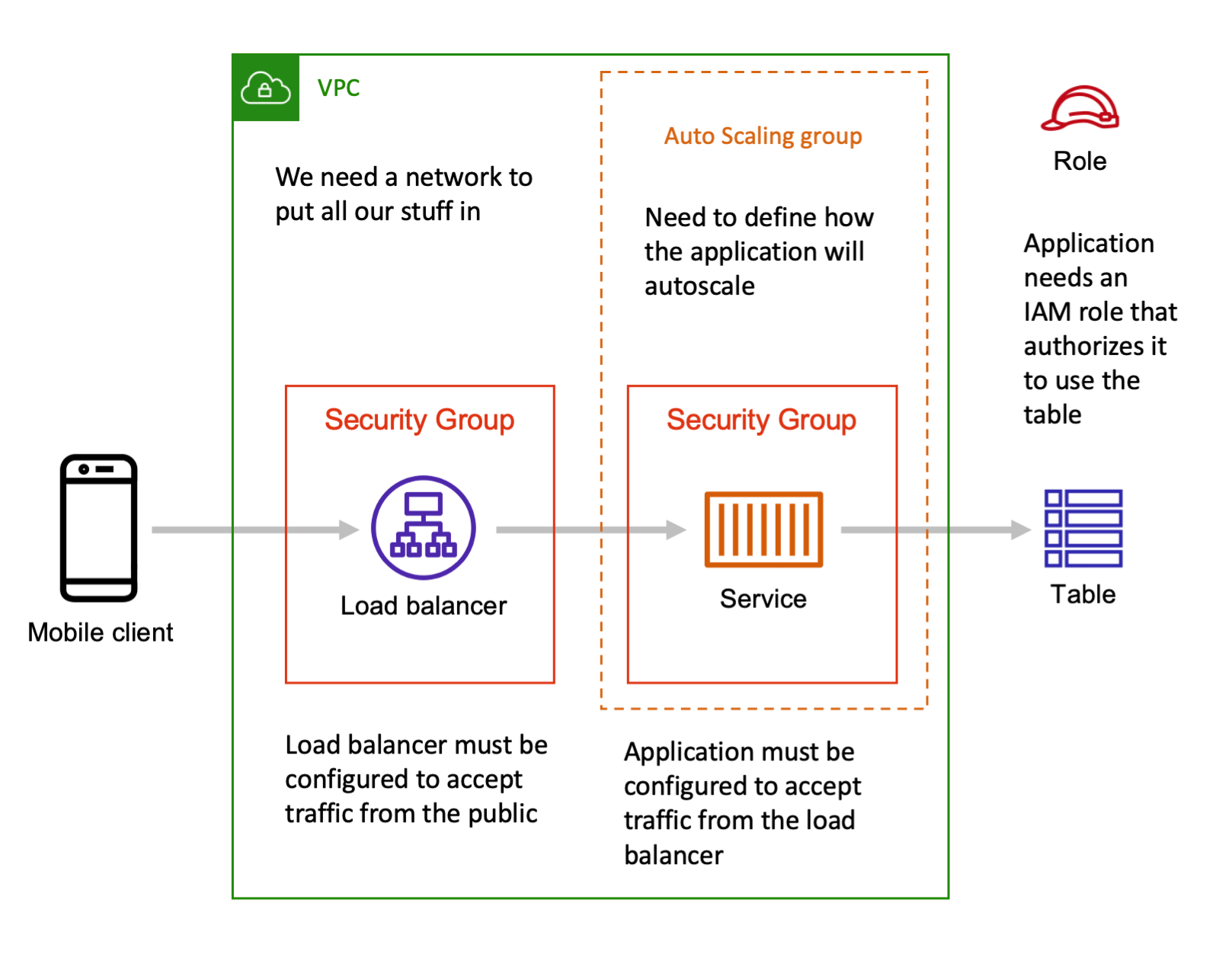
In specific you need networking configurations, security groups and rules to authorize the network connections, and IAM roles and policies to authorize the application to use the table. And you probably want to configure some autoscaling as well. These are all very good things!
If you are defining all these architecture bits using a low abstraction infrastructure as code tool like CloudFormation you need to create the IAM roles and security groups by hand. CloudFormation does not know what your broader intent is for this architecture so it is up to you to get your security group rules right. You need to figure out and enter the right values to manually create these CloudFormation resources for your security groups and IAM role policies.
Let’s look at some CDK code for comparison:
myDynamoTable.grantReadWriteData(myLambdaFunction);Rather than writing an IAM policy out by hand, the constructs in AWS Cloud Development Kit encompass multiple resources. The Lambda function comes with its own IAM policy automatically, and I can use a simple method to indicate my intent for the DynamoDB table to be read and written to by the Lambda function. This single line of CDK code automatically attaches the right minimal IAM policy to authorize that single Lambda function to read and write data from that single table.
When it comes to network connections there is a similar API interface: load balancers, databases, EC2 instances, containerized services, and other constructs automatically come with their own security groups and I can use the Connections interface to authorize connections between these security groups. For example:
myService.connections.allowToDefaultPort(myDatabase);As you can see myService comes with a connections interface automatically. That interface defines a default security group that starts out with no access to other things in the network. The database also comes with its own connections interface and security group. The database connections interface is aware of what port it utilizes, for example port 3306 for a MySQL database instance. So this AWS CDK statement is able to automatically configure the security groups of these two constructs to allow the service to talk to the database on port 3306.
When it comes to autoscaling, if you have used CloudFormation by hand you are no doubt aware that configuring autoscaling requires defining an autoscaling target with AWS::ApplicationAutoScaling::ScalableTarget and likely at least two AWS::CloudWatch::Alarm resources for high and low points to trigger scaling actions. But here is how I configure autoscaling on an containerized service using CDK:
const scalableTarget = myService.autoScaleTaskCount({
minCapacity: 1,
maxCapacity: 20,
});
scalableTarget.scaleOnCpuUtilization('CpuScaling', {
targetUtilizationPercent: 50,
});Once again the service construct is aware that it is scalable. I can enable autoscaling by interacting with my service itself, no need to create other external resources.
At this point you are probably noticing a common theme: with CDK you reduce your burden by reducing the number of resource types you interact with. A higher level construct in CDK can be made up of multiple underlying resources such as security groups, IAM roles, autoscaling rules, etc. But you don’t have to define all these underlying bits by hand. They are automatic, and when you do want to interact with them you can do so via higher level interfaces.
As a user of CDK I can actually think of my architecture similarly to how I would diagram it:
I no longer have to interact with an entire collection of interconnected underlying resources and configurations. I can think of the architecture as three simple constructs: load balancer, service, and table. I can connect these constructs to each other with simple SDK methods.
This simplification benefits me no matter how simple or complicated my architecture is. Even an extremely simple application benefits from the higher level constructs of AWS CDK.
Misconception #4: If I use AWS CDK I’ll be “locked in”
This may be an oversimplification but fears of “lock in” are generally coming from a place of being afraid that if you adopt a tool you will eventually realize you made a horrible mistake, but by then it will too late and too difficult to switch. I don’t think this applies to AWS CDK.
First, CDK is a tool which generates lower level infrastructure as code. You can always choose to stop using CDK and just assume responsibility for the lower level infrastructure as code directly. For example if you are using CDK with CloudFormation it isn’t hard to grab the generated CloudFormation template and just start using that directly. In fact, if you aren’t ready to start using CDK full time it’s totally possible to use it as a tool just to generate the rough first draft outline of a CloudFormation template that you then assume control of and self manage from then on.
Second, AWS CDK works with a variety of different infrastructure as code providers, not just CloudFormation. You can use CDK for Terraform and CDK for Kubernetes.
The last point I want to mention here is that the severity of “lock in” largely has to do with the effort of replacement. In most cases the CDK code to generate your architecture is concise and easy to write. For example I created a demo application of a very complicated architecture for a web crawler application and you can see on Github that it came out to about 500 lines. Many application architectures will be even simpler: under 100 lines of code to define them. If you did decide to stop using CDK there isn’t much “sunk cost” in moving on. In most cases you are looking at discarding a few hundred lines of code that was easy to write, and thanks to CDK you already have a head start on the underlying CloudFormation, Terraform, or Kubernetes manifests that you would have had to hand craft anyway if you had never used CDK.
Misconception #5: AWS CDK looks too high level and abstracted for me
This can be a valid concern, but I don’t think that it means you shouldn’t use AWS CDK.
In my opinion the general trend in software development is towards abstraction, because it allows faster, easier, and more successful application development. While learning to code you probably studied the fundamentals of how to write your own in-memory data structures like a linked list, or a hash table. If you have taken a college course on computer science you probably even had to write some of these things from scratch. This is useful knowledge to have, but when it comes to day to day application development you don’t need to write your own linked list or hash table. Instead you use a built in primitive type in your programming language of choice, such as the JavaScript array and map types, or Python list and dictionary. As developers we do this because it is more efficient and safe. Eventually we barely even think of the underlying fundamentals of how a hash table works, we just use the equivalent data structure and it works.
The same thing applies to infrastructure constructs. It is possible to define your infrastructure from scratch by writing out all the underlying configuration, but it is more efficient and safe to use prebuilt patterns. When you do you can build faster, and be confident that the patterns you are using will work properly.
With CDK you have a lot of choice about what level you want to work at. CDK has constructs at multiple levels:
- Level 1: Constructs that are a one to one mapping to a single underlying resource type. For example there is the
CfnServiceresource that maps directly to the basicAWS::ECS::ServiceCloudFormation resource. - Level 2: More full featured constructs that package up multiple related resources behind a friendly interface. For example the
Ec2Serviceconstruct encompasses the security group and IAM role that the service will utilize, and has helper methods for attaching the service to load balancers and configuring autoscaling. - Level 3: Full patterns that connect multiple level two constructs together in common arrangements. For example the
ApplicationLoadBalancedEc2Serviceprovides a full stack for a web application: a load balancer already hooked up to an ECS service.
So no matter what level of abstraction you want to work at you can use AWS CDK to help you generate infrastructure as code. If you are a super experienced infrastructure engineer who wants the most control and you don’t see something in AWS CDK that fits your needs then you can use the lowest level abstractions and still benefit from CDK as a framework to create your own custom higher level abstractions. The abstractions you create can be reused, and most importantly they can be shared with others, allowing them to benefit from your expertise!
If you just want to build infrastructure for your applications quickly then you can use the highest level CDK abstractions out of the box as prebuilt building blocks that reduce your personal burden and allow you to focus on your application development goals.
Conclusion
I hope in this article I have explained AWS Cloud Development Kit in a way that makes sense. If I have helped you to understand AWS CDK better or if you have further questions please feel free to reach out to me on Bluesky: @nathanpeck.com
You can find the source files for the diagrams in this article below: