
How I do local Docker development for my AWS Fargate application
This is part four in an ongoing series on developing an application that runs in AWS Fargate:
- Deploying the initial application skeleton to AWS Fargate
- Making the application horizontally autoscale in AWS Fargate
- Building a continuous integration / deployment pipeline
In this article I’ll explore how to create a local development environment that lets me write code and test it in a container prior to using my CI/CD pipeline to deploy to the container to my production AWS Fargate environment.
Three popular approaches to local development
To get a broader understanding of the local development space I did an informal poll of the community to see what techniques other developers are using to develop Docker container based applications:
I noticed three popular approaches to solving the problem of local development:
1. Develop outside container, build container later
In this approach developers build and run the application directly on their development machine as if there was no container at all, and only do the docker build at the end to package up the app prior to shipping it to production.
This approach tends to work for organizations that are new to containers, and still educating their developers on how to work with them. Developers can use the same tools and build lifecycle that they always have. However, it does come with the drawback that there is a difference between the application development environment and the application runtime environment. Often the application runs just fine on the developers machine but not in the container, or vice versa. This can happen because of differences between development machines and the container environment, or even differences between different developers machines where one developer has version X of a critical tool or library while another developer has version Y.
By only using the Docker container as the final build product at the end, the organization will end up missing out on one of the core benefits of containers, which is ability to ensure that all developers and all production environments have a consistent environment.
2. Build and run once, use Docker volume to update locally
Here developers use docker build to create a container that has the core dependencies, but when they docker run they configure a Docker volume to mount a code directory from their development host into the container so they can do live modifications to the code without needing to rebuild or rerun the container.
This workflow is a decent midway point for an organization that had adopted containers, wants to keep a consistent runtime environment, but still has hasn’t fully optimized developer workflow for Docker containers. All developers will be able to run a consistent version of their application runtime engine and libraries. However, this approach does come with challenges for some languages.
For example when writing code in Node.js there are many modules which have binary components. In my sample AWS Fargate chat app I am using the package bcrypt for hashing passwords. Because password hashing is very CPU intensive I want the raw performance of a bcrypt implementation which is compiled from source into native machine code, instead of using a purely JavaScript implementation. However, if this package compiles on my Windows or Mac development machine it will not be compatible with the Linux runtime environment inside my container and I can’t use a Docker volume to just sync this package back and forth between Mac OS X and a Linux container.
3. Strict Docker development cycle
With this approach developers do docker build and docker run every single time they want to test the application, for strict consistency between local and remote experience. The build is completely containerized, such that all installation and compilation takes place inside the same container environment that runs in production.
This approach grants the most consistency and guarantees that builds are reproducible, reliable, and tested to function exactly as expected on production. However, there is need of significant optimization to make this workflow fast enough that it doesn’t slow down developers.
I’ve personally chosen the third, most strict approach for developing my sample AWS Fargate application. Let’s look at some ways to optimize this workflow to make it fast as well as reliable.
Optimizing build and run workflow
If my goal is to rebuild and rerun a Docker container every time I make a code change I need a few things:
- Very fast build
- Very small, lightweight container
- Very fast process startup
Fortunately all these things are obtainable by following 12 factor application best practices. I’ve already chosen Node.js for my runtime so I know that my processes should be able to restart fast, and because the Node.js runtime is small my containers should be quite light. I just need to optimize build times.
The Dockerfile
This file is what actually defines the Docker build, so lets look at the optimizations I’ve made here:
This Dockerfile is taking advantage of Docker build stages to both reduce the Docker image size, and reduce the Docker image build time. There are two stages:
- The first stage pulls in a full Node.js development environment, including NPM and build essential tools. It adds the
package.jsonfile to this build container, and then runsnpm install - The second stage uses a slim, stripped down version of the Node.js environment which just has the Node runtime and dependencies. It copies the previously built and installed packages from the first build stage, then adds the rest of the code.
The great thing about this approach is that it allows Docker to cache the build results from the first stage, so that the first stage doesn’t need to be rerun unless we have changed package.json
Here is what the build looks like if I change one of my code files without changing the dependencies:
As you can see in steps 1–6 there is a message that says “Using cache” indicating that those steps were reusing work done by a previous build. At the bottom the time for the container build was only one and a half seconds. The final product is a small, efficient container that has nothing but the slim version of the Node.js runtime environment, my code, and my dependencies.
Personally this is more than fast enough for me to use it regularly during my development lifecycle. I’m perfectly willing to completely rebuild the container every time I make a code change if it is that fast!
Using Docker Compose for a full local stack
Once I was confident that I could rebuild my container fast enough to have docker build a regular part of my development cycle it was time to look at the toolchain for running a full local copy of my application environment.
As I’ve expressed in previous articles my goal with this application’s architecture is to run and manage as little as possible. I want everything to be hands-off so I’m using AWS managed services:
- Amazon ElastiCache — I use ElastiCache for lightweight messaging between my processes, and ephemeral storage of online users. This is easy to replace when running locally because ElastiCache is just Redis, and I can run a Redis container locally.
- Amazon DynamoDB — This is the main database for everything my app persists. Fortunately AWS provides a local version of DynamoDB that you can run on your laptop. I just need to package DynamoDB local up as a container.
I chose to use Docker Compose to orchestrate launching these dependencies, my application, and my tests:
There are a few stages to this Docker Compose file so let’s explore them:
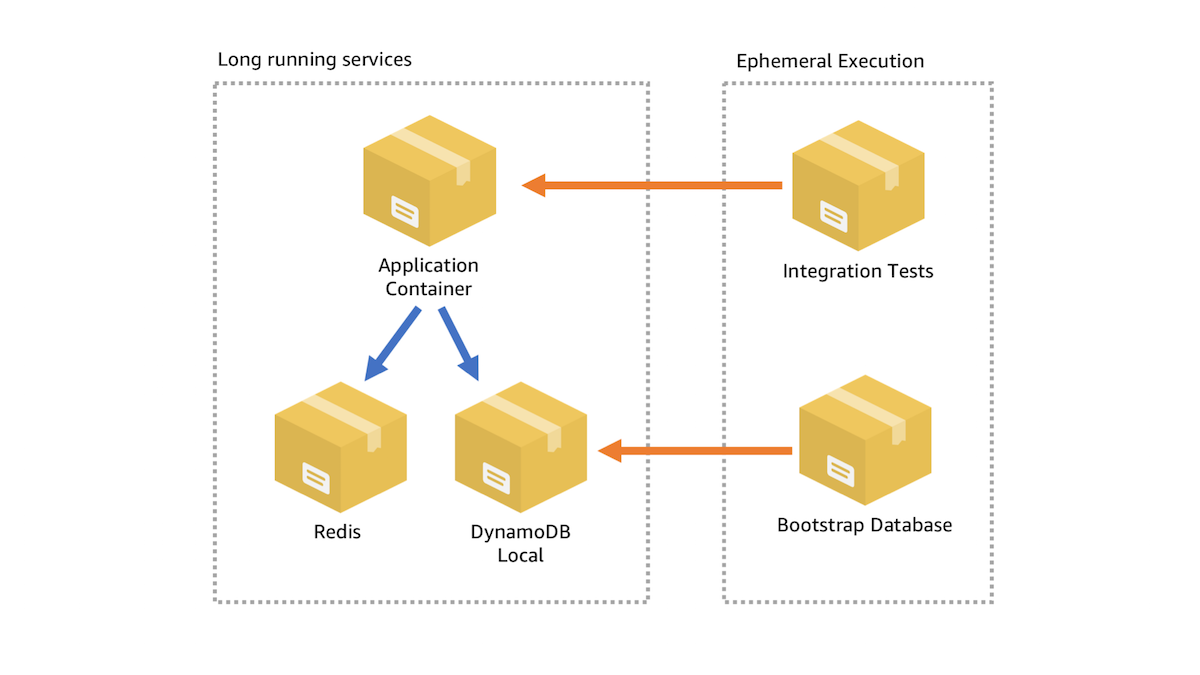
- First I launch
redisanddynamodb-localcontainers. Because these containers don’t depend on anything else Docker Compose is able to launch them quickly and efficiently in parallel. - Then I run an ephemeral container called
dynamodb-tableswhich handles setting up the database tables and schema in my dynamodb-local container. This is necessary for my application container to function as expected. - Then I launch the
clientcontainer which is hosting the actual application. - Finally I run an ephemeral container called
testwhich contains the integration tests that verify that the client container is functioning properly.
This is a map of the entire process that takes place end to end if the application has never been run locally on my machine, but I can actually optimize this process even further. For example if I’ve already launched the Docker Compose stack once, my redis and dynamodb-local containers are already running, and my DynamoDB table schema is already setup too, so all I have to do is rebuild and rerun the application container and the test container.
Using make to automate common workflow tasks
I like to use make to manage all my local build commands. Not only is this tool already present on pretty much every developer machine ever, but its also extremely no frills, making it easy to write (and read) a Makefile for your particular workflow.
Here is the Makefile I use in my project to let me either build and deploy the entire stack, or rebuild and rerun a portion of it very quickly:
I have three easy-to-use commands for my local development environment:
make runwill launch the entire local stack, including all the container dependencies that my application needs to run fully offline locally.make buildwill just rebuild and rerun my client application, so that I can view the results locally in my browser.make testwill rebuild and rerun both the client and test containers, so that I can do test driven development.
Now let’s take a look at the timing. For the first run of make test I get a timing of:
real 0m23.957s
user 0m1.773s
sys 0m0.576s
It takes roughly 20 seconds to do a fresh rebuild of my containers, pull in all my dependencies from NPM to install in my containers, and get those containers setup locally.
But the next time I run make test it is much faster because all the NPM dependencies are cached, and the two stage Docker build allows me to avoid all that time that would otherwise have been spent on NPM install:
real 0m5.953s
user 0m1.736s
sys 0m0.543s
The basic integration test suite that I have setup to run locally as part of my development process takes 354ms to complete once the containers have started:
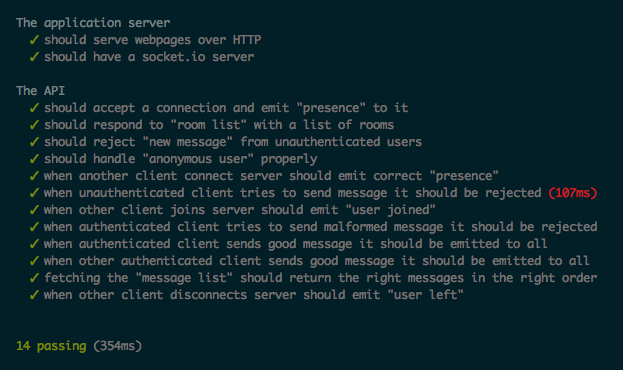
So this means that rebuilding and restarting the Docker container only adds about five seconds to the process. As the application gets larger and more complicated this five second overhead will stay roughly the same provided that I continue to use optimized build stages. Since most large applications have massive integration test suites that can take 1–2 mins to complete the extra five seconds is barely noticeable.
Conclusion
The great thing about containers is that you can use them both locally as well as for deployment to the cloud. With my chosen workflow I feel confident that the same container that I build and run locally will work properly when I ship it to AWS Fargate to run in the cloud. Additionally since my integration tests also run as a container which connects to my application container I can also easily run these tests as part of a CodeBuild stage in the CodePipeline that I use for deploying the application to my production environment.
If you are interested in trying out this local development workflow feel free to clone my open source repository and try it out yourself. The repo includes instructions for running locally, as well as for automatically deploying to AWS Fargate in your own AWS account: